struttura del disco:
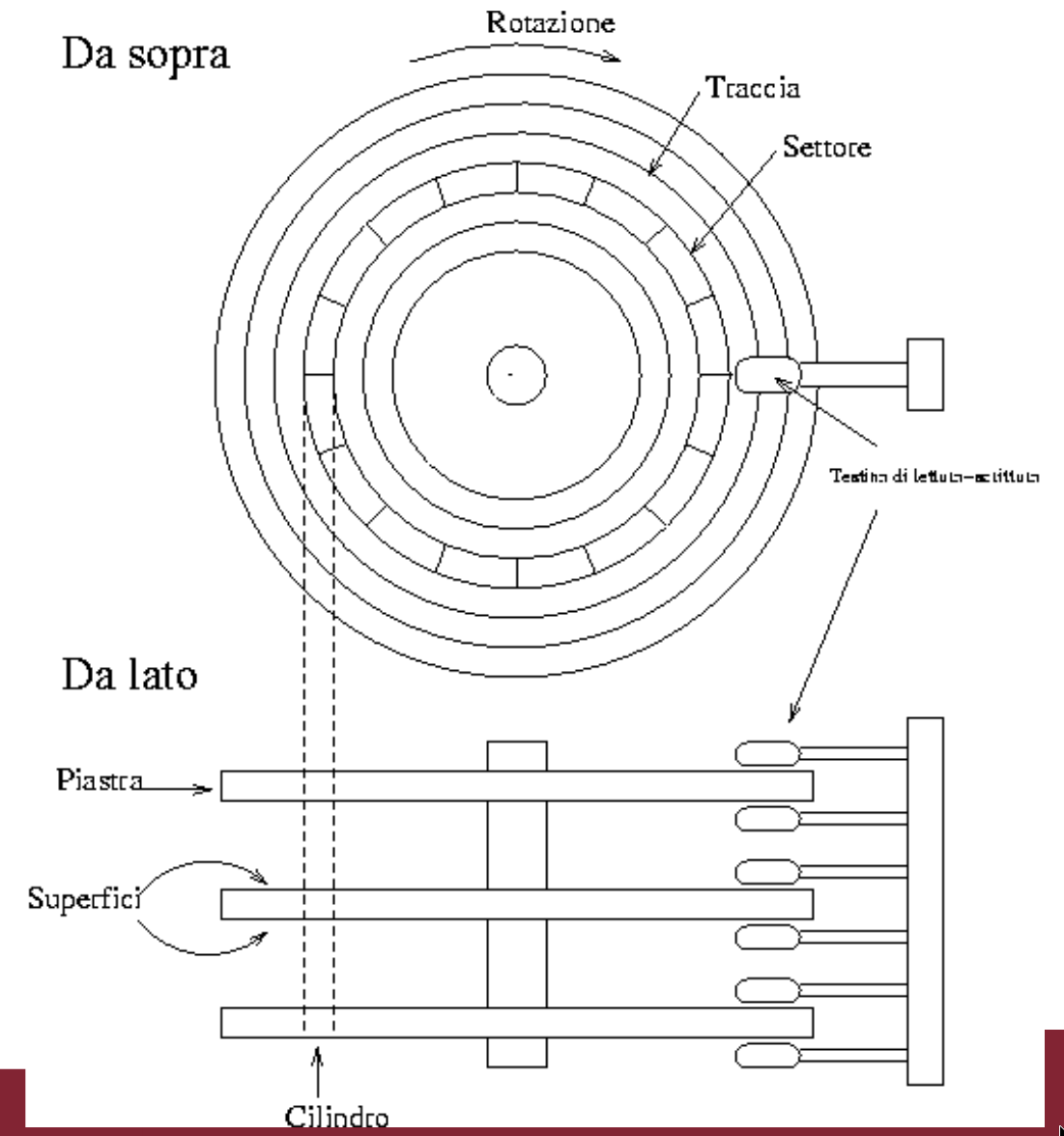
Al momento della formattazione del disco, ogni traccia è suddivisa in blocchi (o pagine) di dimensione fissa.
- per accesso, si intende il trasferimento di un blocco da memoria secondaria a principale (lettura) o da principale a secondaria (scrittura)
Il tempo necessario per un accesso è dato dalla somma di:
- tempo di posizionamento (della testina sulla traccia giusta)
- ritardo di rotazione (rotazione necessaria per posizionare la testina ad inizio blocco)
- tempo di trasferimento
Il costo di un’operazione su una base di dati è definito in termini di numero di accessi.
terminologia/utili
- è importante il concetto di blocco - è l’unità sia di allocazione che di trasferimento
- ad ogni relazione (tabella) corrisponde un file (insieme omogeneo di record)
- ad ogni attributo corrisponde un campo
- ad ogni tupla (ricordiamo: riga di una tabella) corrisponde un record
in ogni file ci sono record appartenenti ad un’unica relazione
- il “file principale” è composto dai blocchi che contengono i record della nostra tabella
noi faremo due assunzioni:
- un blocco deve essere allocato completamente per un certo file (non posso allocare frazioni di blocco) (e in un blocco ci sono solo record dello stesso file)
- in un blocco si può memorizzare solo il numero intero di record che ci entrano (un record non può essere diviso tra diversi blocchi)
record
In un record, oltre ai campi che corrispondono agli attributi, possiamo trovare anche un puntatore ad altri record/blocchi o informazioni sul record.
Nello specifico, alcuni byte all’inizio del record possono essere usati per:
- specificare il tipo di record (serve in casi reali ma non in quelli che tratteremo, in cui vale l’assunzione per cui in uno stesso blocco sono allocati solo record dello stesso file)
- specificare la lunghezza del record (se ha campi a lunghezza variabile)
- contenere un bit di “cancellazione” o di “usato/non usato” (la cancellazione non viene effettuata immediatamente, ma al momento della “garbage collection”)
per accedere a un campo:
- offset: numero di byte del record che precedono il campo (se tutti i campi hanno lunghezza fissa, l’inizio di ciascun campo sarà sempre ad un numero fisso di byte dall’inizio del record)
se il record contiene campi a lunghezza variabile:
- a inizio campo potrebbe esserci un contatore che specifica la lunghezza del campo in numero di byte
oppure
- all’inizio del record ci sono gli offset dei campi a lunghezza variabile (i campi a lunghezza fissa precedono quelli a lunghezza variabile
Nel primo caso, per individuare la posizione di un campo bisogna esaminare i campi precedenti per vedere quanto sono lunghi - la seconda strategia è quindi più efficiente.
puntatori
Un puntatore ad un record/blocco è un dato che permette di accedere rapidamente ad esso - può essere:
- l’indirizzo dell’inizio del record/blocco sul disco
- (nel caso di un record) una coppia (b,k) con b = indirizzo del blocco che contiene il record, e k = valore della chiave
- in questo caso, è possibile cambiare la posizione del record all’interno del blocco (nel primo no, altrimenti potremmo avere dei dangling pointer)
blocchi
In un blocco ci possono essere informazioni sul blocco stesso e/o puntatori ad altri blocchi.
record di lunghezza fissa
Se un blocco contiene solo record di lunghezza fissa:
- il blocco è suddiviso in aree di lunghezza fissa, ciascuna delle quali può contenere un record
- i bit “usato/non usato” sono in uno o più byte a inizio blocco
Un record va inserito in un area non usata. Se il bit “usato/non usato” è in ciascun record, ciò può richiedere la scansione di tutto il blocco; per questo, per evitarlo, si possono raccogliere tutti i bit “usato/non usato” in uno o più byte all’inizio del blocco.
record di lunghezza variabile
Se un blocco contiene record di lunghezza variabile:
- si pone in ogni record un campo che ne specifica la lunghezza in byte
oppure:
- si pone all’inizio del blocco una directory con i puntatori (offset) ai record nel blocco
Questa directory può essere realizzata in uno dei modi seguenti:
- preceduta da un campo che specifica quanti sono i puntatori
- è una lista di puntatori (con fine specificata da uno
0) - ha dimensione fissa e contiene
0negli spazi che non contengono puntatori
operazioni sulle basi di dati
un’operazione sulla base di dati consiste di:
- ricerca
- inserimento (implica ricerca se vogliamo evitare duplicati)
- cancellazione (implica ricerca)
- modifica (implica ricerca)
di un record
la ricerca è alla base di tutte le altre operazioni
Esamineremo diversi tipi di organizzazione di file che consentono la ricerca di record in base al valore di uno o più campi chiave.
"chiave"
il termine “chiave” non va inteso per forza come chiave relazionale - vedremo anche ricerche che hanno come chiavi “semplici” attributi.
file heap
partiamo da una “non-organizzazione”: la collocazione di record nei file in ordine determinato solo dall’ordine di inserimento.
- ha le prestazioni peggiori nella ricerca
- l’inserimento è molto veloce se ammettiamo duplicati
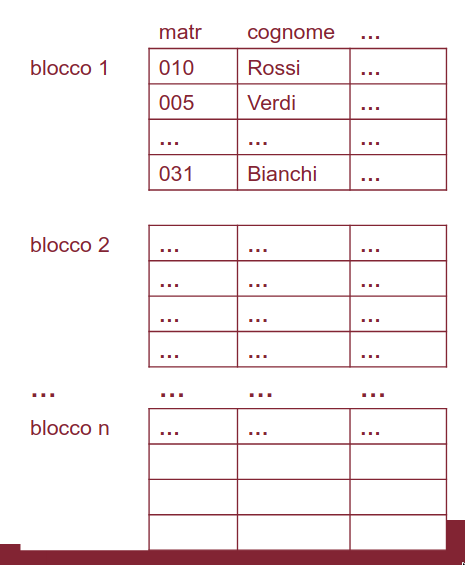
visto che un record viene inserito sempre come ultimo record del file, tutti i blocchi tranne l’ultimo sono pieni.
- l’accesso al file avviene attraverso la directory (che contiene i puntatori ai blocchi)
Se si vuole cercare un record, occorre scandire tutto il file, iniziando dal primo record fino a trovare quello desiderato.
nota
(Se si cerca una chiave relazionale, ci si può fermare una volta trovato il dato. Se non si cerca una chiave, bisogna trovare tutti i dati)
Il costo della ricerca varia in base a dove si trova il record: se si trova nell’i-esimo blocco, occorre effettuare accessi. Ha senso valutare il costo medio della ricerca, ma solo nel caso in cui si cerca in base alla chiave: se si cerca invece in base a un altro attributo, si dovrà scorrere comunque tutto.
esempio di valutazione
- N = 151 record
- Ogni record 30 byte
- Ogni blocco contiene 65 byte
- Ogni blocco ha un puntatore al prossimo blocco (4 byte)
(Stiamo ipotizzando una struttura linkata in cui ogni blocco punta al successivo sul disco.)
Per capire quanti accessi bisogna fare, bisogna capire quanti blocchi servono, e quindi quanti record interi vanno in ogni blocco:
- - non posso metterci lo 0,3 di un record, quindi bisogna prendere la parte inferiore
Sapendo che ho 151 record e quanti record entrano per blocco, calcolo quanti blocchi mi servono:
- - visto che devo allocare blocchi interi, devo allocare lo spazio per 76 blocchi o mi perderei lo 0,5
In una ricerca, devo scorrere la lista di 76 blocchi: se sono fortunata, trovo il record nel primo blocco, ma potrebbe trovarsi nell’ultimo o in uno qualsiasi
costo medio della ricerca
Cominciamo dalla ricerca quando la chiave ha un valore che non ammette duplicati.
inserimento
Servono:
- (ricerca di un possibile duplicato - vale il tempo approssimato di accessi: appena trovo un duplicato, ho finito)
- 1 accesso in lettura ⇒ portare l’ultimo blocco in memoria principale
- 1 accesso in scrittura ⇒ riscrivere l’ultimo blocco in memoria secondaria, dopo aver aggiunto il record
modifica
Servono:
- costo della ricerca
- 1 accesso in scrittura ⇒ riscrivere in memoria secondaria il blocco, dopo aver modificato il record
- per ogni occorrenza della chiave, se ammettiamo duplicati
cancellazione
Servono:
- costo della ricerca
- 1 accesso in lettura ⇒ per leggere l’ultimo blocco, da cui prendiamo un record per sostituire quello cancellato
- più complicato se i record sono di lunghezza variabile: in quel caso dobbiamo spostare verso l’alto tutti i record successivi, modificando eventuali puntatori
- 2 accessi in scrittura ⇒ riscrivere in memoria secondaria il blocco modificato e l’ultimo blocco
domande orale
possibili domande orale
- com’è organizzato un disco? (non so se l’abbia mai chiesto)
- da cosa è formato un record?
- costo operazioni heap
- dimostrazione del costo della ricerca