grafo pesato
Un grafo è detto pesato se ad ogni arco è associato un valore numerico (detto peso) (funzione associa ad ogni arco un peso).
- il peso di un cammino è dato dalla somma dei pesi degli archi che lo costituiscono
Per rappresentare un grafo pesato tramite lista di adiacenza, per l’arco di peso nella lista di adiacenza di , invece che il solo nodo di destinazione , ci sarà la coppia .
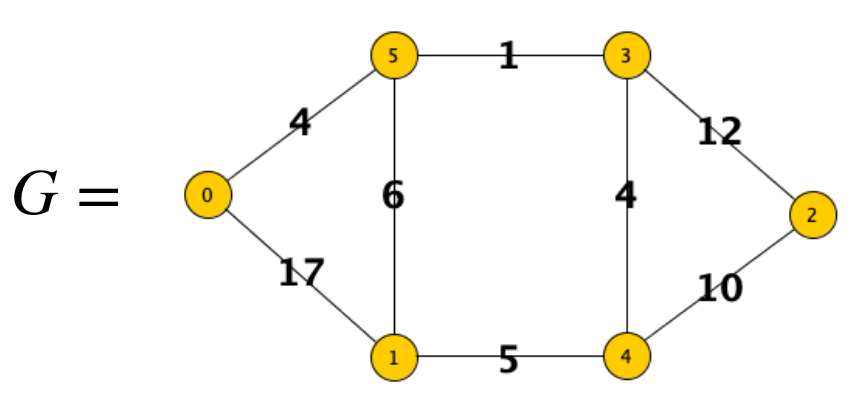
il grafo sopra avrà lista di adiacenza:
G = [
[(1, 17), (5, 4)],
[(0, 17), (4, 5), (5, 6)],
[(3, 12), (4, 10)],
[(2, 12), (4, 4), (5, 1)],
[(1, 5), (2, 10), (3, 4)],
[(0, 4), (1, 6), (3, 1)]
]analogia dei contenitori d'acqua
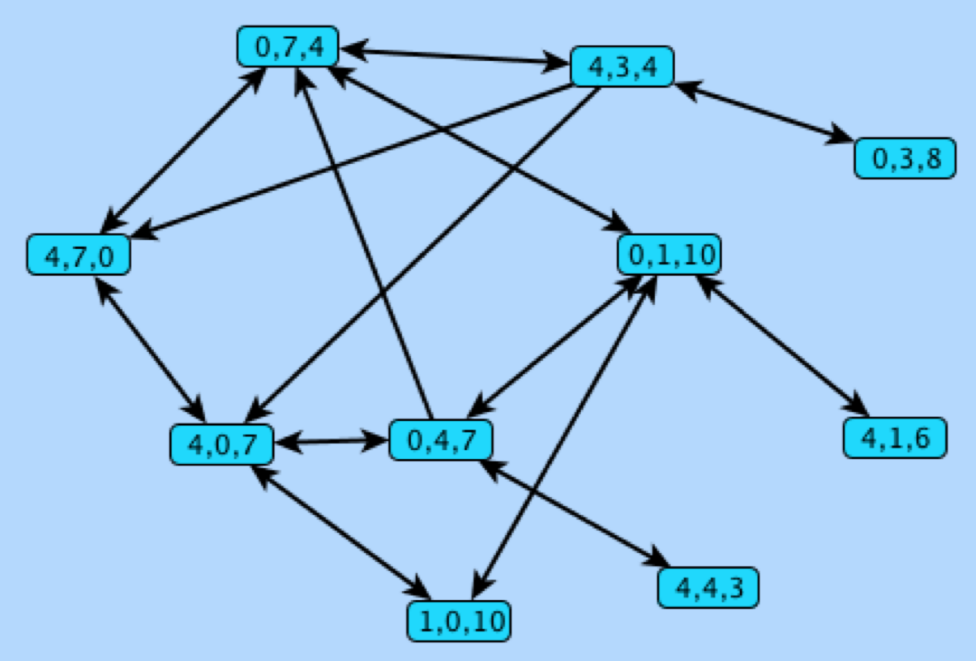
Abbiamo tre contenitori d’acqua con capienza 4, 7 e 10 litri. Inizialmente, i contenitori da 4 e 7 litri sono pieni, mentre quello da 10 è vuoto. Possiamo fare un solo tipo di operazione: versare acqua da un contenitore ad un altro, fermandoci quando il contenitore sorgente è vuoto o quello destinazione pieno.
Vogliamo sapere se esiste una sequenza di operazioni di versamento che termina lasciando esattamente 2L di acqua nel contenitore da 4 o nel contenitore da 7.
Il problema si può modellare con un grafo :
- i nodi di rappresentano i possibili stati di riempimento dei contenitori (tramite una configurazione dove le tre lettere rappresentano il numero di litri nei tre contenitori)
- c’è un arco tra un nodo a un nodo se dallo stato è possibile passare allo stato con un versamento lecito
Per risolvere il problema, basta chiedersi se nel grafo diretto almeno uno dei nodi o è raggiungibile a partire dal nodo .
- per facilitare la ricerca, possiamo aggiungere un nodo pozzo con archi entranti solo dai nodi e , e chiederci se questo sia raggiungibile da
- per raggiungere uno dei due target con il minimo numero di travasi ci basta effettuare una visita BFS per la ricerca dei cammini minimi, calcolando le distanze minime a partire da ()
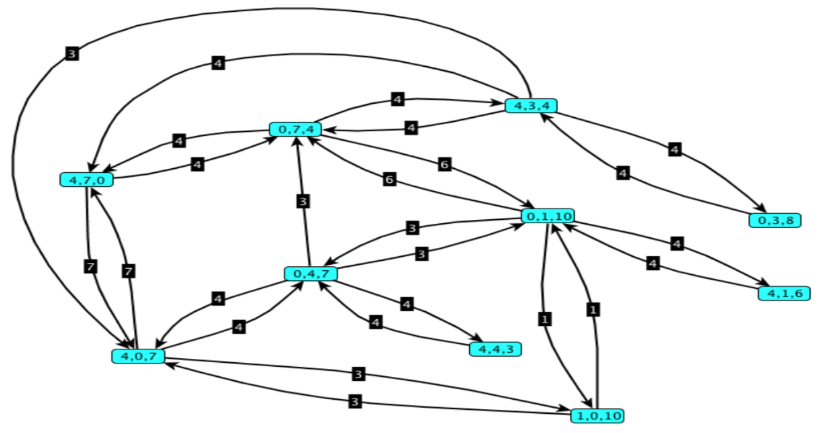
Consideriamo però questa variante del problema: consideriamo una sequenza di operazioni di versamento come buona se termina lasciando esattamente 2 litri in uno dei due contenitori. Inoltre, una sequenza buona è parsimoniosa se il totale dei litri versati in tutti i versamenti della sequenza è minimo rispetto a tutte le sequenze buone. Cerchiamo una sequenza buona e parsimoniosa.
Ci conviene aggiungere un costo ad ogni arco per rappresentare il numero di litri che vengono versati nella mossa corrispondente.
Trovare un cammino dal nodo al pozzo che minimizzi la somma dei costi degli archi attraversati diventa una generalizzazione del problema dei cammini di lunghezza minima.
Possiamo infatti sostituire un arco da a di costo con un cammino con nuovi nodi - in questo modo, ogni arco corrisponde al versamento di 1L d’acqua, e contando gli archi di un cammino tra due nodi contiamo esattamente il numero di litri versati. Basta quindi eseguire una BFS nel nuovo grafo. Essa avrà complessità con e nodi e archi del nuovo grafo.
Abbiamo ricondotto un problema di cammini minimi su grafi pesati ad uno di cammini minimi in un grafo non pesato. Ma questo approccio è possibile solo quando gli archi hanno pesi interi e relativamente piccoli.
Esiste quindi un algoritmo che ci permette di risolvere il problema dei cammini minimi lavorando direttamente su grafi pesati.
algoritmo di Dijkstra
problema:
Dato un grafo pesato, vogliamo trovare i cammini minimi, e quindi anche le distanze da un nodo (sorgente) a tutti gli altri nodi del grafo.
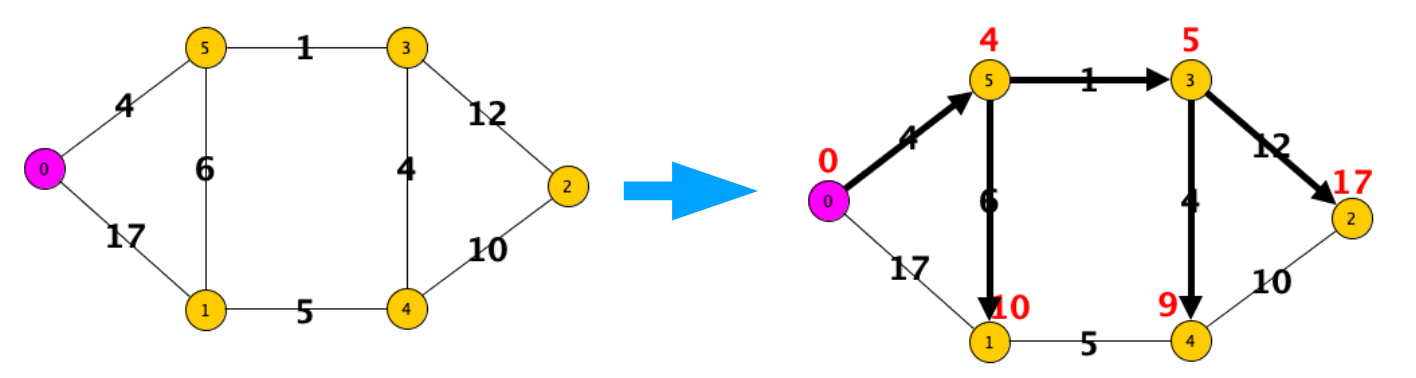
(^ cammini minimi dalla sorgente a tutti gli altri nodi)
L’algoritmo di Dijkstra costruisce l’albero dei cammini minimi un arco per volta partendo dal nodo sorgente, e segue questa logica:
- ad ogni passo, aggiunge all’albero l’arco che produce il nuovo cammino più economico
- assegna ad ogni nodo come distanza il costo del cammino (che dalla radice porta ad esso)
L’algoritmo rientra nel paradigma della tecnica greedy. Opera infatti secondo una sequenza di decisioni irrevocabili:
- il cammino dal nodo sorgente ad un nuovo nodo viene deicso ad ogni passo, senza più tornare sulla decisione
- le decisioni vengono prese in base ad un criterio locale: tra tutti i cammini percorribili, si sceglie quello che costa meno
implementazioni
È impossibile risolvere il problema in meno di . Esistono tre implementazioni principali:
- una senza strutture dati, in : è ottima nel caso dei grafi densi (in cui ), ma non nel caso di grafi sparsi ()
- una che utilizza la Heap, in : funziona meglio nel caso di grafi sparsi, ma nel caso di un grafo denso è preferibile la prima
- una terza, che utilizza la Heap di Fibonacci, in : la migliore in entrambi i casi (ma non trattata)
pseudocodice:
P[0...n-1]vettore dei padri inizializzato a-1D[0...n-1]vettore delle distanze inizializzato a+inf(perché si utilizzerà la funzionemin())D[s], P[s] = 0, s(la sorgente ha distanza zero da se stessa ed è padre di se stessa)while esistono archi (x,y) con P[x]!=-1 e P[y]==-1:- sia
(x,y)quello per cui è minimoD[x] + peso(x,y) D[y], P[y] = D[x] + peso(x,y), x(si sceglie il cammino, quindi la distanza del nuovo nodo sarà data dalla distanza del padre + il peso dell’arco, e il padre del nuovo nodo sarà il nodo corrente)
- sia
attenzione: l'algoritmo non è corretto nel caso di grafi con pesi anche negativi
Infatti, poiché sceglie il cammino meno costoso ad ogni passo, non considera il caso in cui si percorrerà prima un arco con peso maggiore per poi incontrare archi con pesi negativi (che abbasseranno quindi il costo totale).
- in caso di pesi negativi, si usa l’algoritmo di Bellman-Ford
prova di correttezza
dimostrazione
Si dimostra per induzione sul numero di iterazioni del
while(che assegna una nuova distanza ad un nodo).Dobbiamo dimostrare che la distanza assegnata è quella minima.
- caso base: al passo zero viene assegnata distanza zero alla sorgente (e, poiché non consideriamo il caso di pesi negativi, non c’è una distanza minore)
- ipotesi induttiva: assumiamo che i cammini costruiti fino al passo siano minimi
Sia l’albero dei cammini minimi costruito fino al passo e l’arco aggiunto al passo . Per dimostrare che è la distanza minima, basta mostrare che il costo di un eventuale cammino alternativo è sempre superiore o uguale a .
Sia un qualsiasi cammino alternativo a quello presente nell’albero e il primo arco che incontriamo percorrendo all’indietro tale che è nell’albero e no (ovvero l’ultimo arco percorso dal cammino).
- per ipotesi induttiva (e poiché non consideriamo archi con pesi negativi)
Ma l’algoritmo ha scelto invece che , quindi, in base alla regola con cui esso sceglie l’arco con cui estendere l’albero, si ha necessariamente .
- da qui segue
Il cammino alternativo ha quindi un costo superiore a .
implementazione tramite lista
Si può mantenere una lista in cui, per ogni nodo viene memorizzata una tripla , in cui:
- definitivo ⇒ flag che assume valore se il costo per raggiungere è stato definitivamente stabilito (ovvero se l’algoritmo ha stabilito che non esiste un percorso migliore per arrivare al nodo )
- costo ⇒ costo corrente minimo noto per raggiungere dalla sorgente
- all’inizio, viene inizializzato a per e a per tutti gli altri nodi
- origine ⇒ nodo “padre” lungo il cammino minimo dalla sorgente a
- inizializzato a
All’inizio, l’unico nodo dell’albero è la sorgente, quindi la lista è inizializzata così:
Seguono una serie di iterazioni dove vengono eseguiti questi passaggi:
- selezione del nodo con costo minimo non definitivo: si scorre per individuare il nodo che non è ancora definitivo e che ha il costo corrente minimo ⇒ è il candidato per il quale il cammino minimo dalla sorgente è attualmente noto
- verifica di terminazione: se il costo minimo trovato è , significa che non esistono altri nodi raggiungibili non definitivi. Il ciclo si interrompe.
- marcare come definitivo: la flag del nodo selezionato viene aggiornata a (il suo costo definitivo è stato fissato e non sarà più modificato)
- aggiornamento dei vicini di : per ogni nodo adiacente a , se non è ancora definitivo e il nuovo costo ottenuto passando per esso (ovvero ) è inferiore o uguale al costo attuale memorizzato per , si aggiorna la terna di
def dijkstra(s, G):
n = len(G)
Lista = [(0, float('inf'), -1)]*n
Lista[s] = (1, 0, s)
for y, costo in G[s]:
# aggiorno vicini di s
Lista[y] = (0, costo, s)
while True:
minimo, x = float('inf'), -1
# cerco il nodo non definitivo con costo minimo
# considerati solo i vicini, gli altri avranno inf
for i in range(n):
if Lista[i][0] == 0 and Lista[i][1] < minimo:
minimo, x = Lista[i][1], i
if minimo == float('inf'):
# non ci sono più nodi raggiunbili non definitivi
break
# rendo definitivo il nodo x
definitivo, costo_x, origine = Lista[x]
Lista[x] = (1, costo_x, origine)
# aggiornamento vicini
for y, costo_arco in G[x]:
# se y non è definitivo e c'è un cammino migliore passando per x
if Lista[y][0] == 0 and minimo + costo_arco < Lista[y][1]:
Lista[y] = (0, minimo + costo_arco, x)
# estrae vettori delle distanze e dei padri
D,P = [costo for _,costo,_ in Lista], [origine for _,_,origine in Lista]
return D, P- il costo delle istruzioni al di fuori del
whileè . - il
whileviene eseguito al più volte (ad ogni iterazione un nuovo nodo viene selezionato e reso definitivo). Al suo interno:- il primo
forviene eseguito esattamente volte - il secondo
forviene eseguito al più volte (tante quanti sono gli adiacenti)
- il primo
Il costo del while è quindi , che è anche la complessità dell’implementazione.
[ TODO: inserire passaggi esempio ]
implementazione con Heap
Questa implementazione si basa sull’intuizione per cui, se si evitasse di scorrere ogni volta il vettore per trovare il minimo, si eviterebbe di pagare ad ogni iterazione del while.
- si può quindi sostituire con una Heap, che ha complessità per l’estrazione del minimo e per l’inserimento
Manteniamo un heap minimo contenente triple , dove è un nodo già inserito nell’albero dei cammini minimi e rappresenta la distanza che si avrebbe qualora il nodo venisse inserito nell’albero dei cammini minimi attraverso .
- ogni volta che aggiungiamo un nodo all’albero, aggiorniamo anche l’heap inserendo, per ogni vicino di , una nuova tripla
- dato che non rimuoviamo elementi già presenti nell’heap, possono esistere più entry dello stesso nodo con distanze differenti. Tuttavia, sappiamo che la prima volta che un nodo viene estratto, questa corrisponde alla distanza minnima calcolata fino a quel punto (quindi le successive estrazioni possono essere trascurate).
- quindi, ad ogni estrazione di un nodo controlliamo prima se esso è già stato aggiunto all’albero (e, in tal caso, ignoriamo l’estrazione)
from heapq import heappush, heappop
def dijkstra1(s, G):
n = len(G)
D = [float('inf')]*n
P = [-1]*n
D[s] = 0
P[s] = s
H = [] # min-heap
# inizializzazione heap (con vicini di s)
for y, costo in G[s]:
heappush(H, (costo, s, y))
while H:
# estraggo il nodo con distanza minore
costo, x, y = heappop(H)
if P[y] == -1:
P[y] = x
D[y] = costo
for v, peso in G[y]:
if P[v] == -1:
heappush(H, (D[y]+peso, y, v))
return D, PNella heap ci possono essere anche elementi, quindi i costi di inserimento ed estrazione saranno .
- l’inizializzazione di e costa , e l’inserimento dei vicini di costa .
il costo del while con al suo interno un for è dato invece da:
- ad ogni iterazione del
whilesi elimina un elemento da e, eventualmente, tramite ilforannidato si scorre la lista di adiacenza di un nodo e si aggiungono elementi ad . Ogni lista di adiacenza può essere scorsa al più una volta, quindi ad possono essere aggiunti al massimo elementi. Il numero di iterazioni del while è quindi . - escludendo il
forannidato, il costo di ciascuna iterazione del while è a causa dell’estrazione da - quindi, senza ilfor, ilwhilecosterebbe . - Il
forscorre la lista di adiacenza di un nodo . Tuttavia, ogni arco viene esaminato una sola volta in tutto l’algoritmo (quando il nodo viene estratto da ). Per ogni arco esaminato nelfor, può essere eseguita un’operazione di inserimento in , che ha costo . Poiché in totale ci sono archi, il numero complessivo di operazioni di inserimento in è al massimo , e quindi il costo totale delfornell’intero algoritmo è
La complessità di questa operazione è quindi