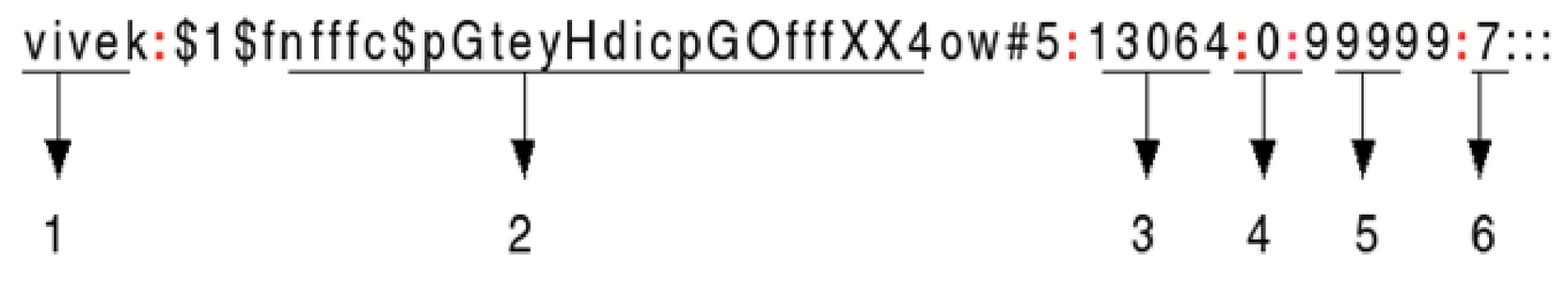hash: hash della password, calcolato con l’algoritmo e il salt
funzione hash
Una funzione hash trasforma un input di lunghezza variabile in output di lunghezza fissa in maniera deterministica.
funzione hash crittografica
Una funziona hash è detta crittografica se:
È computazionalmente difficile calcolare l’inverso della funzione hash
È computazionalmente difficile, dato un input x ed il suo hash d, trovare un altro inputy che abbia lo stesso hashd
È computazionalmente difficile trovere due input diversi di lunghezza arbitraria x e y che abbiano lo stesso hashd
perché non cifrare direttamente la password?
se si usa cifratura ed un attaccante ottiene la chiave, potrebbe decifrare ed ottenere tutte le password in plaintext
le funzioni hash sono one-way
se un attaccante ottiene l’hash, sarà più difficile scoprire la password che l’ha generato
è comunque semplice verificare se una password corrisponde a quella salvata in formato hash: basta fare l’hash della password e verificarne l’equivalenza (hashing ́e deterministico)
attacchi a password
Gli hashing delle password restano comunque attaccabili.
Gli attacchi più comuni sono di due tipi:
attacco dizionario
rainbow table
attacco dizionario
Sfrutta la pigrizia degli utenti nello scegliere password brevi e semplici, e nel riutilizzare molte volte la stessa password per servizi diversi.
Si compila una lista di password comunemente utilizzate e si effettua un attacco bruteforce:
per ogni password nella lista, si calcola l’hash finché esso non corrisponde
pros and cons
vantaggi:
molto semplice da effettuare (richiede solo una lista di password)
versatile: fuziona per qualsiasi funzione hash
ci sono molti tool che aiutano ad automatizzare il tutto
svantaggi:
può essere molto lento (richiede la computazione in real time dell’hash)
la password può non essere presente nel dizionario
attacco rainbow table
Sfrutta il fatto che le funzioni hash sono deterministiche.
Si pre-computano tutti gli hash e si crea un dizionario (rainbow table) di coppie hash-plaintext password.
il dizionario viene creato offline e riutilizzato per diversi attacchi
in realtà, utilizza un sistema più complesso di funzioni di riduzione per mantenere trattabili le dimensioni della tabella, noi semplifichiamo
pros and cons
vantaggi:
molto semplice da effettuare (la rainbow table è precompilata)
molto più veloce del dizionario
svantaggi:
rigidità: funziona solo per la funzione hash per la quale è stata creata la rainbow table (bisogna creare più rainbow table per più funzioni)
fermato dal salt !
salt (salvati dal sale)
Il salt è un valore randomico, generato quando un utente sceglie la password, che viene aggiunto alla computazione dell’hash.
Il salt viene poi salvato in chiaro insieme all’hash calcolato.
Il salt rende impossibile l’uso delle rainbow tables: se per ogni utente c’è un salt randomico diverso, non posso precomputare gli hash.
In più, fa sì che due utenti diversi con la stessa password abbiano due hash diversi (molto probabilmente i loro salt saranno diversi).
buffer overflow
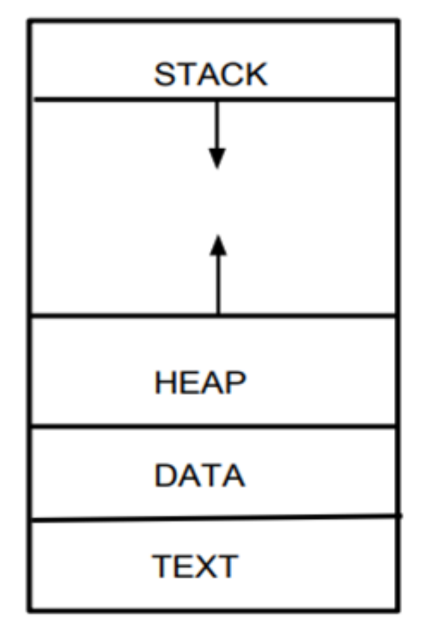
L’area di memoria di un processo caricato in memoria è divisa in:
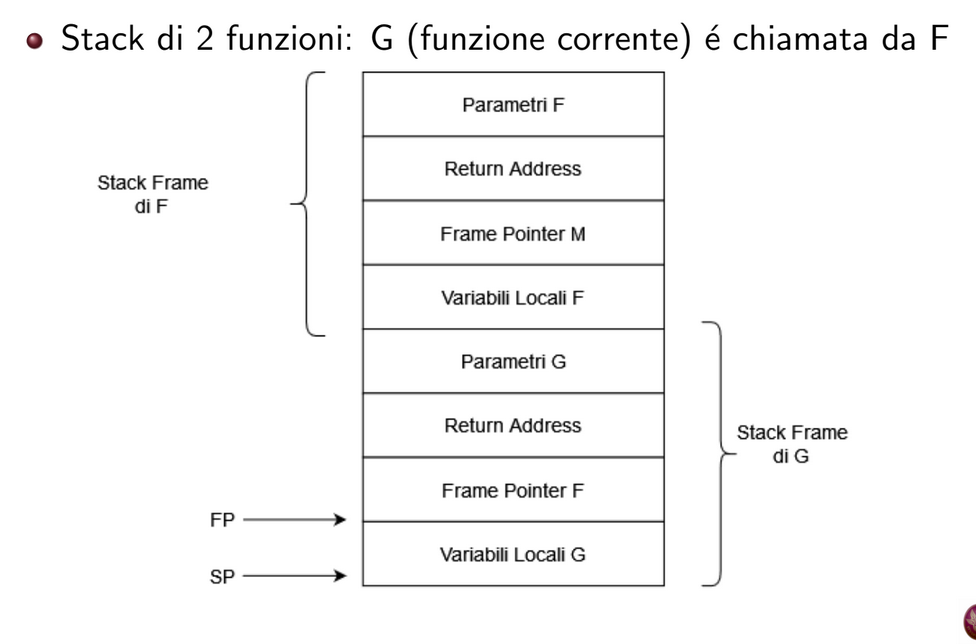
Lo stack è costituito da stack frames.
Ciascuno stack frame contiene: parametri passati alla funzione, variabili locali, indirizzo di ritorno e instruction pointer.
in particolare, una chiamata di funzione prosegue in questo modo:
se ci sono parametri passati alla funzione, sono aggiunti allo stack
l’indirizzo di ritorno (return address) è aggiunto allo stack
il puntatore allo stack frame viene salvato sullo stack
viene allocato spazio ulteriore sullo stack per le variabili locali della funzione chiamata
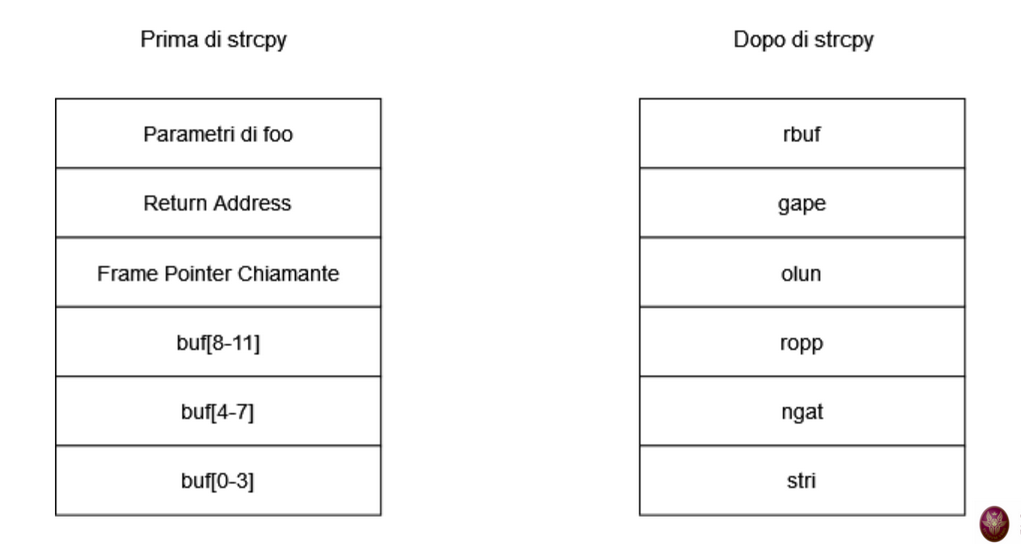
In questo esempio, stiamo inserendo troppi dati rispetto alla dimensione del buffer, ma il computer (che non sa effettivamente quando il buffer finisca) continua a sovrascrivere tutti gli indirizzi di memoria che trova fino al completamento dell’operazione.
Quindi, dopo questa operazione, lo stack si troverebbe circa in questa situazione:
Questo tipo di overflow porta generalmente alla terminazione di un programma per segmentation fault. Ma, se i dati inseriti nell’overflow sono preparati in modo accurato, è possibile per esempio modificare l’indirizzo di ritorno arbitrariamente, ed eseguire codice arbitrario.
Ci sono quattro modi principali per farlo:
shellcode
return-to-libc
stack frame replacement (solo nominato)
return-oriented programming (solo nominato)
shellcode
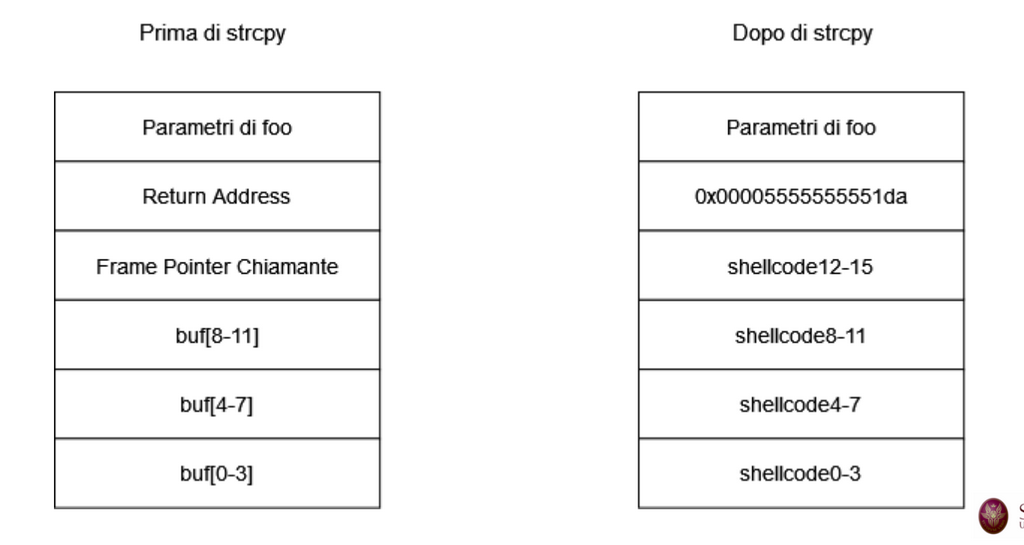
Lo shellcode è un piccolo (deve rientrare nelle dimensioni del buffer) pezzo di codice che viene eseguito quando si sfrutta una vulnerabilità per attaccare un sistema. Tipicamente, avvia una command shell da cui l’attaccante può prendere il controllo della macchina.
l’idea alla base è quindi inserire codice eseguibile nel buffer, e cambiare il return address con l’indirizzo del buffer.
esempio
Se per esempio buf ha indirizzo 0x00005555555551da, un attacco potrebbe essere:
Una volta completata la chiamata a foo(), il processore salterà all’indirizzo 0x00005555555551da ed eseguirà lo shellcode
return-to-libc
Non è sempre possibile inserire shellcode arbitrario nel buffer, ma esiste codice utile ad attacchi sempre presente in RAM e raggiungibile dai processi: le librerie dinamiche e di sistema.
invece di usare shellcode, si può inserire come indirizzo di ritorno una funzione di sistema utile per l’attacco
esempio
Per esempio, assumendo di conoscere l’indirizzo di system(), un attacco potrebbe essere:
void foo(char *s) { char buf[10]; strcpy(buf, s); printf("buf is %s\n", s);}foo("AAAAAAAAAAAAAAAA<\indirizzo di system>AAAA'bin/sh'");
Dopo la chiamata a foo, il processore salterà quindi a system() e ne seguirà i codice usando come parametro bin/sh
contromisure
Le contromisure che si possono prendere si dividono in quelle attuabili a tempo di compilazione, e quelle attuabili a tempo di esecuzione.
a tempo di compilazione
utilizzo di linguaggi di programmazione e di funzioni sicuri (l’overflow è possibile solo perché C utilizza funzioni che spostano dati senza limiti di dimensione).
stack smashing protection:
il compilatore inserisce del codice per generare un valore casuale (chiamato canary) a runtime, che viene inserito tra il frame pointer e l’indirizzo di ritorno.
se il canary viene modificato prima che la funzione ritorni, vuol dire che è stato sovrascritto da un possibile attacco e l’esecuzione viene interrotta.
a tempo di esecuzione
executable space protection
il Sistema Operativo marca pagine/segmenti dello stack e heap come non eseguibili
se un attaccante cerca di eseguire codice nello stack, il sistema termina il processo con un errore
(return-to-libc funziona comunque)
address space layout randomization
ad ogni esecuzione si randomizzano gli indirizzi dove sono caricati i diversi segmenti di un programma (stack, heap ecc)
è molto più difficile indovinare l’indirizzo del buffer contenente lo shellcode e anche quello delle librerie se non si sa dove inizia lo stack