routing
Il routing si occupa di trovare il miglior percorso per un pacchetto e di inserirlo nella tabella di routing (o tabella di forwarding).
routing vs forwarding
Quindi, il routing costruisce le tabelle che vengono poi usate dal forwarding (che colloca fisicamente il datagramma sulla giusta porta di uscita del router)
Una rete di calcolatori si può rappresentare tramite grafo pesato.
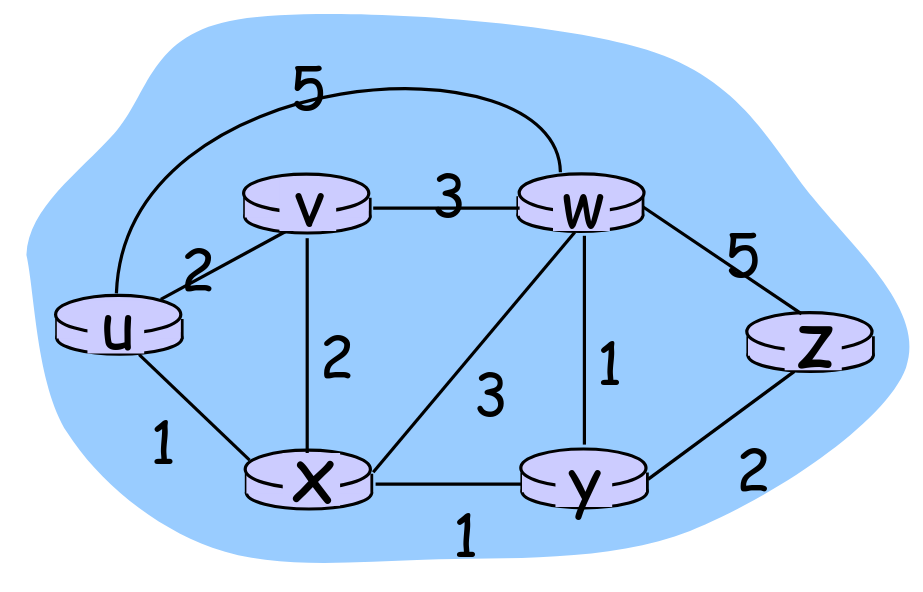
- un path nel grafo è una sequenza di nodi tale che ognuna delle coppie sono archi in
- è il costo del collegamento
- il costo di un cammino è la somma di tutti gli archi che lo compongono
Il costo di un cammino può rappresentare:
- lunghezza fisica del collegamento
- velocità del collegamento
- costo monetario associato al collegamento
In un grafo di una rete di calcolatori, il cammino a costo minimo tra due nodi si calcola con un algoritmo di instradamento.
algoritmo distance vector
È un algoritmo:
- distribuito ⟶ ogni nodo riceve informazioni dai vicini e opera su quelle
- asincrono ⟶ non richiede che tutti i nodi operino al passo con gli altri
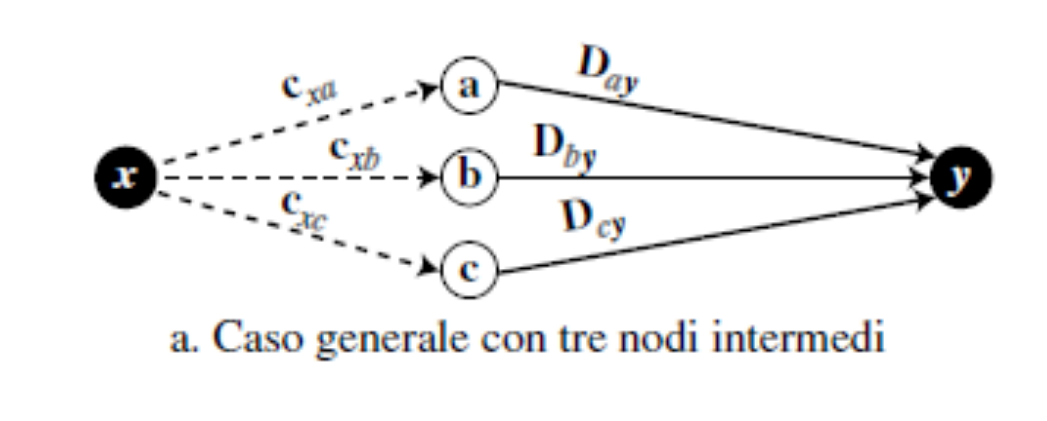
L’algoritmo DV si basa sull’equazione di Bellman-Ford [ lezione di progettazione di algoritmi su Bellman-Ford ]. Essa definisce:
in cui:
- (dove riguarda tutti i vicini di )
- ovvero: si considera quanto costano gli archi da a ciascun vicino , e si sceglie il percorso che, passando per , ha il costo totale (fino a ) che sia minimo
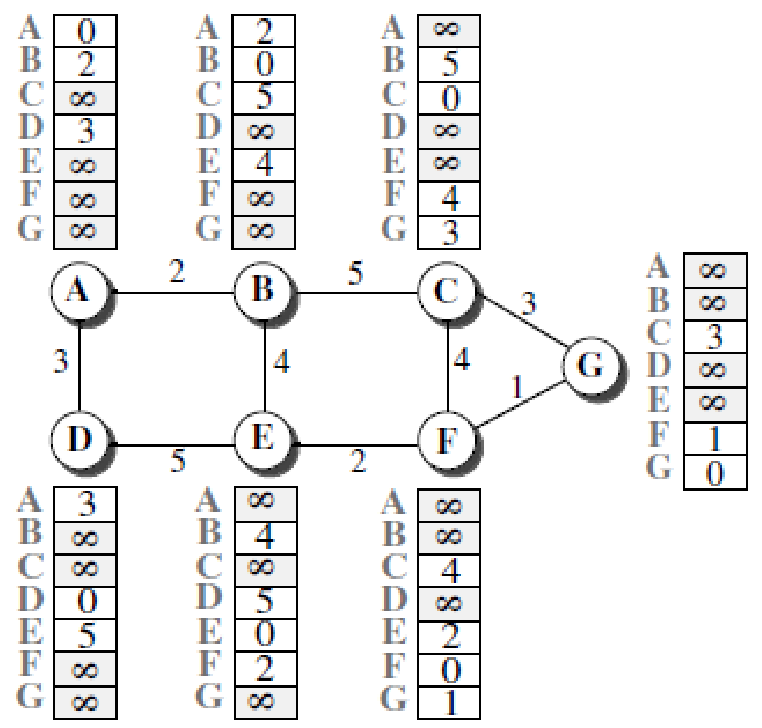
esempio
Si ha:
- (in cui , , sono percorsi a costo minimo precedentemente calcolati)
vettore distanza, minimum spanning tree
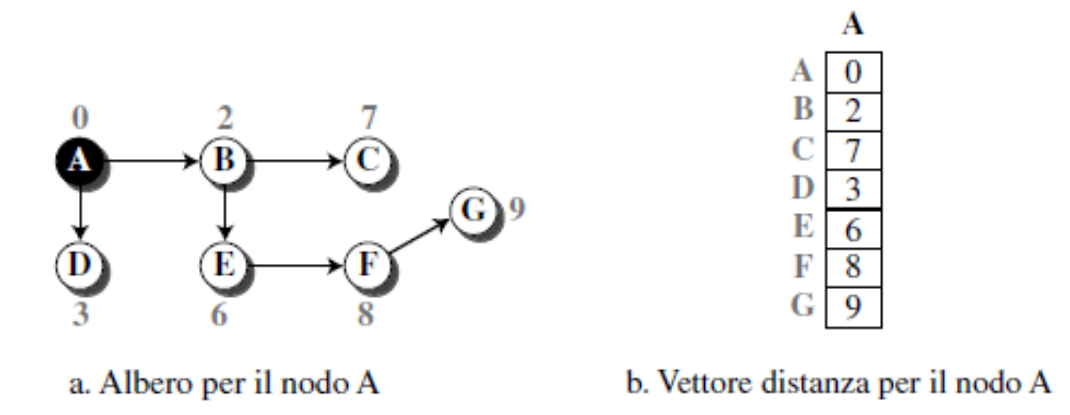
albero a costo minimo
Un albero a costo minimo (minimum spanning tree) è una combinazione di percorsi a costo minimo dalla radice dell’albero verso tutte le destinazioni [ praticamente analogo al minimo albero di copertura (prog. di algo) ]
- il vettore di distanza è un array monodimensionale che rappresenta l’albero
non fornisce il percorso da seguire per giungere alle destinazioni, ma solo i costi minimi
esempio
Quando viene inizializzato un nodo, si crea un vettore distanza iniziale con le informazioni che il nodo ottiene dai suoi vicini
- per crearlo, il nodo invia messaggi di
helloattraverso le sue interfacce (e i vicini fanno lo stesso), e scopre l’identità dei suoi vicini e la distanza da ognuno di essi - dopo che ogni nodo ha creato il suo vettore, ne invia una copia ai suoi vicini
- quando un nodo riceve un vettore distanza da un suo vicino, aggiorna il suo vettore distanza applicando l’equazione di Bellman-Ford
esempio
- riceve una copia del vettore di
- riceve una copia del vettore di
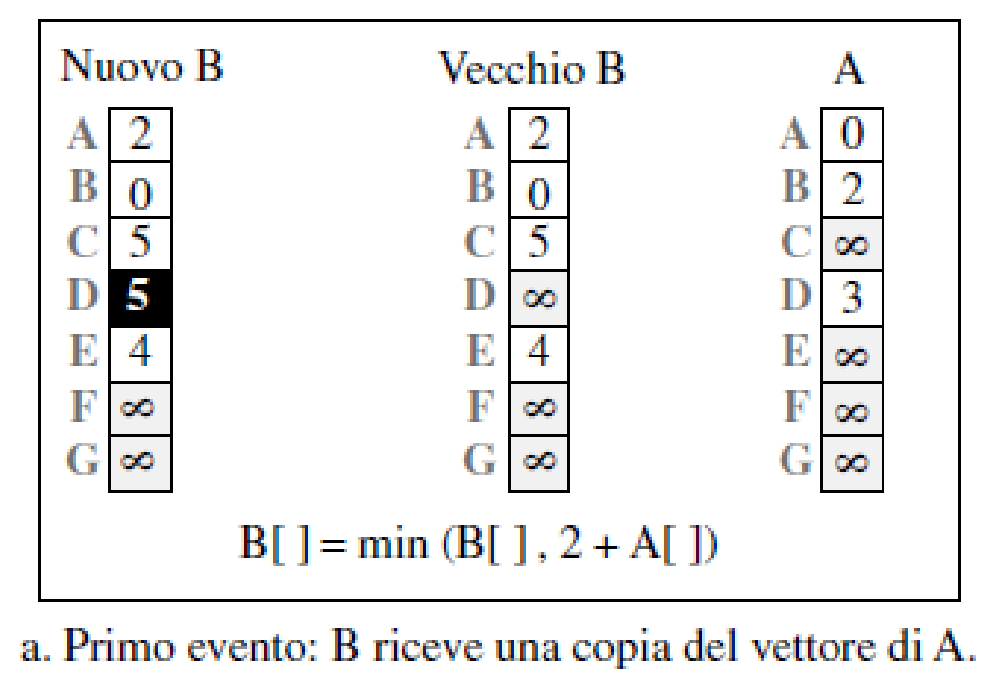
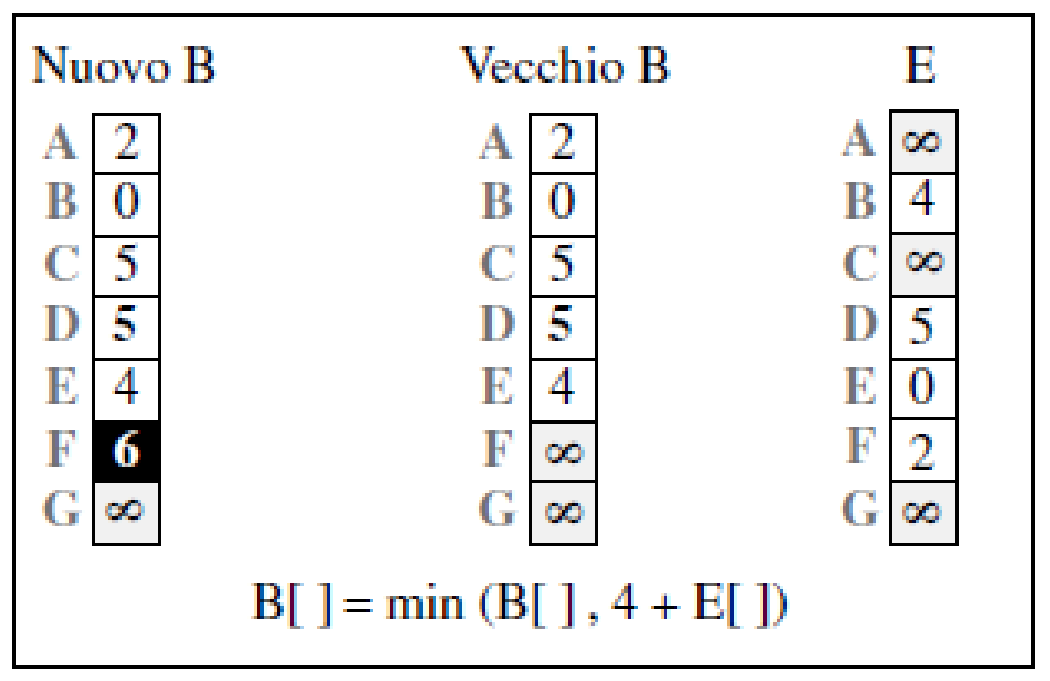
passi dell'algoritmo
Quindi, l’idea di base dell’algoritmo è questa:
- ogni nodo invia una copia del proprio vettore distanza a ciascuno dei suoi vicini
- quando un nodo riceve un nuovo vettore di distanza da un suo vicino, lo salva e usa la formula di Bellman-Ford per aggiornare il proprio vettore distanza
- se il vettore distanza del nodo è cambiato, manderà il proprio vettore distanza aggiornato a ciascuno dei suoi vicini, che a loro volta aggiorneranno i propri
(è asincrono perché) ogni iterazione locale è causata da:
- cambio del costo di uno dei collegamenti locali
- ricezione da un vicino di un vettore di distanza aggiornato
(è distribuito perché):
- ogni nodo aggiorna i suoi vicini solo quando il suo vettore della distanza cambia (i vicini sono avvisati solo se necessario)
problema della modifica dei costi
con le modalità di aggiornamento definite nell’algoritmo, si può verificare il problema del conteggio all’infinito (le buone notizie viaggiano in fretta, e le notizie cattive si propagano lentamente (life lesson)).
esempio
si guasta il collegamento tra e
il router si aggiorna male a causa del guasto di , quindi invia l’aggiornamento a , che incrementa il vettore delle distanze; la richiesta di aggiornamento continuerà a rimbalzare tra e (e di conseguenza il costo aumenterà) finché il costo non sarà
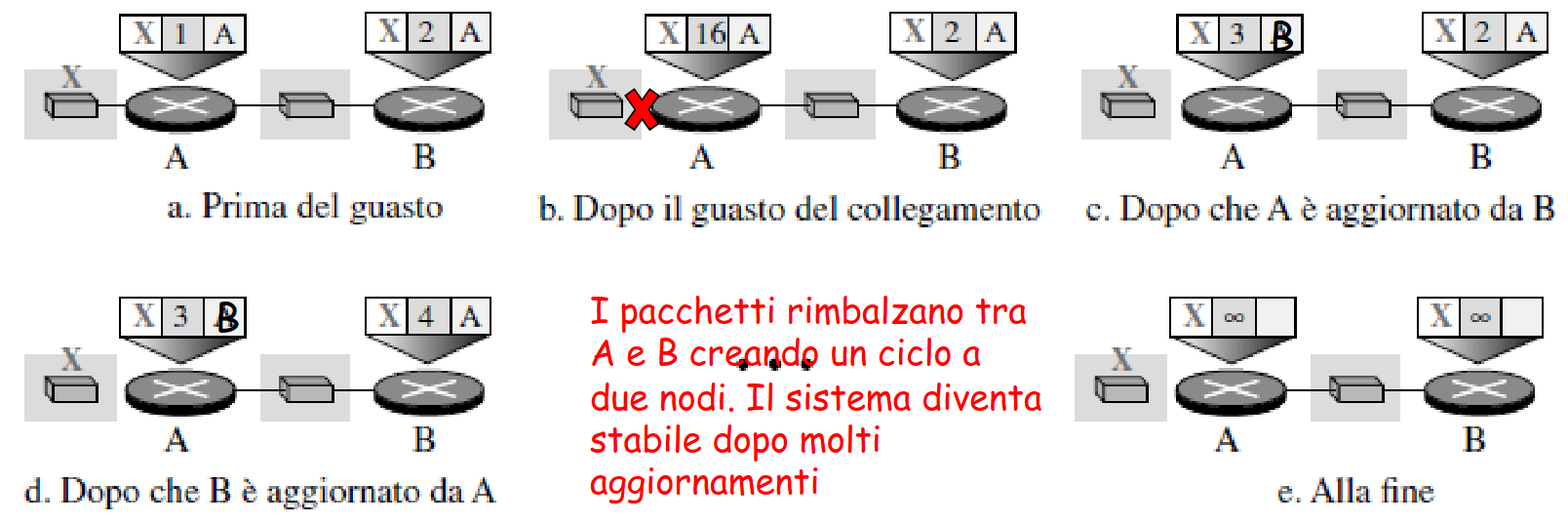
Ci sono due possibili soluzioni a questo problema:
- split horizon ⟶ invece di inviare la tabella attraverso ogni interfaccia, ciascun nodo invia solo una parte della sua tabella tramite le interfacce: se per esempio il nodo ritiene che il percorso ottimale per arrivare a passi attraverso , non fornisce questa informazione ad (in quanto gli è arrivata da , che quindi la conosce già)
- nell’esempio di sopra, elimina la riga di prima di inviarla ad
- poisoned reverse ⟶ si pone a il valore del costo del percorso che passa attraverso il vicino a cui si sta inviando il vettore
- nell’esempio di sopra, pone a il costo verso quando invia il vettore ad
protocollo RIP
Il Routing Information Protocol (RIP) è un protocollo a vettore distanza, ed è incluso in UNIX BSD dal 1982 .
- la metrica di costo è la distanza misurata in hop
- 15 è il massimo di hop, e 16 indica
- ogni link ha un costo unitario
esempio
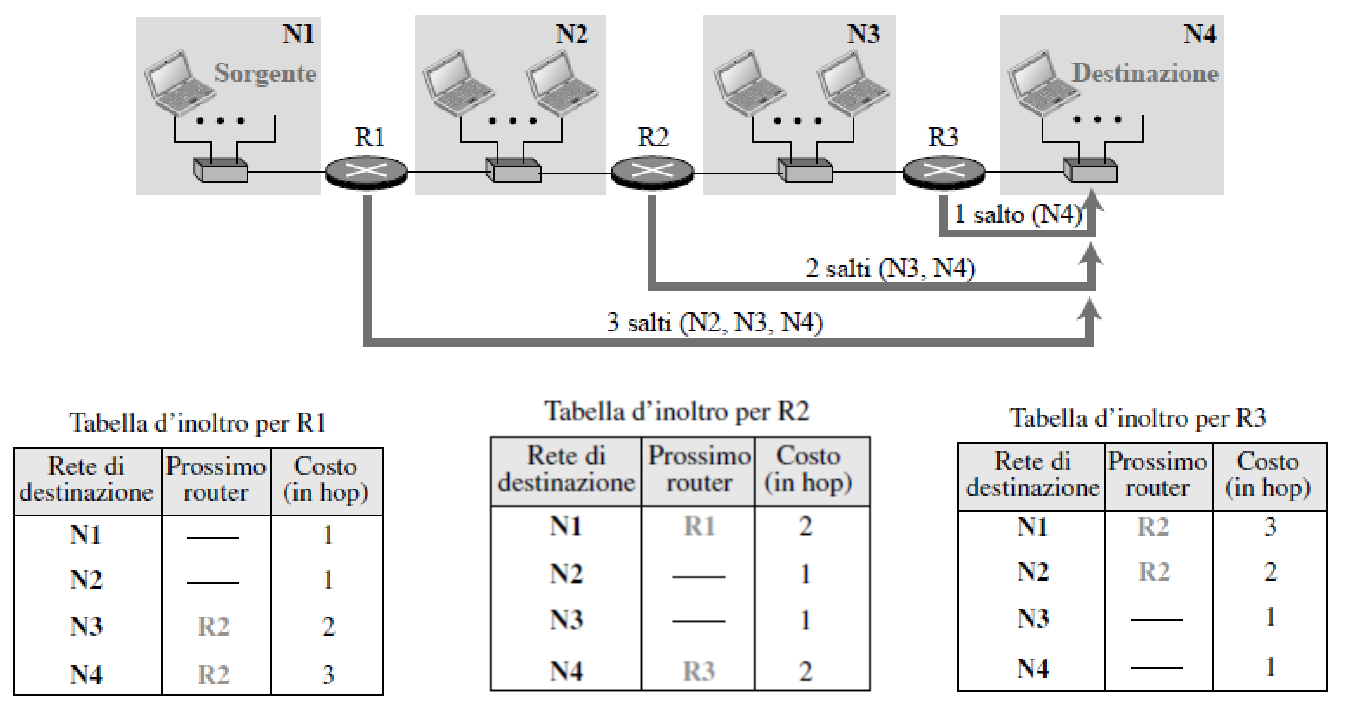
Nel protocollo RIP, ogni router manda periodicamente la sua routing table agli altri router. Ogni router dello stesso network potrà quindi aggiornare le sue tabelle in base alle informazioni ricevute.
- ogni router che riceve un messaggio da un altro router (nello stesso network) che dice di poter raggiungere il network a costo sa che potrà a sua volta raggiungerlo a costo (attraverso il router da cui ha ricevuto il messaggio)
invece di inviare solo i vettori di distanza, i router inviano l'intero contenuto della tabella di routing
IP sorgente e destinazione
Se un router invia due messaggi RIP a due router vicini e , i due datagrammi che incapsulano i messaggi avranno entrambi indirizzo IP sorgente e destinazione diversi: per ogni datagramma, l’indirizzo IP di origine sarà l’indirizzo dell’interfaccia da cui viene inviato (un router può avere solo un vicino immediato per ogni interfaccia), e l’IP di destinazione sarà l’indirizzo IP dell’interfaccia del router a cui arriva.
messaggi RIP
RIP si basa su una coppia di processi client-server e sul loro scambio di messaggi.
- RIP request ⟶ quando un nuovo router viene inserito nella rete, invia una RIP request per ricevere immediatamente informazioni di routing
- RIP response (o advertisements) ⟶ o in risposta a una Request (solicited response), o periodicamente ogni 30 secondi (unsolicited response)
Ogni messaggio contiene un elenco comprendente fino a 25 sottoreti di destinazione all’interno del sistema autonomo e la distanza del mittente rispetto a ciascuna di tali sottoreti.
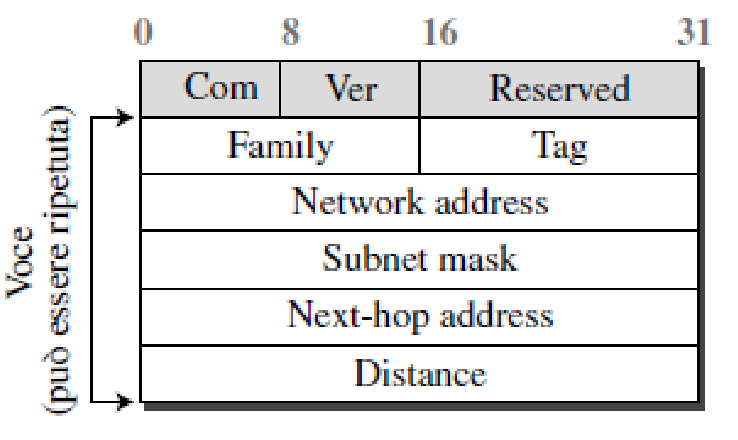
struttura dei messaggi RIP
ogni messaggio corrisponde a una entry nella tabella di routing
com⟶ comando:1= richiesta,2= rispostavers⟶ versione (la versione corrente è 2)family⟶ famiglia del protocollo (per il TCP/IP il valore è2)tag⟶ informazioni sul sistema autonomonetwork address⇒ indirizzo di destinazionesubnet mask⟶ maschera di sottoretenext-hop address⟶ indirizzo del prossimo hopdistance⟶ numero di hop fino alla destinazione
caratteristiche di RIP
- split horizon with poisoned reverse
- evita che un router invii rotte non valide al router da cui ha imparato una rotta (evitando cicli)
- si mette a 16 (infinito) il costo della rotta che passa attraverso il vicino a cui si manda advertisement
- triggered updates
- riducono il problema della convergenza lenta
- quando una rotta cambia, si inviano immediatamente informazioni ai vicini senza attendere il timeout
- hold-down
- fornisce robustezza
- quando si riceve un’informazione di una rotta non più valida, si avvia un timer e tutti gli advertisement riguardanti quella rotta che arrivano entro il timeout vengono tralasciati
timer RIP
Il protocollo RIP utilizza 3 timer:
- timer periodico ⟶ controlla l’invio di messaggi di aggiornamento (ogni 25-35 secondi)
- timer di scadenza ⟶ regola la validità dei percorsi (ogni 180 secondi)
- se entro lo scadere del timer non si riceve un aggiornamento, il percorso viene considerato scaduto e il suo costo impostato a 16
- timer per garbage collection ⟶ elimina percorsi dalla tabella (ogni 120 secondi)
- quando le informazioni non sono più valide, il router continua ad annunciare il percorso con costo pari a 16 e, allo scadere del timer, rimuove il percorso
guasto su collegamento e recupero
(Come visto sopra) se un router non riceve notizie da un suo vicino per 180 secondi, il nodo o il collegamento vengono considerati spenti o guasti. Se accade:
- RIP modifica la tabella di instradamento locale
- propaga l’informazione mandando annunci ai router vicini
- se la loro tabella di instradamento è cambiata, i vicini inviano nuovi messaggi
- quindi, l’informazione sul fallimento del collegamento si propaga rapidamente su tutta la rete
- l’utilizzo della poisoned reverse evita i loop
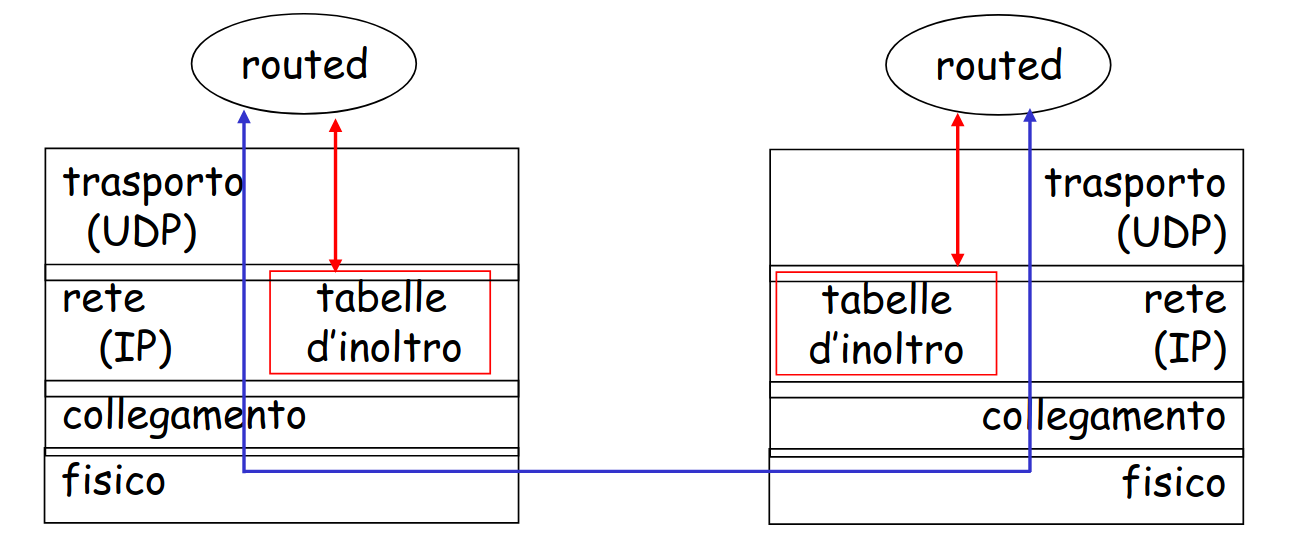
implementazione di RIP
Il RIP viene implementato come applicazione sopra UDP sulla porta 520.
- un processo chiamato
routed(route daemon) esegue RIP, ovvero mantiene le informazioni di instradamento e scambia messaggi con i processiroutednei router vicini - poiché RIP viene implementato come processo a livello applicazione, può inviare e ricevere messaggi su una socket standard e usare un protocollo di trasporto standard