La programmazione dinamica è una tecnica di progettazione di algoritmi basata sulla divisione del problema in sottoproblemi e sull’utilizzo di sottostrutture ottimali (la soluzione ottimale al sottoproblema può essere usata per trovare la soluzione ottimale all’intero problema).
programmazione dinamica vs divide et impera
il divide et impera suddivide il problema in sottoproblemi indipendenti e li risolve separatamente; nel caso in cui i sottoproblemi risultino uguali, risolve lo stesso problema più volte svolgendo lavoro inutile
la programmazione dinamica ottimizza evitando ricalcoli inutili tramite memoization, ed è adatta a problemi i cui sottoproblemi si ripetono e/o sono dipendenti tra loro (overlapping di sottoproblemi)
memoization
La memoization (memoizzazione) è una tecnica che consiste nel salvare in memoria i valori restituiti da una funzione, in modo da averli a disposizione senza doverli ricalcolare.
una funzione può essere “memoizzata” solo se non ha effetti collaterali e restituisce sempre lo stesso valore quando riceve in input gli stessi parametri
(si dice che “soddisfa la trasparenza referenziale”)
(definizioni da wikipedia, thx wikipedia)
caratteristiche della programmazione dinamica
Gli algoritmi di programmazione dinamica si basano quindi spesso sulla costruzione di una tabella (lista o matrice) che memorizza soluzioni intermedie ai sottoproblemi, che verranno poi usate per arrivare a quella finale.
in una prima fase, ci si può concentrare sul calcolo del valore ottimo della soluzione; successivamente, la stessa tabella può essere utilizzata per risalire alla soluzione vera e propria cui quel valore corrisponde.
l’idea è partire dall’elemento che rappresenta la soluzione ottima e, seguendo a ritroso le decisioni registrate nella tabella, ricostruire il percorso che ha portato a quel risultato.
numeri di Fibonacci
La sequenza f0,f1,f2… dei numeri di Fibonacci è definita dall’equazione di ricorrenza:
fi=fi−1+fi−2
con f0=f1=1.
soluzione divide et impera
Una soluzione naïf è quella che utilizza il metodo divide et impera sfruttando la definizione stessa di numero di Fibonacci:
def Fib(n): if n <= 1: return 1 a = Fib(n-1) b = Fib(n-2) return a + b
L’equazione di ricorrenza di questo algoritmo è T(n)=T(n−1)+T(n−2)+O(1). Si ha T(n)≥2T(n−2)+O(1), che può essere risolta ottenendo T(n)≥Θ(2n/2).
Quindi, T(n)∈Ω(2n/2).
Il problema sta nel fatto che la funzione Fib viene chiamata sullo stesso input molte volte - i sottoproblemi in cui viene scomposto il problema non sono disgiunti, mentre l’algoritmo si comporta come se lo fossero.
Per rendere l’algoritmo più efficiente, basta quindi usare la memoizzazione e salvare in una lista i valori fib(i) quando li si calcola la prima volta.
def memFib(n, F): if n <= 1: return 1 if F[n] == -1: a = memFib(n-1, F) b = memFib(n-2, F) F[n] = a + b return F[n]F = [-1]*(n+1)
in questo modo, l’algoritmo effettuerà esattamente n chiamate ricorsive
tenendo conto che ogni chiamata ricorsiva costa O(1), la complessità di memFib è Θ(n)
ulteriori ottimizzazioni
Questo algoritmo può essere ulteriormente ottimizzato:
sostituendo la ricorsione con l’iterazione, si risparmia lo spazio occupato dalla gestione della ricorsion
la complessità spaziale della lista (Θ(n)) può essere ridotta a O(1) tenendo conto che basta conservare in memoria solo gli ultimi due valori calcolati
def FibOtt(n): if n <= 1: return n a = b = 1 for i in range(2, n+1): a, b = b, a + b return b
top-down, bottom-up
nella versione ricorsiva dell’algoritmo, si parte dal problema scomponendolo in sottoproblemi sempre più piccoli fino ad arrivare a problemi facilmente risolvibili ⟶ si parla di approccio top-down
nella versione iterativa, si comincia dai sottoproblemi di dimensione piccola per poi passare a quelli di dimensione via via crescente fino ad arrivare alla soluzione del problema originario ⟶ si parla di approccio bottom-up
problema dei file su disco
testo
Abbiamo un disco di capacità C e n file di varie dimensioni (ciascuna inferiore a C). Vogliamo trovare il sottoinsieme di file che può essere memorizzato su disco che massimizzi lo spazio occupato.
per semplicità di esposizione, ci limiteremo a calcolare il valore della soluzione ottima, ovvero il massimo spazio del disco che può essere occupato grazie agli n file
implementazione divide et impera
Un algoritmo divide et impera può partire dalle seguenti informazioni:
se la lista è vuota o C=0, la soluzione ottima vale 0
in caso contrario, l’ultimo file della lista può appartenere o no alla soluzione ottima:
se l’ultimo file non appartiene alla soluzione ottima, scegliendo tra i rimanenti n−1 file si trova una soluzione ottima per A[:−1],C
se l’ultimo file appartiene alla soluzione, scegliendo tra i rimanenti n−1 file si trova una soluzione ottima per A[:−1],C−A[n−1]
possiamo quindi ricondurci al calcolo della soluzione ottima di due sotto-problemi di dimensione inferiore e, una volta risolti questi due problemi e ottenuti i valori v1,v2 delle loro soluzioni, la soluzione al problema di partenza (passo combina) sarà data da:
max(v1,v2+A[−1])
implementazione:
def es(A, i, C): if i == 0 or C == 0: return 0 lascio = es(A, i-1, C) if A[i-1] > C: # sicuramente non posso prenderlo return lascio prendo = A[i-1] + es(A, i-1, C-A[i-1]) return max(lascio, prendo)
l’equazione di ricorrenza di questa implementazione è:
T(n,C)=T(n−1,C)+T(n−1,C−A[n−1])+Θ(1)
che ∈Ω(2n/2).
Attraverso la memoizzazione, possiamo ottenere una soluzione pseudopolinomiale.
algoritmo pseudopolinomiale
In teoria della complessità computazionale, un algoritmo è detto pseudopolinomiale se la sua complessità temporale è polinomiale nel valore numerico del suo input e non necessariamente nella sua dimensione (risolve un problema in tempo polinomiale quando i numeri presenti nell’input sono codificati in unario).
problema NP-completo
Il problema del disco (che è un caso particolare del problema dello zaino (analizzato sotto) ) è un problema NP-completo.
NP = “nondeterministic polynomial time”, è la classe dei problemi risolvibili non-deterministicamente in tempo polinomiale, ovvero i problemi per cui, data una soluzione, si può verificare in tempo polinomiale la sua correttezza (ma non si sa se si possano invece risolvere in tempo polinomiale ! wikipedia on P vs NP)
NP-completo ⟶ classe dei più difficili problemi in NP: se si trovasse un algoritmo in grado di risolvere in tempo polinomiale un qualsiasi problema NP-completo, allora si potrebbe usarlo per risolvere in tempo polinomiale ogni problema in NP (ogni problema in NP può essere ridotto in tempo polinomiale a un problema NP-completo)
Creiamo una tabella T di dimensione n+1×(C+1), in cui T[i][j] è il valore ottenuto dalla soluzione del sottoproblema in cui si hanno i primi i file e la dimensione del disco è j (quindi il massimo spazio che si può occupare in un blocco grande j con i primi i file).
Per compilarla, usiamo questo criterio:
T[i][j]={T[i−1,j]A[i]+T[i−1,j−A[i]]se non prendo i (lascio)se prendo i
(primo caso) se non aggiungo il file i, la capienza rimane quella calcolata per i primi i−1 file
(secondo caso) se invece aggiungo il file i, sto occupando A[i] unità di spazio e mi resterà una capacità di j−A[i]
quindi, il valore totale sarà dato dalla dimensione di i sommata al massimo valore ottenibile con i file precedenti e lo spazio residuo (ovvero T[i−1,j−A[i]])
Ogni cella deve contenere il massimo spazio occupato con i dati delle coordinate, quindi l’equazione generale per una cella sarà:
def es(A, C): T = [[-1]*(C+1) for i in range(len(A)+1)] return disco(A, len(A), C, T)def disco(A, i, c, T): if T[i][c] == -1: if i == 0 or c == 0: T[i][c] = 0 else: lascio = disco(A, i-1, c, T) # opzione senza i T[i][c] = lascio if A[i-1] <= c: # se non c'entra devo sicuramente lasciare prendo = A[i-1] + disco(A, i-1, c-A[i-1], T) T[i][c] = max(lascio, prendo) # max spazio occupato return T[i][c]
Il tempo di calcolo è limitato dalla dimensione della tabella: le operazioni di ogni chiamata di disco() costano infatti O(1), e il numero totale di chiamate non può superare la dimensione della tabella.
La complessità è quindi O(nC)
in realtà, Θ(nC) a causa dell’inizializzazione della tabella
questo algoritmo è quindi più efficiente della versione divide et impera?
se C è molto grande (ad esempio se supera 2n), la versione memoizzata si comporta peggio; altrimenti, può risultare anche molto più efficiente.
Spesso però (visto che si parla di capienza di dischi ed è comune che si lavori con numeri grandi) la profondità dell’albero delle chiamate ricorsive è molto grande e può portare ad uno stack overflow. Per evitare questo problema, ci si può concentrare direttamente sul calcolo della tabella T eliminando la ricorsione.
implementazione bottom-up:
def discoI(A, C): n = len(A) T = [ [0]*(C+1) for i in range(n+1) ] for i in range(1, n+1): for c in range(C+1): if c < A[i-1]: T[i][c] = T[i-1][c] else: T[i][c] = max(T[i-1][c], A[i-1]+T[i-1][c-A[i-1]]) return T[n][C]
anche questa versione ha una complessità di O(nC)
pseudopolinomiale
Questo algoritmo è pseudopolinomiale perché la capacità C dell’input è codificata in logC bit. Considerando il numero di bit come misura, infatti, la complessità dell’algoritmo sarà O(nC)=O(n⋅2logC), ovvero esponenziale nella dimensione binaria dell’output.
Usiamo ora la tabella appena calcolata per ricavare la soluzione ottima.
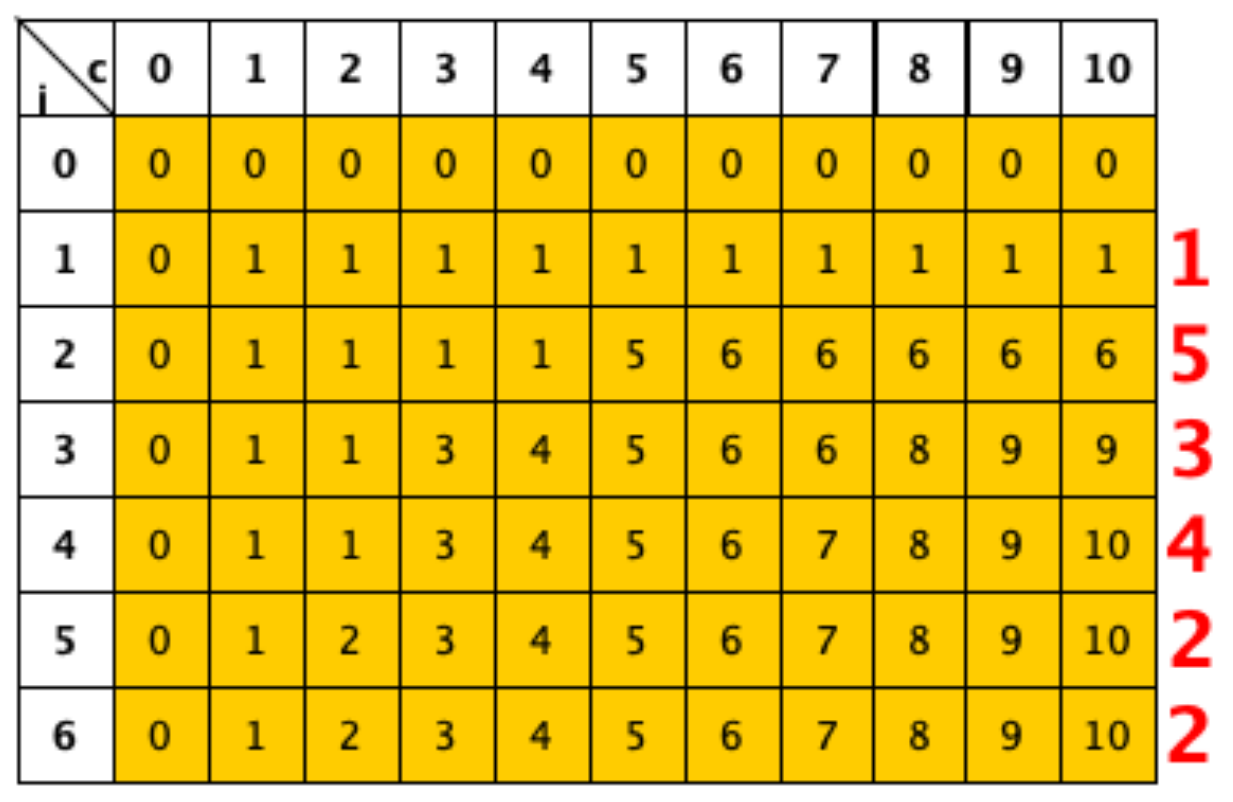
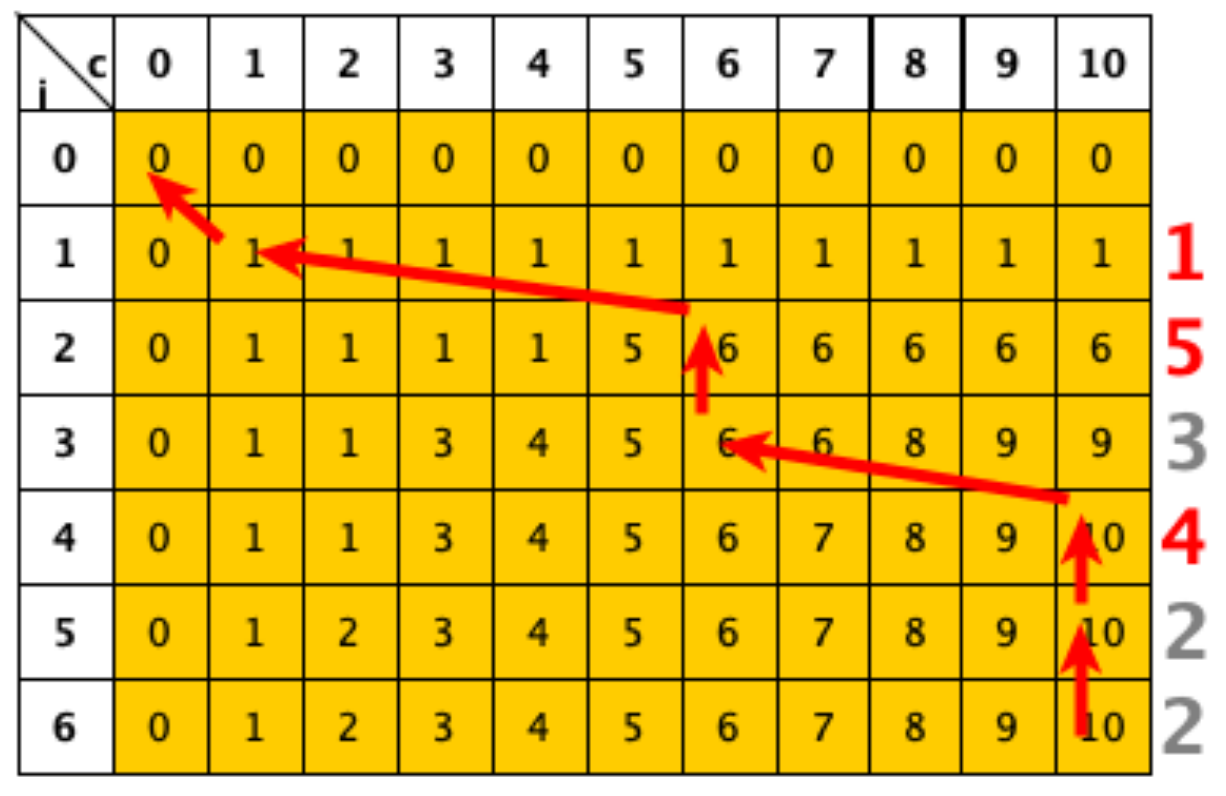
Prendiamo come esempio la tabella T relativa all’istanza C=10 e con 6 file di dimensioni A=[1,5,3,4,2,2].
a partire da T[n,c] possiamo disegnare, per ogni elemento toccato della tabella, una freccia verso l’elemento in base al quale è stato calcolato (se l’elemento è T[k][c], può essere o T[k−1],c o T[k−1,c−A[k]]).
quindi, se la freccia è verticale, vuol dire che il k-esimo file non è stato scelto; se invece è obliqua, vuol dire che è stato scelto.
seguendo le frecce, è possibile vedere che sono stati scelti i file di dimensioni 4,5 e 1
quindi, se T[k,c]=T[k−1,c], il k-esimo file non è stato scelto; altrimenti, T[k,c]>T[k−1,c] e il k-esimo file è stato scelto
implementazione:
def discoI(A, C): n = len(A) T = [ [0]*(C+1) for i in range(n+1) ] for i in range(1, n+1): for c in range(C+1): if c < A[i-1]: T[i][c] = T[i-1][c] else: T[i][c] = max(T[i-1][c], A[i-1]+T[i-1][c-A[i-1]]) valore = T[n][C] sol = [] i = n while i > 0: if T[i][valore] != T[i-1][valore] sol.append(i-1) valore -= A[i-1] i -= 1 return T[n][C], sol
il calcolo della tabella costa O(nC)
nella ricerca dei file, la tabella viene visitata a partire dall’ultima cella T[n,C], una riga per volta; il costo è O(n)
La complessità di questo algoritmo è quindi O(nC).
problema dello zaino (knapsack problem)
traccia
Abbiamo uno zaino di capacità C e n oggetti, ognuno con peso pi e valore vi. Vogliamo sapere, dati la capacità C, i vettori P dei pesi e V dei valori, in Θ(nC) il valore massimo che si può inserire nello zaino.
Il problema del disco (visto sopra) è considerabile un caso particolare del problema dello zaino in cui peso = valore (= “dimensione"). È un noto problema NP-completo.
esempio
ragionamento
Si utilizza una matrice di dimensione (n+1)×(C+1) in cui:
T[i][j]= massimo valore ottenibile dai primi i oggetti per uno zaino di capacità j
indici di tabella e vettori
(teniamo a mente che peso e valore di un oggetto sono “sfasati” di 1 rispetto agli indici della tabella: infatti, nella tabella, T[i][j] rappresenta l’uso dei primi i oggetti, ma, poiché questi si indicizzano da 0, l’oggetto i-esimo è rappresentato da P[i−1] e V[i−1]
i=1 vuol dire “sto considerando il primo oggetto”, ovvero quello con peso P[0] e valore V[0])
Per compilare la tabella, sappiamo che:
se non si hanno oggetti o la capacità dello zaino è nulla, la soluzione varrà 0
se l’i-esimo oggetto ha peso superiore alla capacità dello zaino, non potrà essere inserito e il valore sarà dato dagli altri i−1 oggetti (con la stessa capacità), ovvero da T[i−1][j]
per ogni oggetto i da inserire nello zaino, ci sono due possibilità:
“lascio” ⟶ non inserisco l’oggetto nello zaino: il valore della soluzione è dato da T[i−1][j], ovvero il valore massimo ottenibile dai primi i−1 oggetti con la stessa capacità
“prendo” ⟶ inserisco l’oggetto nello zaino: in questo caso si guadagna V[i] in valore e bisogna sottrarre la capacità dell’oggetto inserito - rimane, per gli altri oggetti, una capacità di j−P[i]. Quindi, il valore della soluzione sarà dato da V[i−1]+T[i−1][j−P[i−1]]
Il valore da scegliere è quindi il massimo tra “prendo” e “lascio”:
def knapsack(P, V, c): n = len(P) T = [[0]*(c+1) for _ in range(n+1)] for i in range(1, n+1): for j in range(1, c+1): if j < P[i-1] T[i][j] = T[i-1][j] else: T[i][j] = max(T[i-1][j], V[i-1]+T[i-1][j-P[i-1]]) return T, T[n][c]
altri esercizi
contare il numero di stringhe binarie lunghe n senza 2 zeri consecutivi
per questo tipo di esercizi, è utile calcolare i primi valori e utilizzarli per dedurre il pattern generale (à la metodi matematici)
Qui abbiamo
n=0 ⟶ 1 stringa: stringa vuota ""
n=1 ⟶ 2 stringhe: 0 e 1
n=2 ⟶ 3 stringhe: 01, 10, 11
n=3 ⟶ 5 stringhe: 010, 011, 101, 111, 110
Utilizzeremo una tabella monodimensionale di dimensione n+1, il cui contenuto è definito come segue:
T[i]= numero di stringhe binarie lunghe i dove non compaiono 2 zeri consecutivi
T=1235
una volta riempita la tabella, la soluzione si troverà nella locazione T[n]
La ricorrenza si può dedurre separando il conteggio delle stringhe lunghe i che terminano con 1 da quelle che terminano con 0:
le stringhe lunghe i che terminano con 1 si ottengono dalle stringhe lunghe i−1senza vincoli (se in T[i−1] ci sono solo stringhe senza due zeri consecutivi, sicuramente aggiungendo un 1 questa proprietà sarà mantenuta) ⟶ esse sono quindi T[i−1]
le stringhe lunghe i che terminano con uno 0 hanno invece un vincolo: il carattere precedente (i−1) deve necessariamente essere un 1
quindi (vista in modo “combinatorio”) visto che abbiamo “fissato” i caratteri i−1 e i, le stringhe sono tutte le stringhe lunghe i−2, a cui viene aggiunto “10”
sono quindi T[i−2]
La ricorrenza è quindi:
T[i][j]=⎩⎨⎧12T[i−1]+T[i−2]i=0i=1altrimenti
notiamo che questo problema è analogo ai numeri di Fibonacci !
implementazione:
def duezeri(n): T = [0]*(n+1) T[0], T[1] = 1, 2 for i in range(2, n+1): T[i] = T[i-1] + T[i-2] return T[n]
contare il numero di stringhe binarie lunghe n senza 3 zeri consecutivi
Il problema è quindi molto simile a quello precedente.
Come prima, consideriamo i due casi: stringa lunga i che termina con un 1 e stringa lunga i che termina con uno 0.
le stringhe lunghe i che terminano con un 1 non hanno vincoli rispetto alle stringhe del passo precedente e sono quindi T[i−1]
per le stringhe lunghe i che terminano con uno 0, bisogna fare una distinzione
se il carattere i−1 è uno 0, allora i−2 deve necessariamente essere un 1 ⟶ le stringhe sono quindi T[i−3]
se i−1 è un 1, non ci sono vincoli su i−2 ⟶ sono T[i−2]
Dato un intero n, vogliamo sapere, in O(n), quante sono le sequenze di cifre decimali non decrescenti lunghe n.
per n=1, le cifre sono 10
per n=2 ⟶ 55 cifre
Infatti, alla prima cifra x possono seguire 10−x cifre diverse. Si ha quindi
x=0∑9(10−x)=i=1∑10i=210⋅11=55
ragionamento
Visto che dobbiamo considerare il constraint della non-decrescenza, dobbiamo tenere a mente non solo la lunghezza delle sequenze, ma anche con che numero terminano (per poter determinare se un numero possa essere aggiunto alla sequenza o no).
Sappiamo infatti che le stringhe lunghe i che terminano con j saranno formate da stringhe lunghe i−1 che terminano con qualunque cifra k≤j (a cui verrà aggiunto j).
Utilizziamo quindi una matrice definita così:
T[i][j]= numero di sequenze decimali non decrescenti lunghe i che terminano con la cifra j
La soluzione al problema sarà data quindi dalla somma degli elementi dell’ultima riga (sequenze non decrescenti lunghe n che terminano con tutte le cifre possibili)
il caso base è dato dalle sequenze lunghe 1 - ogni sequenza lunga 1 è infatti decrescente
La regola ricorsiva è quindi:
T[i][j]={1∑k=0jT[i−1][k]i=1altrimenti
implementazione:
def es(n): T = [[0]*10 for _ in range(n+1)] for j in range(10): T[1][j] = 1 for i in range(2, n+1): for j in range(10): for k in range(j+1): T[i][j] += T[i-1][k] return sum(T[n])
inizializzare la tabella costa Θ(n) (ha n+1 righe e 10 colonne)
dei 3 for annidati:
il primo viene iterato n volte
il secondo viene iterato 10 volte
il terzo viene iterato al più 10 volte
il costo totale dei for è Θ(n)
raggiungibilità in una matrice
testo
Data una matrice M binaria n×n, si vuole verificare, in Θ(n), se è possibile raggiungere la cella in basso a destra partendo da quella in alto a sinistra senza mai toccare celle che contengono il numero 1.
ad ogni passo ci si può spostare solo di un passo verso destra o un passo verso il basso
ragionamento
la cella M[0][0] è raggiungibile
se M[i][j]=1, non è raggiungibile
Assumendo che M[i][j]=0,
una cella della prima riga può essere raggiunta solo dalla cella che la precede (non ha una cella sopra di sé)
una cella della prima colonna può essere raggiunta solo dalla cella che sopra di sé sulla colonna (non ha una cella alla sua sinistra)
una cella “interna” è raggiungibile se può essere raggiunta dalla cella che la precede o dalla cella sopra di sé
Possiamo quindi utilizzare una matrice T di booleani, in cui T[i][j]==1⟺M[i][j] è raggiungibile.
def perc(M): n = len(M) T = [[0]*n for _ in range(n)] for i in range(n): for j in range(n): if i == j == 0: T[i][j] = 1 continue sopra = T[i-1][j] if i != 0 else 0 sx = T[i][j-1] if j != 0 else 0 T[i][j] = sopra or sx return T[n][n]
sottomatrici di soli uni
testo
Data una matrice quadrata binaria M di dimensione n×n, si vuole sapere, in O(n2), qual è la dimensione massima per le sottomatrici quadrate di soli uni contenute in M.
Si può utilizzare una tabella bidimensionale n×n dove:
T[i][j]= il lato della matrice quadrata più grande contenente tutti uni e con cella in basso a destra M[i][j]
ragionamento
Il ragionamento è questo:
se M[i][j]=0, T[i][j]=0
altrimenti, per avere un quadrato di dimensione k, gli elementi della matrice T[i−1][j], T[i−1][j−1] e T[i][j−1] (sopra, diagonale, sinistra) dovranno a loro volta essere gli angoli di un quadrato di dimensione almeno k−1
Si può osservare in questo caso:
1111111111111101101111111
per il primo quadrato (giallo, che termina in [1][1]), è abbastanza evidente: le celle che lo circondano formano quadrati 1×1
ma si nota anche per [2][2] (rosso): infatti, ai tre quadrati 2×2 formati dalle celle circostanti manca esattamente l’ultima cella per diventare un unico quadrato 3×3
(si prende il minimo lato perché, per poter “fondere” i tre quadrati che terminano in quelle tre celle, essi devono essere della stessa dimensione: se si prendesse il massimo, uno degli altri due quadrati potrebbe essere più piccolo e la figura risultante non sarebbe un quadrato - il minimo, invece, li “copre” sicuramente tutti e tre)
implementazione:
def sottomatrice(M): T = [[0]*n for _ in range(n)] T[0][0] = M[0][0] for i in range(n): for j in range(n): if M[i][j] == 0: T[i][j] = 0 else: if i == 0 or j == 0: T[i][j] = 1 else: T[i][j] = min(T[i][j-1], T[i-1][j-1], T[i-1][j]) + 1 return max(T)
numeri di Strirling di seconda specie
testo
Dati due interi non negativi n e k, vogliamo sapere, in Θ(n⋅k) in quanti modi è possibile partizionare l’insieme dei numeri da da 1 a n in k sottoinsiemi non vuoti.
ragionamento
Possiamo usare una tabella bidimensionale di dimensioni (n+1)(k+1), in cui:
T[i][j]= numero di modi di partizionare i elementi in j sottoinsiemi non vuoti
Sappiamo che:
T[0][0]=1
non c’è modo di partizionare i>0 elementi in 0 parti oppure 0 elementi in j>0 parti, quindi si ha T[i][0]=T[0][j]=0
negli altri casi, si possono contare i modi di partizionare pensando all’i-esimo elemento:
se si sceglie di tenere l’i-esimo elemento da solo, si avranno T[i−1][j−1] modi (i modi di creare i sottoinsiemi considerando tutti gli altri elementi e un sottoinsieme in meno)
se si sceglie di inserire l’i-esimo elemento in un sottoinsieme con almeno un altro elemento, si avranno j⋅T[i−1][j] modi di farlo
T[i−1][j] sono i modi per partizionare i−1 elementi in j sottoinsiemi
il nuovo elemento (i) può essere messo in uno qualsiasi dei sottoinsiemi creati, quindi bisogna moltiplicare i modi per il numero di sottoinsiemi creati, ovvero j
def es(n, k): T = [[0]*(k+1) for _ in range(n+1)] T[0][0] = 1 for i in range(1, n+1); for j in range(1, k+1): T[i][j] = T[i-1][j-1] + j*T[i-1][j] return T[n][k]