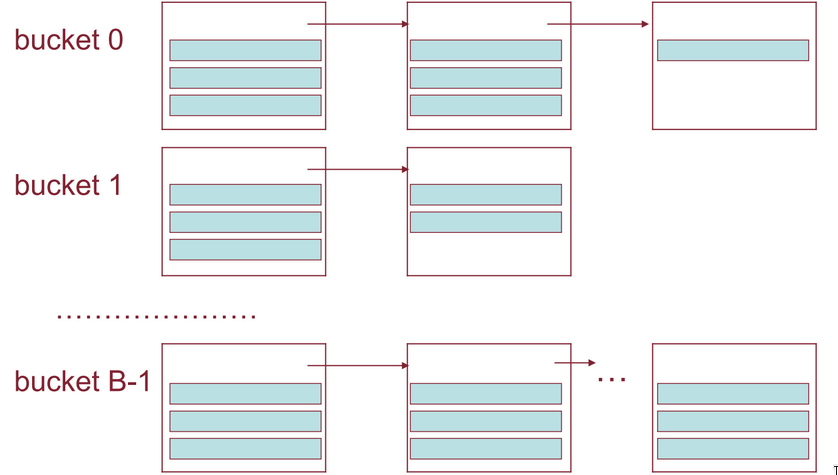
il file è suddiviso in bucket numerati da 0 a .
- ciascun bucket è costituito da uno o più blocchi collegati tramite puntatori, ed è organizzato come un heap
bucket directory
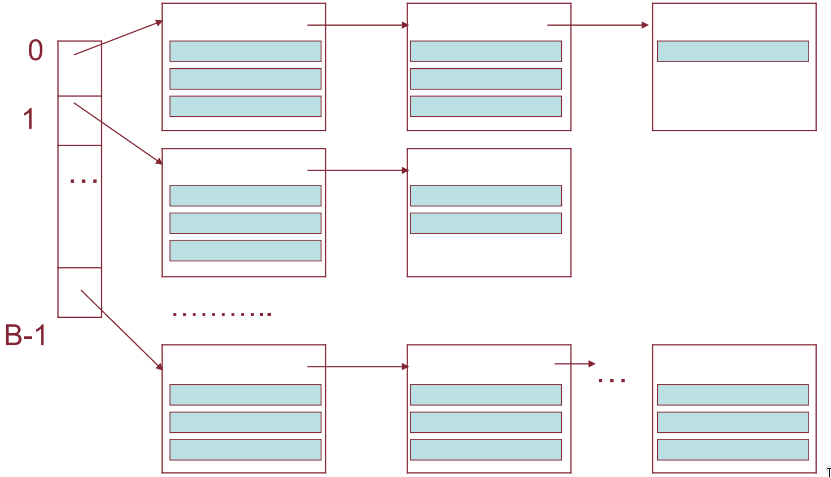
L’accesso ai bucket avviene attraverso la bucket directory, che contiene elementi. L’i-esimo puntatore contiene l’indirizzo (bucket header) del primo blocco dell’i-esimo bucket.
funzione hash
Il numero del bucket in cui deve trovarsi un record con chiave v è calcolato tramite una funzione hash h(v), che restituisce un valore da 0 a (sicuramente si userà quindi )
operazioni
Una qualsiasi operazione su un file hash richiede:
- la valutazione di h(v) per individuare il bucket
- l’esecuzione dell’operazione sul bucket, che è organizzato come un heap
Poiché l’inserimento di un record viene effettuato sull’ultimo blocco del bucket (perché ogni bucket è una heap), è opportuno che la bucket directory contenga anche, per ogni bucket, un puntatore all’ultimo record del bucket.
costo operazioni
Se la funzione hash distribuisce uniformemente i record nei bucket, ogni bucket è costituito da blocchi, e quindi
- il costo richiesto di un’operazione è approssimativamente 1/B-esimo del costo dell’operazione se il file fosse organizzato come una heap
funzione hash
Una buona funzione hash deve ripartire uniformemente i record nei bucket, cioè, al variare della chiave, deve assumere con la stessa probabilità uno dei valori compresi tra 0 e B-1.
In genere, una funzione hash trasforma la chiave in un intero, lo divide per B e usa il resto della divisione come numero del bucket in cui deve trovarsi il record.
considerazioni
Appare evidente che quanti più sono i bucket, tanto più è basso il costo di un’operazione. Ma il numero di bucket è limitato dalle seguenti considerazioni:
- ogni bucket deve avere almeno un blocco
- conviene che la bucket directory sia contenuta in memoria principale, o saranno necessari ulteriori accessi per leggere il suo contenuto
esempi
esempio 1
abbiamo i seguenti dati:
- il file contiene 250.000 record ⇒
- ogni record occupa 300 byte ⇒
- il campo chiave occupa 75 byte (“trappola” - è un dato inutile per questo tipo di organizzazione) ⇒
- ogni blocco contiene 1024 byte ⇒
- un puntatore a un blocco occupa 4 byte ⇒
a) Se usiamo un’organizzazione hash con 1200 bucket (), quanti blocchi occorrono per la bucket directory ?
Indichiamo con il numero di bucket e con il numero di blocchi per la bucket directory (array di puntatori indicizzato da a ).
- quanti puntatori entrano in un blocco?
(dimensione blocco/dimensione puntatore) - parte intera inferiore perché devono essere contenuti interamente
- quanti blocchi ci servono per la bucket directory? e per il file hash?
- parte superiore perché i blocchi vengono allocati interamente
b) Quanti blocchi occorrono per i bucket, assumendo una distribuzione uniforme dei record nei bucket?
supponiamo di non avere un direttorio di record all’inizio del blocco (e quindi che tutto lo spazio sia occupato dai dati). serve però un puntatore per ogni blocco per linkare i blocchi dello stesso bucket.
In un blocco dobbiamo quindi memorizzare il maggior numero possibile di record + un puntatore per un eventuale prossimo blocco nel bucket. Abbiamo due modi per calcolare il massimo numero di record per blocco:
Sappiamo che , ovvero il massimo numero di record x la dimensione di un record con aggiunto il puntatore deve essere minore o uguale della dimensione di un blocco (sono tutte le informazioni che inseriamo in un blocco) Quindi, . Sappiamo che deve essere intero (i record non possono stare a cavallo), quindi possiamo assumere
possiamo anche sottrarre la taglia del puntatore dallo spazio utilizzabile in un blocco e prendere la parte intera inferiore della divisione dello spazio rimanente per la taglia dei record -
se il blocco ha un puntatore al blocco precedente nella diseguaglianza)
in questo caso devo sottrarre lo spazio di un altro puntatore da quello disponibile (o moltiplicare per due
Se la distribuzione dei record nei bucket è uniforme, avremo ovvero numero di record in un bucket =
Occorrono quindi blocchi per bucket (ho record “totali” in un bucket da distribuire in diversi blocchi)
Per trovare il numero di blocchi necessario per il file hash, basta moltiplicare il numero di blocchi necessari per un bucket per il numero di bucket:
- qual è il costo medio della ricerca?
Se la distribuzione è uniforme, visto che la ricerca avviene solo sul bucket individuato dalla fuzione hash, (avremo un numero di accessi pari a quello che si avrebbe su un heap della stessa dimensione del bucket) accederemo in media alla metà dei blocchi di un bucket. Avremo quindi
- quanti bucket dovremmo creare per avere un numero medio di accessi a blocco ⇐ 10, assumendo comunque una distribuzione uniforme?
Dobbiamo riscrivere l’espressione di in modo che compaia esplicitamente il numero di bucket (tralasciando gli arrotondamenti). Avremo quindi . Dobbiamo calcolare in modo tale che , ovvero . Nel nostro caso, avremmo .
Si può anche ragionare in un altro modo: sappiamo che , quindi, per avere , dobbiamo avere (con numero di blocchi in un bucket). Quindi, dobbiamo avere , quindi . Perché sia possibile, serve e quindi
domande orale
possibili domande orale
- struttura file hash
- cosa deve fare una “buona” funzione hash?
- costo delle operazioni su un file hash