Caches are memory locations that can be accessed in less time than others.
CPU caches are typically located on the same chip or on a chip (usually closer to the CPU) that can be accessed much faster than ordinary memory
caches use more performing but also more expensive technology, so they are typically smaller
The main issue with caches is: since they’re smaller (thus we can’t put everything in them), what should we store in them?
The answer relies on the assumption of locality (programs don’t access memory randomly, but in reliable patterns)
spatial locality ⟶ if you access a specific memory location, you are highly likely to access a nearby location soon
temporal locality ⟶ if you access a memory location now, you are highly likely to access that same location again (ore one close by) in the near future
For these reasons, data is transferred from memory to cache in blocks or lines (i.e. when z[0] is transferred, so will be z[1], z[2], …, z[15])
doing one transfer of 16 memory locations is better than doing 16 transfers of one - when accessing z[0], one will have to wait for the transfer, but the other 15 elements will already be there for the future
Caches are organised by speed in levels. L1 is the smallest and the fastest, L3 is the largest and slowest.
the CPU first checks if the data is in L1, if not, in L2, etc…
A cache hit happens when data is found, a miss when it isn’t. If all of the caches miss, the CPU will get the data from main memory and move it to the cache.
When a CPU writes data to a cache, the value in the cache might be inconsistent with the value in main memory.
Caches handle this with one of these two strategies:
write-through ⟶ they update the data in the main memory at every write in the cache
write-back ⟶ when a change happens, the data in the cache is marked as dirty - when a cache line is replaced by a new one, the dirty line is written to memory
why do we care
To write efficient parallel code, its sequential parts must be efficient.
Caching on multicores
In multicore systems, each core is in possession of a L1 cache, while L2 and L3 caches might be shared amongst threads. The programmer has no control over caches and when they get updated, and the inconsistency problem becomes more serious, as a variable needs to be consistent across caches for all of the cores.
example
There are two ways to keep the cache coherent:
Snooping Cache Coherence ⟶ the cores share a bus
any signal transmitted on the bus can be “seen” by all cores connected to it
when a core updates its copy of a variable, it broadcasts this information across the bus
if another core is “snooping” on the bus, it will be notified and mark its copy as invalid
con: very expensive
Directory Based Cache Coherence ⟶ uses a data structure called directory that stores the status of each cache line
when a variable is updated, the directory is consulted and the cache controllers of the cores that have that variable’s line cached invalidate it
False sharing
False sharing is a common issue in multicore architectures. It arises when two or more threads access data that, while being different, is on the same cache line (causing an invalidation, even though the threads are accessing different values).
The main strategies to fix this issue are:
padding ⟶ adding “empty” bytes to data so that it starts on a new cache line
the cache lines’ dimension needs to be known (can be obtained in the code via sysconf(_SC_LEVEL1_DCACHE_LINESIZE)
padding example
double x[N];#pragma omp parallel for schedule(static, 1) for( int i = 0; i < N; i++ ) x[ i ] = someFunc( x [ i ] );
double x[N][8];#pragma omp parallel for schedule(static, 1) for( int i = 0; i < N; i++ ) x[ i ][ 0 ] = someFunc( x [ i ][ 0 ] );
this approach modifies the data structure to physically force elements apart (instead of a 1D array, a 2D array with 8-element rows is used) (this way, two variables are exactly 64 bytes apart)
this approach wastes memory, and kills cache effectiveness (goes against locality, a 64-byte line is pulled in but only 8 bytes are used)
example: spacing with structs
// assuming 64-byte linestruct alignTo64ByteCacheLine { int __onCacheLine1 __attribute__((aligned(64))) int __onCacheLine2 __attribute__((aligned(64)))}
the aligned directive tells the GCC compiler that the memory address for that variable has to be a multiple of 64 (so, for example, they will be placed at 0 and 64)
changing the mapping of data to threads or cores
example
double x[N];#pragma omp parallel for schedule(static, 8) for( int i = 0; i < N; i++ ) x[ i ] = someFunc( x [ i ] );
threads take “chunks” of 8 iterations at a time (by giving thread 0 the indices 0–7, thread 0 gains exclusive ownership of the entire first cache line, while thread 2 owns the second cache line)
this approach is better than padding, as it doesn’t waste memory and uses caches correctly
using private/local variables
this is a good approach, but it wouldn’t work for indexes in a loop - it is more suited, for example, for when threads are “fighting” over a single shared variable (ex. a reduction to a sum)
Memory Organization
There are two ways that memory can be organised in multicore systems:
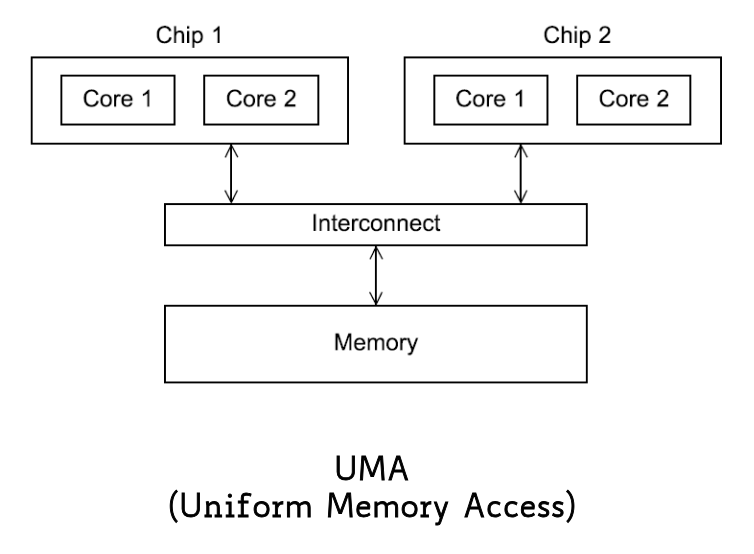
Uniform Memory Access
In a UMA system, all of the processors have direct access to memory. This means that any processor can access any data in memory at the same time and with the same speed, independently from where the data is physically located.
programmers don’t have to handle memory access in a complex way (since all processors “see” the same memory)
the single shared bus/interconnect is a chokepoint - as you add cores, they fight for bandwidth (so, this approach is not very common in systems with too many cores)
(as far as caches are concerned, UMA typically uses bus snooping)
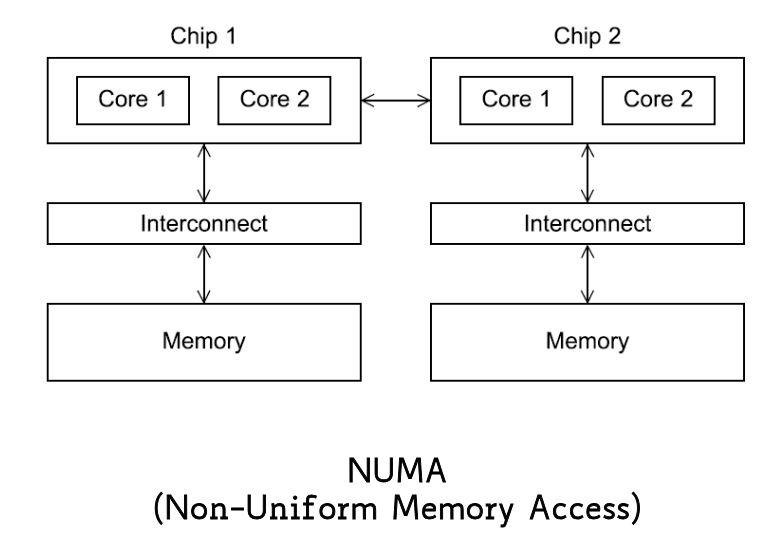
Non-Uniform Memory Access
In NUMA systems, cores are partitioned in “groups”, and each group has a distinct main memory, which is disconnected from the others. The division is transparent to the programmer (as, functionally, memory is seen as one unit).
the nodes are connected via a high speed interconnection, which allows the processors to access other nodes’ memory
accessing “local” memory is cheaper (faster) than accessing a “remote” memory
It is possible to specify where the data must be allocated with the numa.h library.
(as far as caches are concerned, UMA typically uses directory-based coherence)