Un sistema operativo deve allocare risorse tra diversi processi che ne fanno richiesta contemporaneamente: tra le risorse, c’è il processore (e quindi il tempo di esecuzione). Questa risorsa viene allocata tramite lo scheduling.
qual è lo scopo dello scheduling?
- assegnare ad ogni processore i processi da eseguire, man mano che questi vengono creati e distrutti
- va fatto ottimizzando vari aspetti:
- tempo di risposta
- throughput (portare a termine più processi nella stessa unità di tempo)
- efficienza del processore
- non fare favoritismi tra processi (con stessa priorità) ma gestire la priorità dei processi quando necessario
- evitare la starvation dei processi
- usare il processore in modo efficiente
- avere un overhead basso (overhead = lavoro fatto in più - lo scheduler deve essere veloce ed efficiente)
tipi di scheduling
Ci sono diversi tipi di scheduling (a seconda di quanto spesso vengono eseguiti)
- long-term (eseguito molto di rado) - decide l’aggiunta ai processi da essere eseguiti
- medium-term (eseguito ogni tanto)- decide l’aggiunta ai processi in memoria principale
- short-term - decide quale processo va eseguito tra quelli pronti
- I/O - decide a quale processo assegnare un dispositivo I/O, tra quelli che lo stanno richiedendo
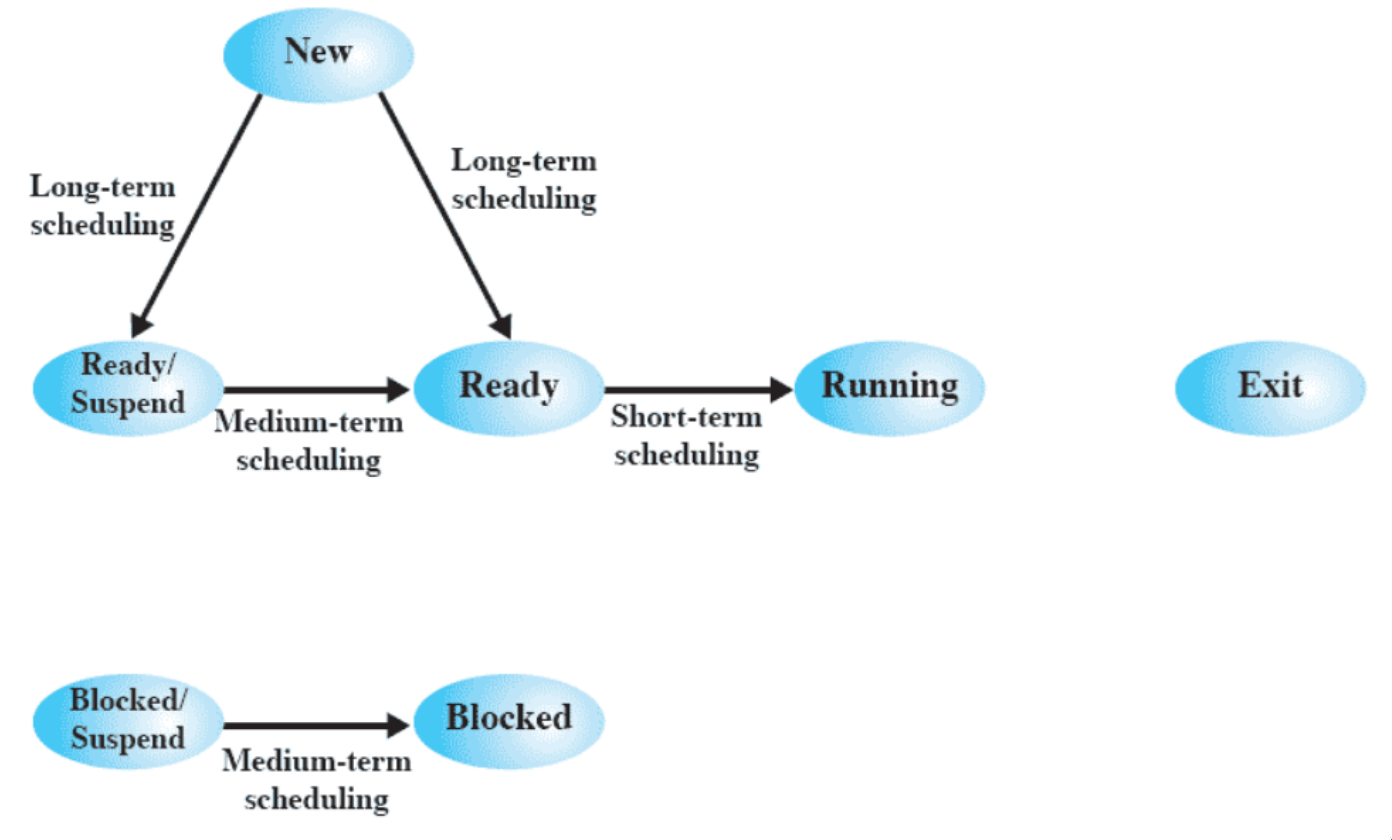
stati dei processi e scheduling
molte delle transizioni del modello a sette stati sono dovute a uno scheduler.
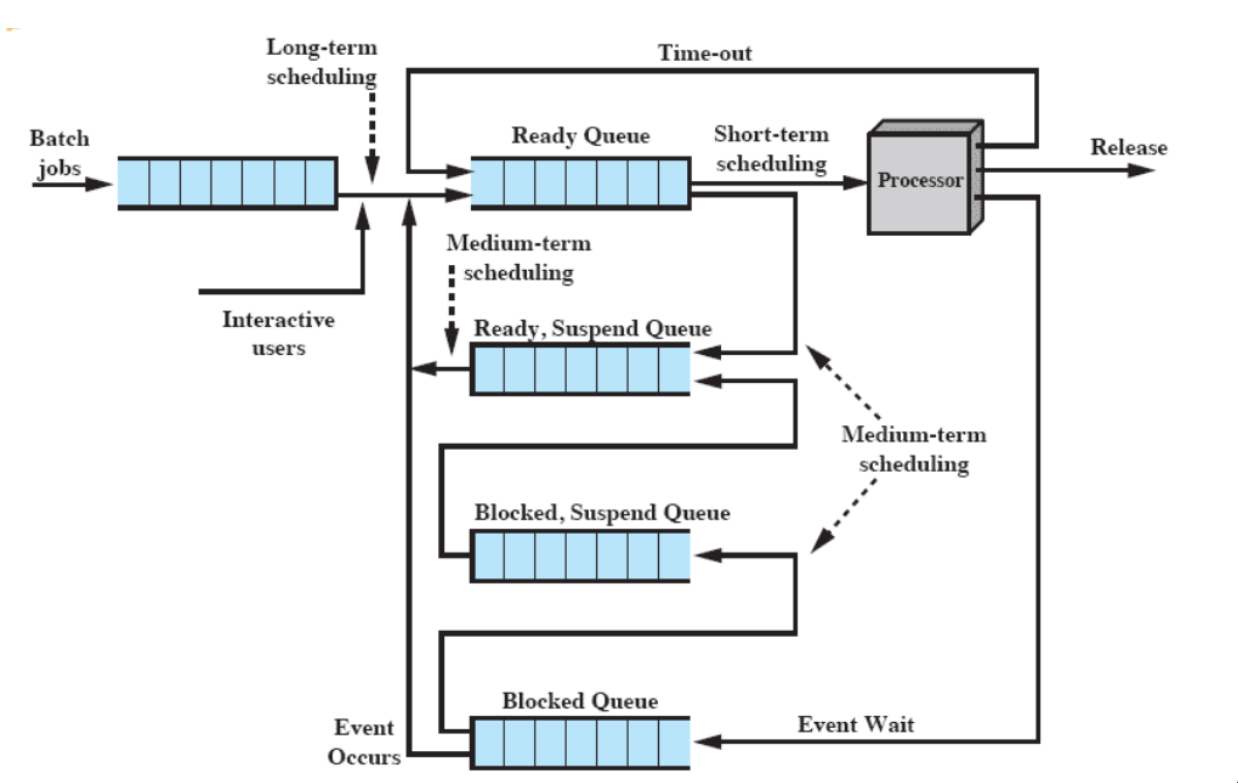
long-term scheduling
spesso è FIFO. Altrettanto spesso, è FIFO con delle condizioni: priorità, requisiti I/O, o tempo di esecuzione atteso.
- controlla il grado di multiprogrammazione (e decide se mettere un processo in RAM o su disco)
- può essere chiamato in causa anche quando non ci sono nuovi processi (es. quando termina un processo o quando processi sono idle da troppo tempo)
tipiche strategie:
- i lavori batch (non interattivi) vengono accodati e il LTS li prende man mano che ritiene giusto
- i lavori interattivi vengono ammessi fino a che non si satura il sistema
- se si sa quali sono I/O-bound e quali CPU-bound (usano molto I/O o CPU), può mantenere un mix tra i due tipi
medium-term scheduling
è parte della funzione di swapping dei processi (passaggio da memoria secondaria a principale e viceversa)
- l’obiettivo principale è gestire il grado di multiprogrammazione
short-term scheduler
chiamato anche dispatcher. Eseguito più frequentemente, sulla base di eventi (interruzioni di clock o I/O, syscalls, segnali). Il suo scopo è allocare tempo di esecuzione su un processore per ottimizzare il comportamento dell’intero sistema, in base a determinati indici prestazionali.
criteri utente e sistema
Occorre distinguere i criteri per lo short term scheduling in utente e di sistema.
I criteri per l’utente sono quelli che un singolo utente può apprezzare (es. tempo di risposta), mentre quelli per il sistema sono legati all’uso efficiente di un procesore.
criteri prestazionali e non
Un’altra distinzione che occorre fare è tra criteri correlati e non correlati alle prestazioni. Quelli prestazionali sono quelli quantitativi e facili da misurare. Quelli non prestazionali sono qualitativi e molto più difficili da misurare.
criteri utente:
prestazionali:
- turnaround time (tempo di ritorno) - tempo tra la creazione di un processo e il suo completamento. (di solito si parla di batch)
- response time - tempo tra la sottomissione di una richiesta e l’inizio della risposta (processi interattivi) - duplice obiettivo dello scheduler: minimizzare il tempo medio, o massimizzare il numero di utenti con un buon tempo di risposta.
- deadline - massimizzare il numero di scadenze rispettate
non prestazionali:
- predictability - non deve esserci troppa variabilità nei tempi di risposta e/o ritorno
criteri di sistema:
prestazionali:
- throughput (volume di lavoro nel tempo) - massimizzare il numero di processi completati per unità di tempo
- processor utilization - percentuale di tempo in cui il processore viene utilizzato - il processore deve essere idle il minor tempo possibile
non prestazionali:
- fairness - se non ci sono indicazioni dall’utente o dal sistema, tutti i processi devono essere trattati allo stesso modo
- enforcing priorities - se ci sono priorità, lo scheduler deve favorire processi a priorità più alta
- balancing resources - lo scheduler deve far sì che le risorse del sistema siano usate il più possibile - dovranno essere favoriti processi che useranno meno le risorse attualmente più usate
priorità e starvation
Un processo a bassa priorità potrebbe soffrire di starvation a causa di un altro processo a priorità più alta.
- Soluzione: man mano che l‘“età” aumenta (o anche sulla base di quante volte sarebbe potuto andare in esecuzione), la priorità cresce
politiche di scheduling
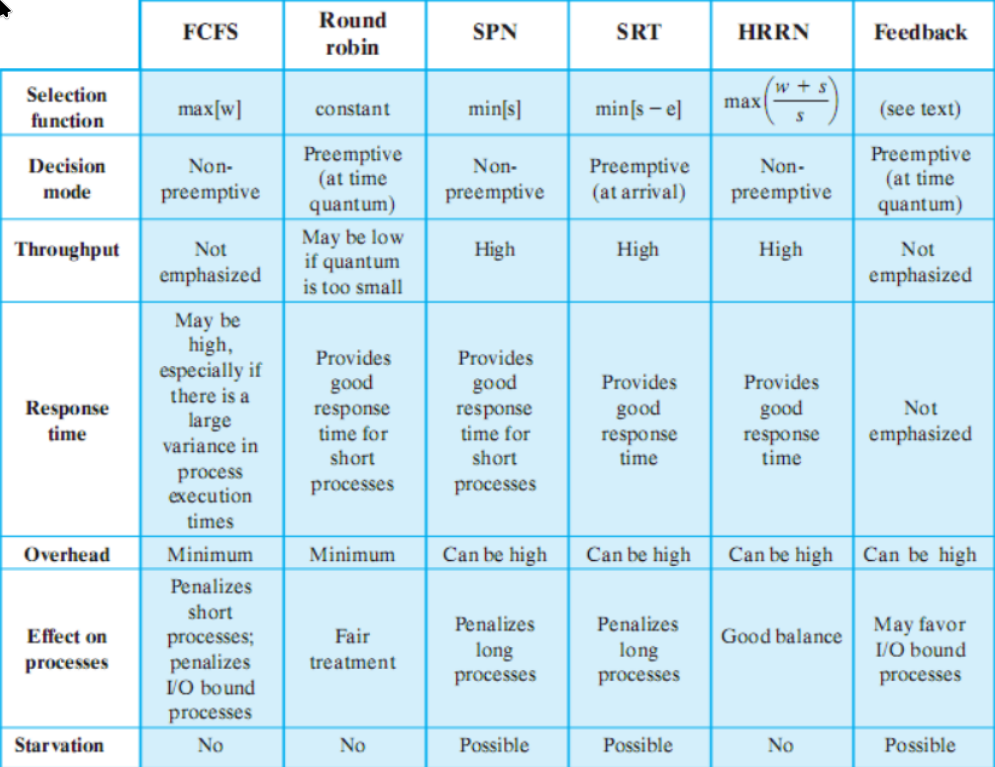
funzione di selezione
è quella che sceglie il processo da mandare in esecuzione.
Si basa tipicamente su alcuni parametri:
- w(ait) = tempo trascorso in attesa
- e(xecution) = tempo trascorso in esecuzione
- s = tempo totale richiesto (incluso quello già servito - e) (viene o stimato, o fornito come input)
modalità di decisione
specifica in quali istanti di tempo la funzione di selezione viene invocata. Può essere:
- non-preemptive - se un processo è in esecuzione, o arriva fino a terminazione, o fa una richiesta bloccante (quindi resta in esecuzione se non fa chiamate bloccanti)
- preemptive - il dispatcher può interrompere un processo in esecuzione “liberamente” - (se non è terminato o blocked), il processo diventa
ready- la preemption può avvenire per diversi motivi: o sono arrivati nuovi processi appena creati, o per un interrupt (di I/O, o di clock, per evitare che un processo monopolizzi il sistema)
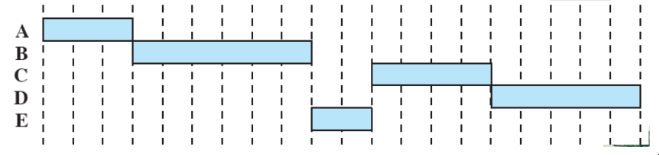
esempi classici su un esempio comune
Abbiamo 5 processi batch, ABCDE, che arrivano a distanza di due unità di tempo.
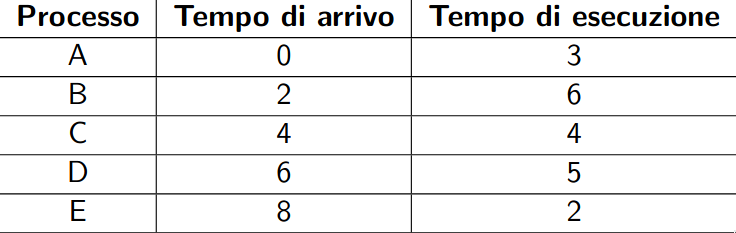
first come first served
- non-preemptive
- tutti i processi vengono aggiunti alla coda dei
ready - quando un processo smette di essere eseguito, si passa al processo che ha aspettato di più nella coda (FIFO)
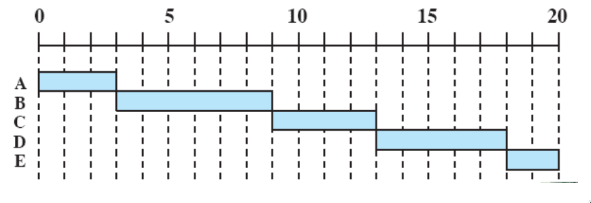
problemi:
- un processo corto potrebbe attendere molto prima di essere eseguito (es. E)
- favorisce i processi molto CPU-bound (che non verranno rilasciati fino alla loro terminazione)
round-robin
- preemptive, si basa su un clock
- ogni processo ha una fetta di tempo - in ordine di arrivo (FIFO), hanno un’unità di clock a testa
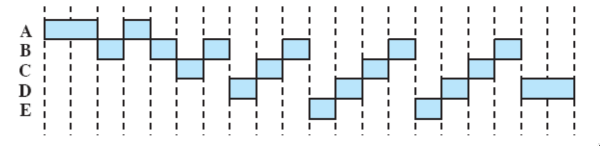
- un’interruzione di clock viene generata periodicamente - quando arriva, il processo attualmente in esecuzione viene rimesso nella coda dei
readye il prossimo viene selezionato tra quelli già ready (se la coda è vuota, il processo rimane in esecuzione)
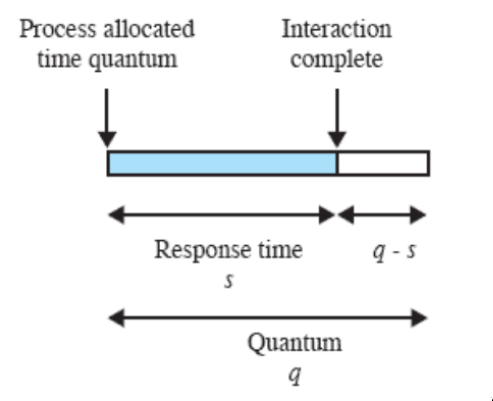
Quanto lungo deve essere il quanto di tempo?
- Il round robin funziona bene se il quanto è non troppo più grande del tipico tempo di interazione di un processo:
- invece, se il quanto di tempo è minore del tempo di risposta, diventa non ottimale:
- al processo viene sottratto il processore prima che riesca a computare la risposta, e il tempo di risposta per il processo si allunga
ma:
- se il quanto è troppo lungo, si rischia di degenerare in FCFS
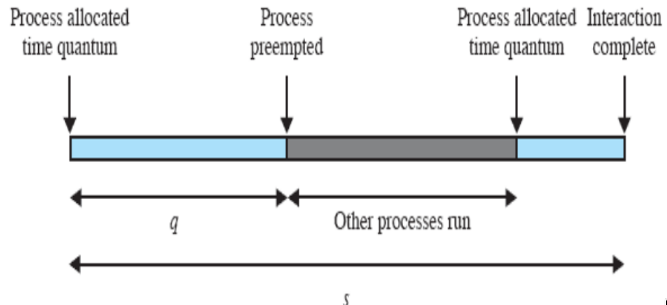
quindi, quando si sceglie il round robin, è necessario studiare i tempi di risposta e scegliere bene il quanto.
CPU-bound vs IO-bound
anche il round-robin favorisce i processi CPU-bound: il quanto di tempo di un processo viene usato del tutto (o quasi) - mentre i processi I/O-bound ne usano solo la porzione fino alla richiesta di I/O
- soluzione: round-robin virtuale se un processo fa una richiesta bloccante (es. I/O), quando la richiesta viene esaudita, il processo non va in una coda di ready - ma esiste un’altra coda, la coda ausiliare, usata per i processi per i quali una richiesta bloccante è appena stata esaurita. Il dispatcher sceglie quindi prima dalla auxiliary queue (mandando in esecuzione solo per il tempo che rimaneva al quanto di quei processi), e, solo se questa è vuota, passa alla ready queue.
shortest process next (SPN)
- richiede che i processi forniscano la propria durata, o che questa venga stimata
- il prossimo processo da mandare in esecuzione è quello più breve = il cui tempo di esecuzione stimato è minore
- senza preemption
- i processi lunghi potrebbero soffrire di starvation
- il tempo di esecuzione è stimato, e se viene stimato erroneamente il sistema operativo può abortire il processo
come stimare il tempo di esecuzione?
in alcuni sistemi ci sono processi che sono eseguiti svariate volte
si può usare il passato () per predire il futuro (): questa è una media - ma per calcolarla, servirebbe mantenere n valori. ma si può fare anche: così basta tenere l’ultimo valore e la stima precedente.
ma sarebbe meglio far pesare di più le istanze più recenti: (se chiamo 1/n alpha noto che:) e notiamo che è equivalente a: che è l’exponential averaging. Quindi, usando degli fissati (invece che dipendenti da n), la stima è molto più vicina ai tempi reali di una semplice media.
shortest remaining time (SRT)
- come SPN, ma preemptive:
- un processo può essere interrotto solo quando ne arriva uno nuovo, appena creato
- stima il tempo rimanente richiesto per l’esecuzione, e prende quello più breve
Highest Response Ratio Next (HRRN)
- risolve anche il problema della starvation
- non preemptive
- massimizza il rapporto:
scheduling tradizionale di unix
- lo scheduling tradizionale di UNIX si basa sui concetti di priorità e round-robin
- un processo resta in esecuzione per massimo un secondo (a meno che non termini o si blocchi)
- i processi sono organizzati in diverse code in base alla priorità, e all’interno di esse si fa round-robin
- la priorità viene ricalcolata ogni secondo: più un processo rimane in esecuzione, meno priorità ha:
- le priorità iniziali sono:
- swapper (alta)
- controllo di dispositivo I/O a blocchi (dischi)
- gestione di file
- controllo di dispositivo a caratteri
- processi utente
- le priorità iniziali sono:
La priorità viene calcolata con le formule:
- misura quanto il processo j ha usato il processore nell’intervallo i (con exponential averaging dei tempi passati)
- è la priorità del processo all’inizio di (valore basso = priorità alta)
- è la priorità iniziale (da 0 a 4, con swapper = 0)
- - (ricordiamo che se è alto, la priorità è bassa) - è un valore di “cortesia” che un processo può auto-settare a un valore > 0 per far passare avanti altri processi
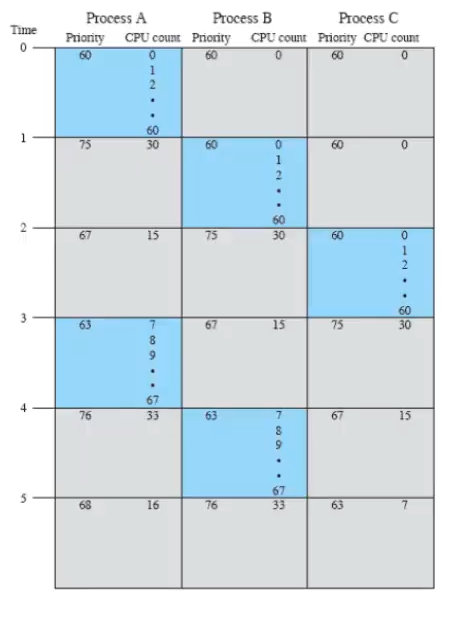
esempio
Supponiamo che ci siano 3 processi utente con stessa priorità e nice=0. Inizialmente, tutti hanno priority 60.
- Lo scheduler sceglie quindi A (il primo).
- I processi non in esecuzione mantengono il CPU-count a 0, mentre A lo incrementa di 1 ogni 1/60 (fino a 60).
- Quando arriva l’interrupt e lo scheduler deve scegliere tra A, B e C, per A il 60 diventa 30 (per la formula e la priorità quindi 75 (per ).
- Quindi, lo scheduler sceglie B (o C, è indifferente) e succede la stessa cosa: C, a fine secondo, avrà priorità 75.
- Il processo A, intanto, essendo rimasto fermo, divide per 2 il 30 () e riapplica - la sua priorità diventa 67
- Va in esecuzione C (che ha la priorità minore)
e si va avanti così fino al termine dei processi
architetture multiprocessore
Le cose dette sopra valgono per le architetture con un solo processore. Come si fa per quelle multiprocessore?
Esistono diversi tipi di architetture multiprocessore:
- cluster - multiprocessori con memoria non condivisa (connessione con rete locale superveloce)
- processori specializzati - ad esempio, ogni I/O ha il suo processore
- multiprocessore o multicore - condividono la RAM, un solo sistema operativo controlla tutto
Noi ci concentreremo sulle architetture multicore.
qual è la questione
Ho dei processi ready, e non devo più solo decidere quale mandare in esecuzione, ma anche quale processo va su quale processore - assegnamento.
Ci sono due possibilità: assegnamento statico o dinamico.
-
assegnamento statico
- quando un processo viene creato, gli viene assegnato un processore, che manterrà per tutta la sua esecuzione
- si può usare uno scheduler per ogni processore
- vantaggi: semplice da realizzare, poco overhead
- svantaggi: un processore potrebbe rimanere idle (mentre altri hanno molti processi)
-
assegnamento dinamico
- un processo, nel corso della sua vita, può essere eseguito su diversi processori
- complicato da realizzare:
- con Sistema Operativo su un processore fisso:
- più semplice, solo i processi utenti possono “vagare”
- il processore del sistema operativo può avere più carico degli altri (diventare il “bottleneck”)
- se il processore del SO fallisce, fallisce tutto
- con Sistema operativo sul processore che capita
- flessibile, ma richiede più overhead per gestire la mobilità del SO
- con Sistema Operativo su un processore fisso:
scheduling in linux
(è cambiato varie volte da quando linux esiste)
- non esistono long-term (i processi creati sono subito ready) o medium-term (non esistono i processi suspended) scheduler, perché Linux cerca la massima velocità di esecuzione tramite semplicità
- c’è un embrione del long-term (caso limite: quando creo un nuovo processo, il sistema è già saturo, e questo scheduler non lascia che il processo sia creato - la syscall fallisce -)
Esistono le wait queues (plurale perché ci sono diverse code per evento che si attende) e le runqueues (plurale perché ci sono diverse code per diverse priorità):
- waitqueues - code dei blocked
- in un’architettura multiprocessore, sono condivise tra tutti i processori
- runqueues - code dei ready
- in un’architettura multiprocessore, ogni processore ha la propria
Lo scheduling è quindi derivato da quello di Unix - è preemptive a priorità dinamica. Ci sono però correzioni per:
- essere veloce ed operare in tempi quasi costanti
- servire nel modo appropriato i processi real-time
Linux si fa mandare un interrupt ogni 1ms. Quindi, il quanto di tempo per ciascun processo all’interno delle varie priorità è un multiplo di 1ms.
Per capire qual è il tempo, bisogna capire che tipi di processi Linux consideri:
tipi di processi in Linux
- interattivi
- non appena si agisce sul mouse o sulla tastiera (per una risposta veloce), è importante dare il controllo al processo in max
150ms- vanno quindi favoriti
- batch
- tipicamente penalizzati dallo scheduler (es. compilazioni)
- real-time
- dichiarati esplicitamente come tali (mentre per batch e interattivi, Linux cerca di capire la loro categoria) se il loro codice usa la syscall
sched_setscheduler(es. audio/video)Tutti questi possono essere sia CPU-bound che I/O-bound
classi di scheduling
Ci sono 3 classi di scheduling:
- per i processi real-time,
SCHED_FIFOeSCHED_RR(round-robin) - per tutti gli altri,
SCHED_OTHER
Prima si eseguono i processi in SCHED_FIFO e SCHED_RR (priorità da 1 a 99), e solo dopo quelli in SCHED_OTHER (priorità da 100 a 130)
- la priorità 0 viene usata per casi particolari
Ci sono quindi 140 runqueues per ogni processore.
Lo scheduler, per decidere chi mandare in esecuzione, considera prima il livello 0, poi 1, poi 2 ecc…
- e, può passare dal livello a solo se o non ci sono processi in , o nessun processo in è nello stato
RUNNING(ready)
La preemption per SCHED_OTHER può avvenire in due casi:
- si esaurisce il quanto di tempo del processo in esecuzione (di solito nel round robin c’è solo questa condizione)
- un altro processo passa dagli stati blocked a
RUNNING(serve per poter servire il prima possibile i processi interattivi)- molto spesso, quel processo sarà quindi effettivamente eseguito
regole generali
Un processo
SCHED_FIFOviene preempted solo se:
- si blocca per I/O o lascia volontariamente la CPU
- un altro processo passa da blocked a
RUNNINGe ha priorità più alta(quindi, i processi in
SCHED_FIFOdevono essere pochi, importanti e veloci)Tutti gli altri processi vanno a quanto di tempo, compreso
SCHED_RR.
- i processi real-time non cambiano mai la priorità (o fanno chiamate bloccanti o lasciano la CPU), mentre quelli
SCHED_OTHERsì (in maniera simile a UNIX)- per sistemi con CPU multiple, c’è una routine periodica che ridistribuisce il carico se necessario