Il compito fondamentale di un sistema operativo è la gestione dei processi - computazioni di tipi diversi. Deve quindi:
- permettere l’esecuzione alternata di processi multipli (interleaving)
- assegnare le risorse ai processi (es. stampante, monitor ecc), e proteggere le risorse assegnate
- permettere ai processi di scambiarsi informazioni
- permettere la sincronizzazione dei processi
definizioni di processo
- un programma in esecuzione (o un’istanza di un programma in esecuzione, ogni esecuzione anche dello stesso programma è un processo diverso).
- l’entità che può essere assegnata a un processore per l’esecuzione
- un’unità di attività caratterizzata dall’esecuzione di una sequenza di istruzioni, da uno stato, e da un insieme associato di risorse
- è composto da:
- codice: le istruzioni da eseguire
- un insieme di dati
- attributi che descrivono lo stato del processo
un “processo in esecuzione” vuol dire solo che “un utente ha richiesto l’esecuzione di un programma che non è ancora terminato” (quindi non vuol dire che sia necessariamente in esecuzione su un processore). Dietro ogni processo c’è un programma (tipicamente memorizzato su archiviazione di massa - tranne per alcuni processi creati dal sistema operativo stesso), che, quando viene eseguito, genera almeno un processo.
macrofasi di un processo
un processo ha 3 macrofasi: creazione, esecuzione, terminazione.
- la terminazione può essere prevista (es. quando ha finito di eseguire le istruzioni, o quando un utente lo chiude) o non prevista (es. interrupt, eccezioni, accessi non consentiti)
elementi di un processo
Finché il processo è in esecuzione, ad esso è associato un insieme di informazioni, tra cui:
- un identificatore (il sistema operativo deve poter identificare i processi)
- uno stato
- una priorità
- hardware context - valore corrente dei registri della CPU
- puntatori alla memoria
- informazioni sullo stato dell’I/O
- informazioni di accounting - quale utente lo segue
process control block
per ogni processo ancora in esecuzione, esiste un process control block, che racchiude le informazioni sul processo e si trova nella zona di memoria riservata al kernel.
- è creato e gestito dal sistema operativo, e gli permette di gestire più processi contemporaneamente
- la sua funzione principale è di avere abbastanza informazioni per poter fermare un programma in esecuzione e farlo riprendere dallo stesso punto in cui si trovava.
traccia ed esecuzione di un processo
La traccia di un processo (trace) è la sequenza di istruzioni che vengono eseguite.
- il dispatcher è un piccolo programma che sospende un processo per farne andare in esecuzione un altro.
esecuzione di un processo
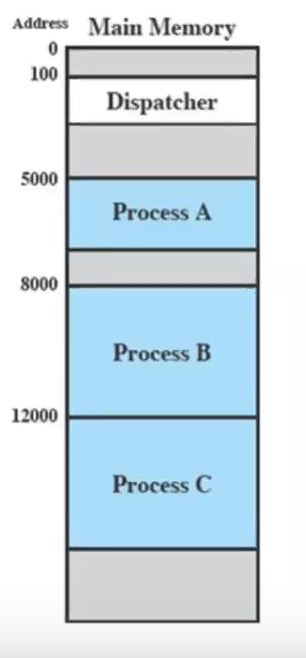

creazione e terminazione di un processo
In un certo istante, in un sistema operativo ci sono processi. Se l’utente dà un comando, quasi sempre si crea un nuovo processo.
process spawning
Il process spawning è la creazione di un processo da parte di un altro processo.
- il processo padre crea il nuovo processo
- il processo figlio è il nuovo processo
- (tipicamente) il numero di processi aumenta, perché il padre rimane in esecuzione
Per creare un processo, il SO deve:
- assegnargli un PID unico
- allocargli spazio in memoria principale
- inizializzare il process control block
- inserire il processo nella giusta coda
- creare o espandere altre strutture dati
terminazione di un processo
avviene per:
- normale completamento: viene generato un HALT che genera un’interruzione per il sistema
- uccisioni: dal SO per errori (es. memoria non disponibile, operazioni fallite, errore fatale), dall’utente, da un altro processo
e si passa da processi a
stato di un processo
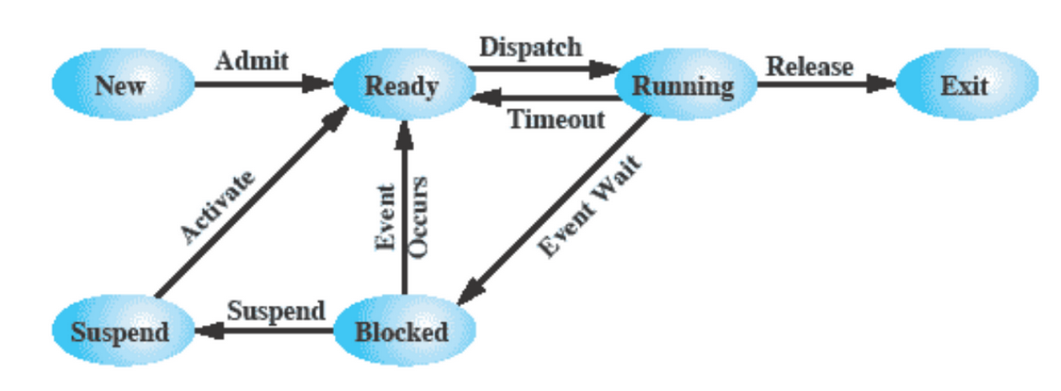
modello dei processi a due stati
- in esecuzione
- non in esecuzione (ma comunque “attivo”)
avrebbe una struttura del genere:
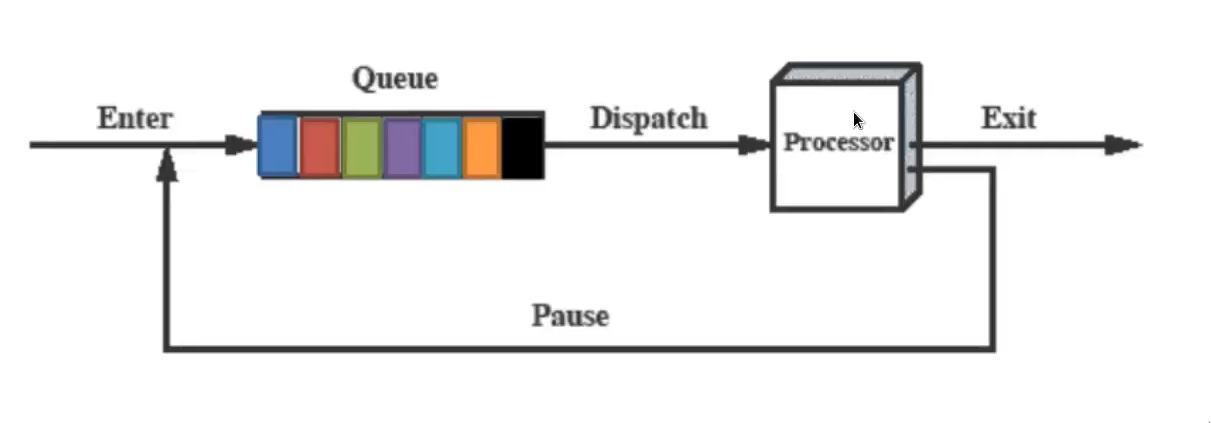
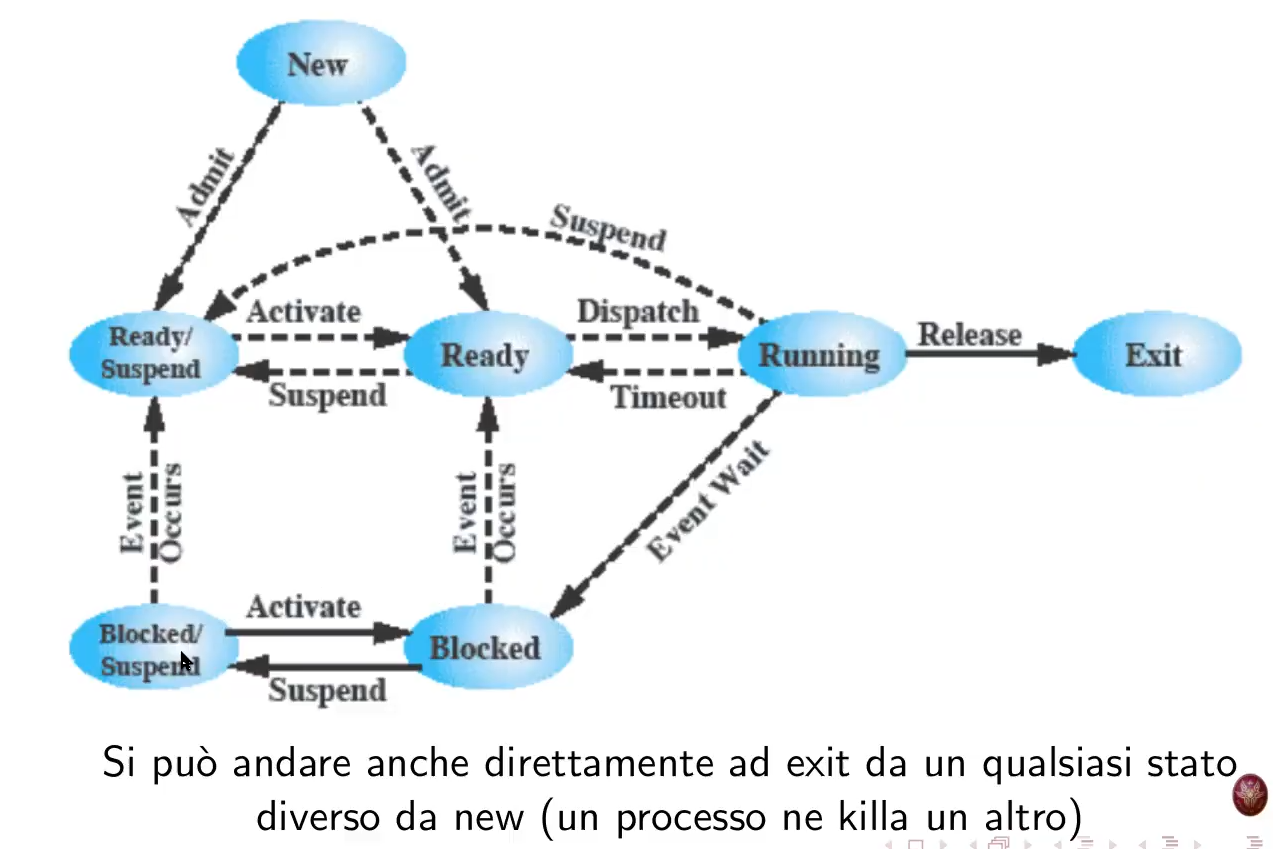
modello di processi a 5 stati
(in realtà si può passare anche da ready o blocked a exit se un processo viene killato da un altro processo)
I processi vengono posti in due o più code:
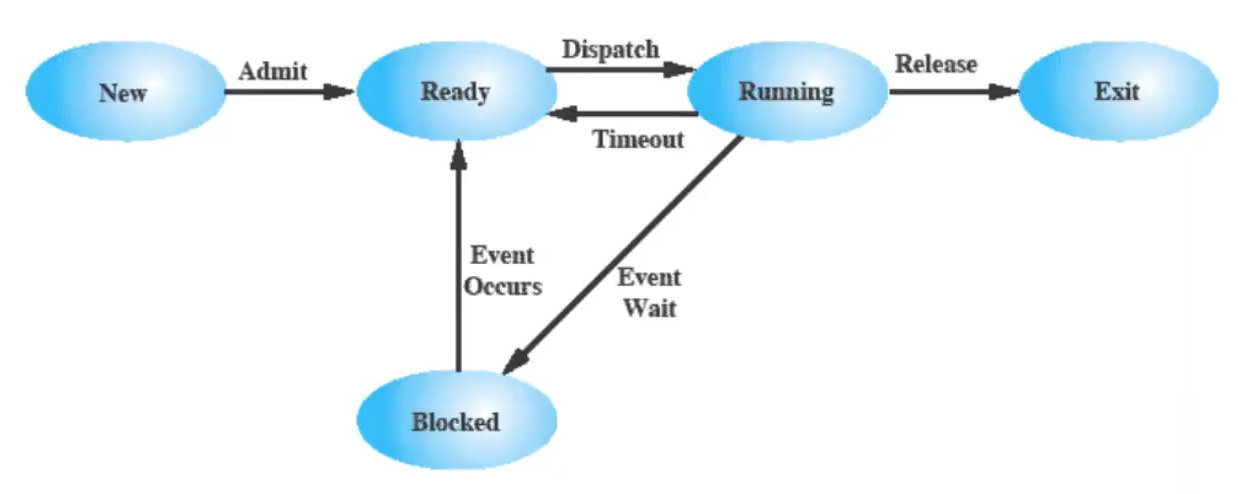
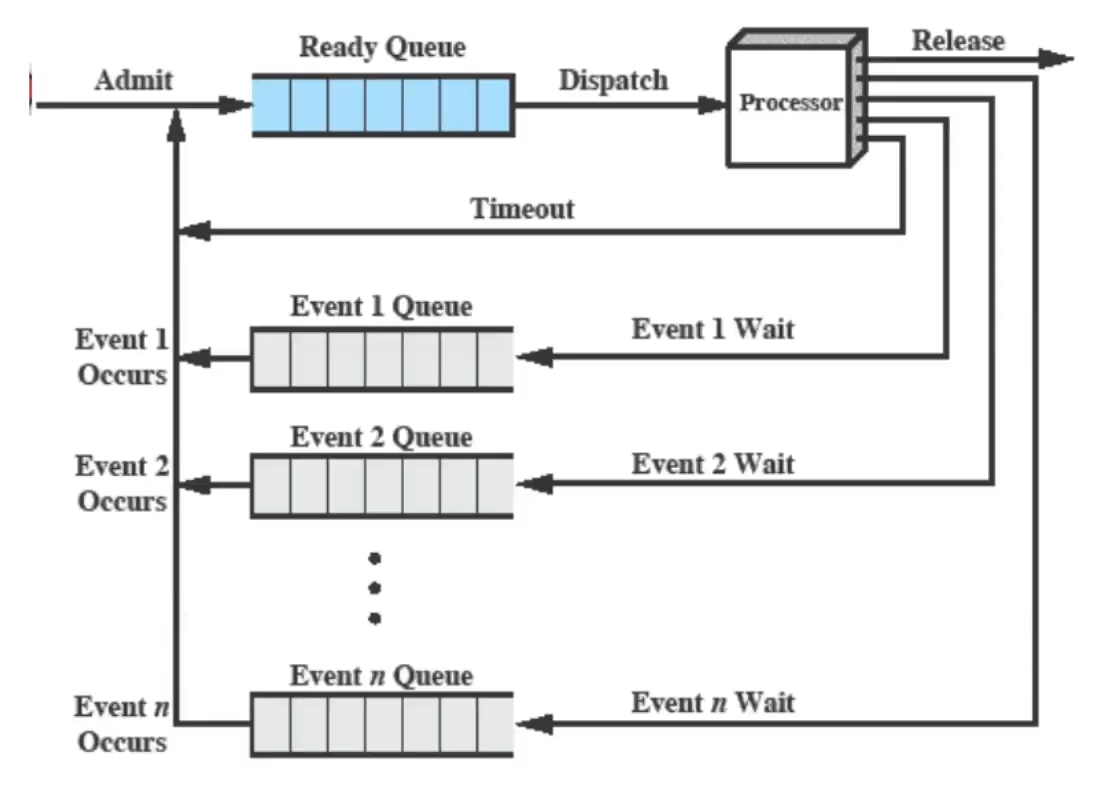
processi sospesi - modello a 7 stati
visto che il processore è più veloce dell’I/O, potrebbe succedere che tutti i processi in memoria siano in attesa di I/O - in questo caso questi vengono swappati su disco, così da liberare memoria e non lasciare il processore inoperoso.
- lo stato blocked diventa suspended quando il processo è swappato su disco.
- ci sono quindi due nuovi stati (un nuovo stato con due casi diversi):
- blocked/suspend - swappato mentre era bloccato
- ready/suspend - swappato mentre non era bloccato
un solo stato suspend
esiste anche un modello a sei stati, con un solo stato “suspend”
stati in UNIX (presente sotto)
stati in UNIX
Link to originaldiagramma degli stati di Unix (molto simile ai sette stati)
- si passa per forza per Kernel Running prima di arrivare a User Running perché vuol dire che si fa uno swap
- quando un processo finisce, passa allo stato Zombie - perché ci si aspetta che il padre sopravviva al figlio e, finché il figlio non comunica al padre il suo exit status, resta nello stato di Zombie - l’immagine sparisce (lo stato zombie rappresenta un processo terminato ma che resta nelle tabelle dei processi perché il padre possa prendersi il suo valore di ritorno)
- lo schema non è interrompibile quando è in Kernel-Mode (ora per Linux non è così)
/../../../vault/attachments/unix-dgstati.png)
| motivo per sospendere | commento |
|---|---|
| swapping | la memoria serve per un processo ready |
| interno al SO | il SO sospetta che il processo stia causando problemi |
| richiesta utente interattiva | es. debugging |
| periodicità | il processo viene eseguito periodicamente e può venire sospeso nell’attesa |
| richiesta del padre | il padre lo vuole sospendere per motivi di efficienza computazionale |
processi e risorse
Il Sistema Operativo è l’entità che gestisce l’uso delle risorse di sistema da parte dei processori, e deve dunque conoscere lo stato di ogni processo e di ogni risorsa. Per ogni processo/risorsa, il SO costruisce tabelle.
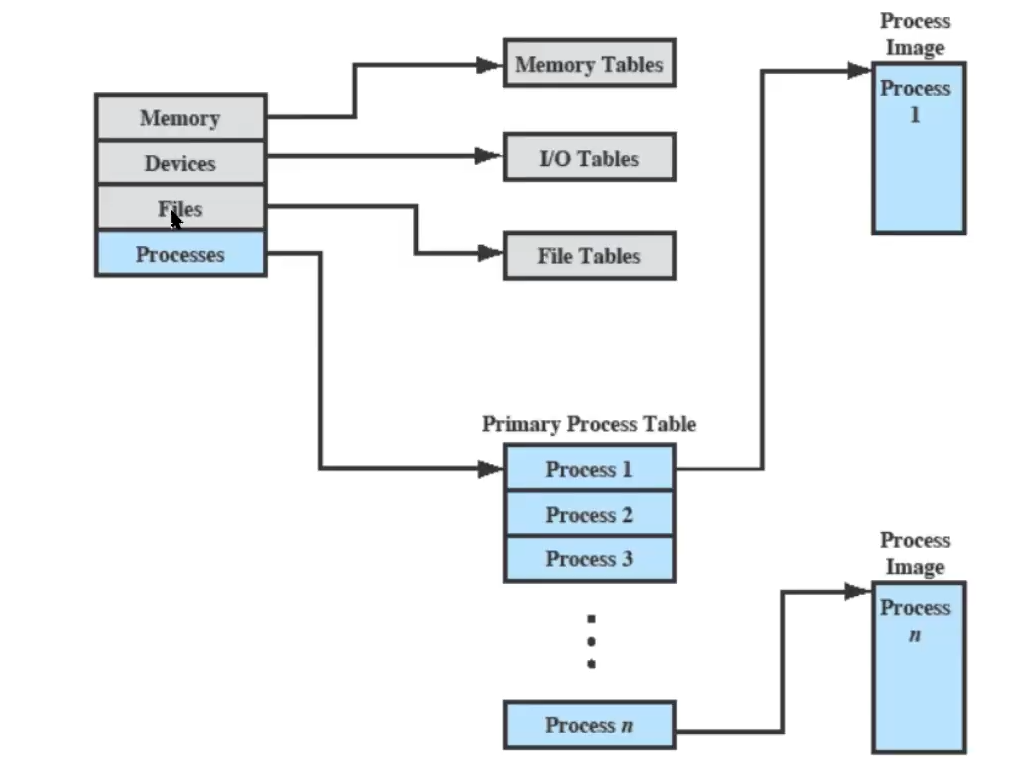
(soprattutto per i processi, si trovano nella parte di RAM riservata al kernel)
Alcuni esempi di queste tabelle sono:
- tabelle di memoria - per gestire memoria principale e secondaria.
- contengono informazioni sull’allocazione della memoria, e sugli attributi di protezione per l’accesso a zone di memoria condivisa
- tabelle per l’I/O - per gestire dispositivi e canali di I/O.
- il Sistema Operativo deve sapere se i dispositivi sono disponibili, gli stati delle operazioni, la locazione in memoria per i trasferimenti I/O.
- tabelle per i file
- contengono informazioni su esistenza, locazione, stato dei files
tabelle dei processi:
attributi di un processo
Le informazioni relative a un processo possono essere divise in tre categorie:
- identificazione
- stato
- controllo
Nel Process Control Block ci sono solo le informazioni essenziali: i cosiddetti “attributi” (nella Primary Process Table).
PCB
Contiene informazioni di cui il sistema operativo ha bisogno per controllare e coordinare i vari processi attivi. (ovvero)
PID
ID del processo padre: PPID
ID dell’utente proprietario
l’hardware context (registri, PC, stack pointer ecc) può essere copiato sul PCB stesso in alcune occasioni.
informazioni per il controllo del processo (stato, priorità, informazioni sullo scheduling)
supporto per strutture dati (puntatori ad altri processi)
comunicazioni tra processi (flag, segnali, messaggi)
permessi speciali
gestione della memoria (puntatori)
uso delle risorse (file aperti, quante volte ho usato un processo ecc.)
- è la struttura più importante del sistema operativo, perché definisce il suo stato
- richiede protezione
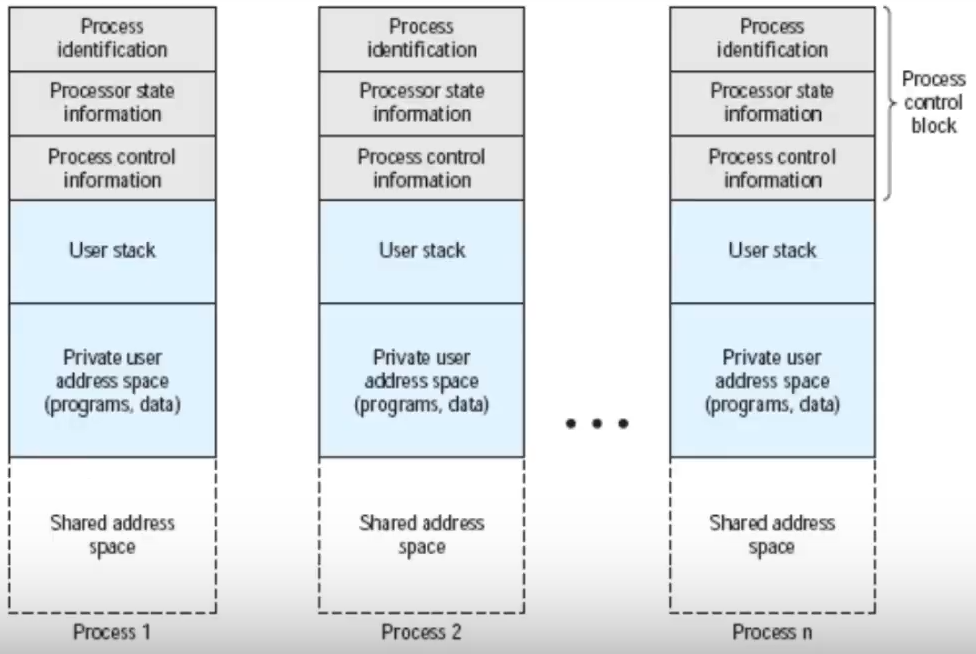
Tutta la memoria necessaria al processo è invece nella Process Image (programma sorgente, dati, stack, PCB).
- eseguire un’istruzione cambia l’immagine del processo
stato del processore
(diverso dallo stato del processo) o Hardware Context. Dato dai contenuti dei registri del processore in un dato momento:
- visibili all’utente
- di controllo e stato
- puntatori allo stack
- PSW (Program Status Word)
come si identifica un processo
Ad ogni processo è assegnato un numero identificativo unico: il PID (Process IDentifier). Questo numero viene utilizzato da molte tabelle del sistema operativo per realizzare collegamenti con la tabella dei processi (es. tabella I/O mantiene una lista dei PID dei processi che stanno usando I/O).
se un processo viene terminato il suo PID può essere riassegnato
modalità di esecuzione
la maggior parte dei processori supporta almeno due modalità di esecuzione:
- modalità sistema (kernel mode): pieno controllo, si può accedere a qualsiasi locazione per la RAM - serve al kernel
- modalità utente: molte operazioni sono vietate - serve ai programmi utente
kernel mode
esempi di operazioni kernel mode:
- gestione dei processi (creazione e terminazione, scheduling, switching, sincronizzazione e comunicazione)
- gestione della memoria principale (allocazione di spazio, gestione memoria virtuale)
- gestione I/O
- funzioni di supporto (interrupt, eccezioni, accounting (chi ha richiesto un’operazione), monitoraggio)
passaggio da user mode a kernel mode e ritorno
Un processo utente inizia sempre in modalità utente: per poter cambiare modalità, serve un interrupt (l’hardware fa partire una procedura all’interno del kernel, ma prima di farlo cambia la modalità da utente a kernel) Quindi, tutti gli interrupt handler sono gestiti in modalità kernel. Prima di restituire il controllo all’utente, l’ultima istruzione dell’interrupt handler fa lo switch a modalità utente.
- quindi, un processo utente può passare alla modalità kernel solo per eseguire software di sistema.
alcuni casi in cui può capitare:
- codice eseguito per conto dello stesso processo interrotto - che lo ha voluto (es. system call)
- codice eseguito per conto dello stesso processo interrotto - che non lo ha voluto (es. abort - processo viene terminato, fault - non fatale, viene eseguito qualcosa e poi si torna in user mode e si continua il processo)
- codice eseguito per conto di un altro processo
system call sui pentium
una system call è un pezzo di codice che
- prepara gli argomenti della chiamata in opportuni registri - tra questi, il primo è un numero che identifica una system call - system call number
- esegue l’istruzione
int 0x80, che solleva un’eccezione (dal Pentium 2 in poi,sysenter, che omette alcuni controlli
switching tra processi
lo switching tra processi pone svariati problemi:
- quali eventi determinano uno switch? perché il sistema operativo decide di rimpiazzare un processo?
- cosa deve fare il sistema operativo per tenere aggiornate tutte le strutture dati dopo uno switch tra processi?
quando effettuare uno switch?
| meccanismo | causa | uso |
|---|---|---|
| interruzione | esterna all’esecuzione dell’istruzione corrente | reazione ad un evento asincrono (es. a chiede I/O, a diventa blocked e si passa a b, arriva la risposta ad a e il SO lo fa tornare in esecuzione) |
| eccezione | associata all’esecuzione dell’istruzione corrente | gestione di un controllo sincrono (es. pagina sbagliata della memoria virtuale) |
| chiamata al sistema operativo (syscall) | richiesta esplicita | chiamata a funzione di sistema |
| passaggi (in kernel mode): | ||
| (per il vecchio processo) |
- salvare il contesto del programma (registri e CPU)
- aggiornare il process control block (che è running)
- spostare il PCB nella coda appropriata: ready, blocked, ready/suspend
- scegliere il nuovo processo (può avvenire anche prima) - fatto dal dispatcher
(passi di sopra al contrario per il nuovo processo)
- aggiornare il process control block del nuovo processo
- aggiornare le strutture dati per la gestione della memoria
- ripristinare il contesto del processo selezionato (si prende il context dal PCB e si ripristina ciò che è necessario)
il sistema operativo è un processo?
- il sistema operativo è solo un insieme di programmi, ed è eseguito dal processore come ogni altro programma.
- semplicemente, ogni tanto, il SO “lascia” il processore ad altri programmi
dipende da sistema operativo a sistema operativo:
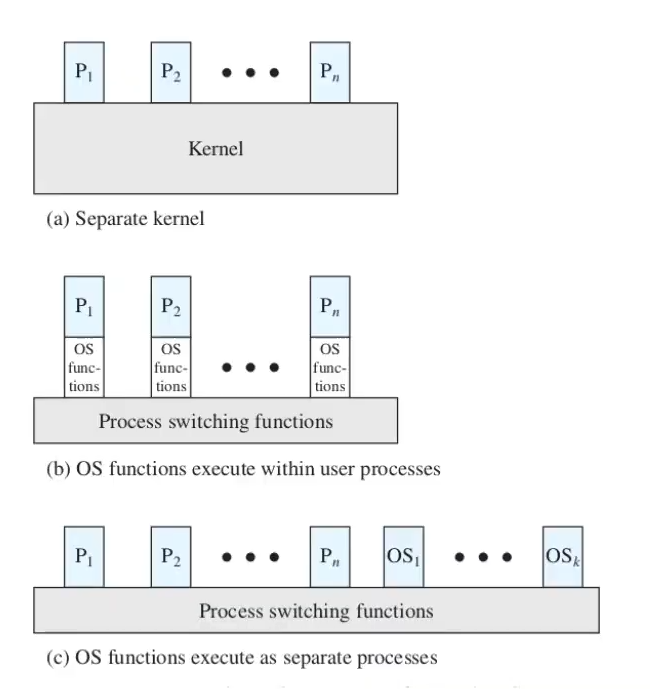
- kernel eseguito al di fuori dei processi
- il concetto di processo si applica solo ai programmi utente
- il SO è eseguito come un’entità separata, con privilegi più elevati e una sua zona di memoria dedicata (sia per i dati che per il codice sorgente)
- esecuzione all’interno dei processi utente
- il SO viene eseguito nel contesto di un processo utente (e cambia solo la modalità di esecuzione)
- non c’è bisogno di un process switch per eseguire una funzione del SO, ma solo di un mode switch
- lo stack delle chiamate (user stack) è comunque separato, mentre dati e codice macchina sono condivisi con i processi
- il process switch avviene solo, eventualmente, alla fine, se lo scheduler decide che tocca ad un altro processo
- SO basato su processi (tutto è un processo)
- il SO è implementato come un insieme di processi di sistema (che partecipano alla “competizione” per il processore), con privilegi più alti
- l’unica cosa che non è un processo è lo switch tra processi
caso concreto: linux
Linux utilizza una via di mezzo tra la seconda e la terza opzione
- le funzioni del kernel sono per lo più eseguite tramite interrupt, on behalf of il processo corrente
- ci sono però dei processi di sistema che partecipano alla normale competizione del processore senza essere evocati esplicitamente (tipicamente processi ciclici)
- creati in fase di inizializzazione del SO
- es: creare spazio usabile nella RAM liberando zone non usate, eseguire operazioni di rete
stati in UNIX
diagramma degli stati di Unix (molto simile ai sette stati)
- si passa per forza per Kernel Running prima di arrivare a User Running perché vuol dire che si fa uno swap
- quando un processo finisce, passa allo stato Zombie - perché ci si aspetta che il padre sopravviva al figlio e, finché il figlio non comunica al padre il suo exit status, resta nello stato di Zombie - l’immagine sparisce (lo stato zombie rappresenta un processo terminato ma che resta nelle tabelle dei processi perché il padre possa prendersi il suo valore di ritorno)
- lo schema non è interrompibile quando è in Kernel-Mode (ora per Linux non è così)
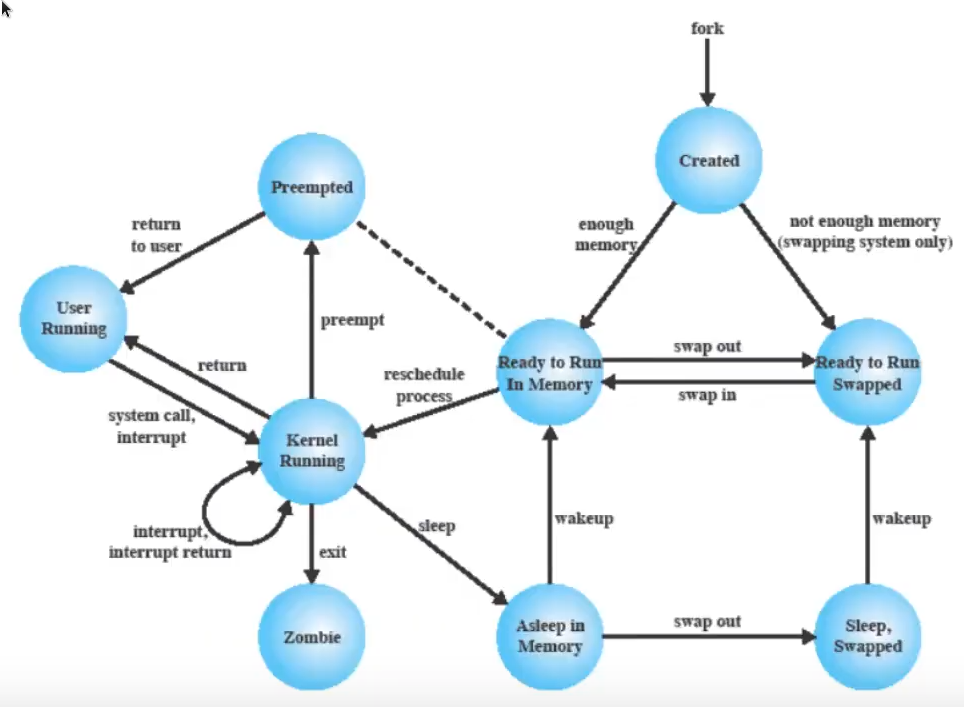
processo Unix
Un processo Unix è diviso in vari livelli: utente, registro, sistema.
livello utente
- process text: codice sorgente in linguaggio macchina del processo
- process data: dati (valori variabili ecc)
- user stack: stack delle chiamate del processo (e argomenti con cui è stato chiamato)
- shared memory: memoria confivisa con altri processi
livello registro
i vari registri nel PCB, che vengono copiati al momento di un process switch (PC, Processor Status Register, SP, General Purpose Registers)
livello sistema
- process table entry: puntatore alla tabella di tutti i processi, dove individua il corrente

- u area: informazioni per il controllo del processo
- per process region table: definisce il mapping tra indirizzi virtuali e fisici (page table)
- kernel stack: stack delle chiamate, usato per le funzioni da eseguire in modalità sistema
thread
è importante che alcune operazioni siano organizzate in maniera parallela (al loro interno) ⟶ vengono suddivise in diverse esecuzioni (i thread).
Diversi thread di uno stesso processo condividono tutte le risorse del processo tranne:
- lo stack delle chiamate (e variabili locali) - ogni thread può chiamare funzioni diverse
- il processore (se il sistema ha più processori, i diversi thread possono andare in esecuzione su processori diversi)
Il codice sorgente, variabili globali, memoria, I/O ecc. sono condivisi.
info
Quindi, si può dire che il concetto di processo incorpora:
- gestione delle risorse - i processi vanno presi come blocco unico
- scheduling/esecuzione - i processi possono contenere diversi thread
Quindi, in un sistema operativo che utilizza i thread, non ci sarà più un PCB, un’immagine e una stack, ma un PCB e un’immagine comuni, e, per ogni thread, la sua gestione:
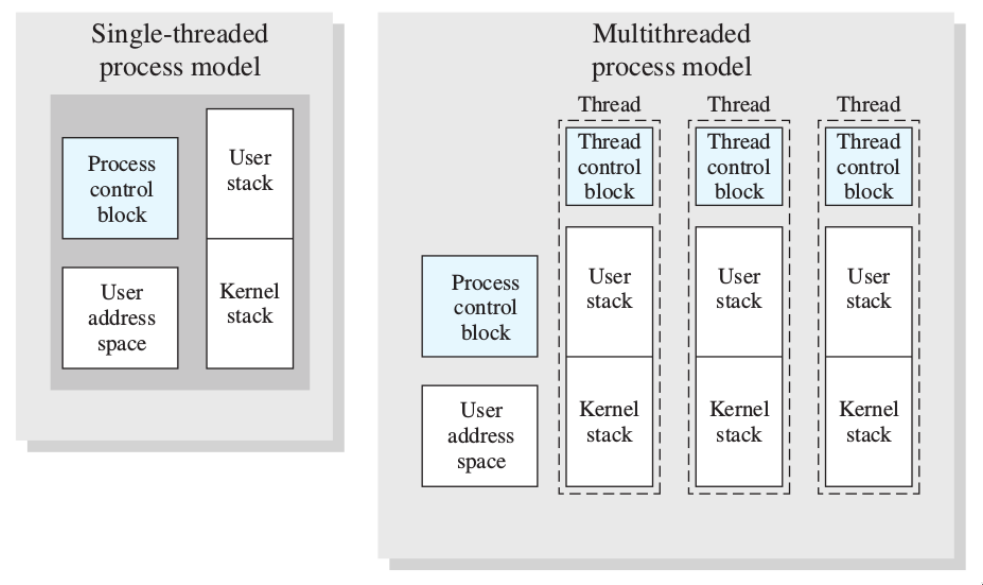
perché introdurre i thread?
- sono più semplici: la creazione, la terminazione, lo switch, la comunicazione
Quindi, ogni processo viene creato con un thread ed è poi possibile fare le seguenti operazioni:
spawn- creazione di un nuovo thread (più veloce dellaforkperché non deve creare spazio, stato risorse ecc)block- blocco del thread esplicito (es. se deve aspettare un altro thread) eunblockfinish
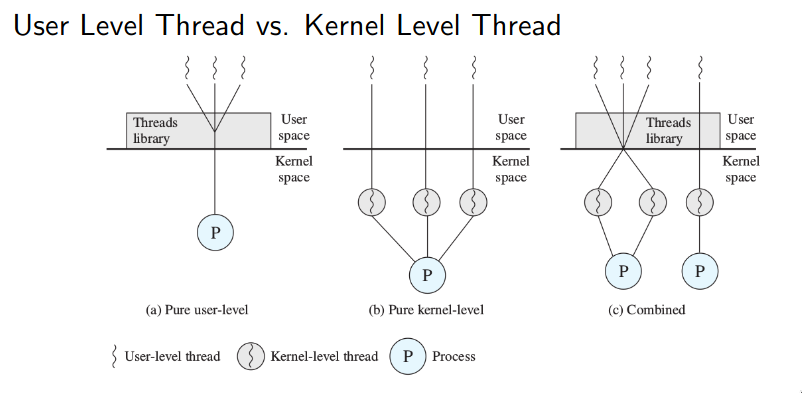
ULT vs KLT
(preso qualche pezzettino di pros/cons dagli appunti exyss)
User-Level-Thread
Se si usano gli ULT, significa che il sistema operativo non prevede l’utilizzo di thread, e che questi sono quindi gestiti da librerie a livello utente.
pros:
- lo switch è molto facile ed efficiente perché non prevede il mode switch a kernel
- si può attuare una politica di scheduling diversa per ogni applicazione
- permettono di usare i thread anche su sistemi operativi che non li offrono nativamente
cons:
- il kernel non è a conoscenza degli user thread attivi
- se un thread si blocca, si bloccano tutti i thread di quel processo (a meno che non sia un blocco causato da una
block)- tutti i thread del processo possono utilizzare comunque un solo core
- se il Sistema Operativo non ha KLT, non si possono usare i thread per le funzioni del sistema operativo stesso
Kernel-Level-Thread
Il sistema operativo è responsabile per il supporto e la gestione di tutti i kernel thread attivi, e fornisce delle syscall per poterli creare e gestire dall’user space. Ogni kernel thread è dotato di un Thread Control Block (TCB).
pros:
- il kernel è a conoscenza di tutti i kernel thread avviati
- lo scheduler può decidere di cedere più tempo di esecuzione a un processo con più thread
- passare da un thread all’altro è più veloce di passare da un processo all’altro
cons:
- rende il kernel più complesso
- è un sistema lento perché si fanno spesso chiamate al kernel
processi e thread in Linux
In Linux, l’unità di base sono i thread (quindi, essenzialmente una fork crea thread), che Linux chiama Lightweight process.
def wikipedia LWP
In the traditional meaning of the term, as used in Unix System, a LWP runs in user space on top of a single kernel thread and shares its address space and system resources with other LWPs within the same process. Multiple user-level threads, managed by a thread library, can be placed on top of one or many LWPs - allowing multitasking to be done at the user level, which can have some performance benefits
- sono possibili sia i KLT che gli ULT
l’utente e il sistema usano due terminologie diverse per “identificazione”: per l’utente:
- il PID è unico per tutti i thread di un processo
- il tid (task identifier) identifica un singolo thread
- il tid non va da 1 al numero di thread del processo - anzi, c’è sempre un tid che coincide con il PID
(perché,) per il sistema:
- l’entry del PCB che dà il PID comune a tutti i thread di un processo è il
tgid(thread group leader identifier), che coincide con il PID del primo thread del processo
(se si crea un nuovo processo con un thread, il PID del thread coincide con il PID del processo, e, quando si crea un nuovo thread - quel thread ha un nuovo PID, e il tgid del nuovo thread coincide con il PID di prima)
- la chiamata a
getpid()restituisce il tgid - c’è un PCB per ogni thread
stati dei processi in linux
la gestione degli stati in linux è sostanzialmente come quella a 5 stati (quindi, non fa esplicita menzione allo stato suspended). Ma, internamente, usa stati “atipici”:
- non distingue tra ready e running:
task_running - lo stato blocked è diviso in base al motivo in:
task_stopped(esplicitamente bloccato),task_traced(debugging),task_interruptible(non presenta problemi),task_uninterruptible(problematico - c’è poco da fare) - due stati per exit:
exit_dead,exit_zombie
segnali ed interrupt in linux
Non bisogna confondere segnali con interrupt (o eccezioni).
I segnali possono essere inviati da un processo utente ad un altro tramite syscall (kill).
L’opportuno campo del PCB del processo ricevente viene aggiornato - quando il processo viene nuovamente schedulato per l’esecuzione, il kernel controlla prima se ci sono segnali pendenti - se sì, esegue un signal handler (in user mode), che può anche essere riscritto dal programmatore (tranne sig begin e sig stop).
Quindi, le differenze tra signal e interrupt sono:
- signal handler sono eseguiti in user mode, mentre interrupt handler in kernel mode
- signal handler possono essere riscritti dal programmatore, interrupt handler no