Quando le chiavi ammettono un ordinamento significativo, è conveniente usare un’organizzazione fisica dei dati che ne tenga conto.
es: interi e stringhe
- per campi multipli, si ordina sul primo e, in caso di parità, sul secondo e così via
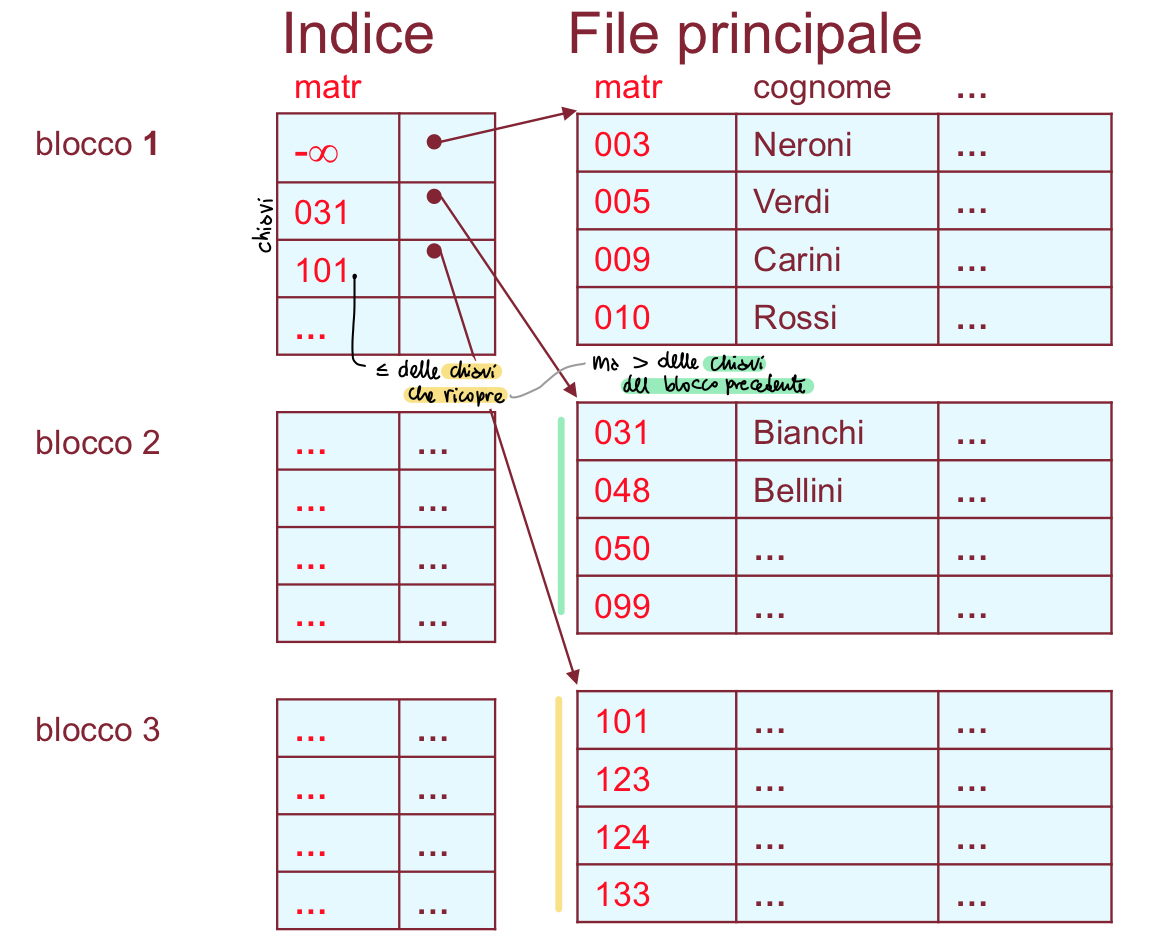
file ISAM
- sta per Indexed Sequential Access Method
Il file principale (che contiene le tuple della tabella) viene ordinato in base al valore della chiave di ricerca.
- in genere viene lasciata una certa percentuale di spazio libero in ogni blocco, per facilitare l’inserimento
C’è anche una table of contents che indica dove trovano i blocchi del file indice (utile per la ricerca).
Il file indice contiene un record per ogni blocco (importante! non per ogni record) del file principale. Ogni record del file indice ha due campi:
- un puntatore ad un blocco del file principale
- una chiave delle chiavi nel blocco a cui punta, e di quelle del blocco puntato dal record precedente (all’inizio: la più piccola delle chiavi del blocco)
proprietà di copertura
Questa struttura per le chiavi si chiama proprietà di copertura - ogni chiave dell’indice ricopre il blocco puntato
ricerca
Se si vuole effettuare una ricerca di una chiave x:
- si parte dal file indice, e si cerca il primo valore
x, e si prende il precedente - così facendo, si seleziona il valore che ricoprex. - (se non c’è un record con chiave maggiore, è l’ultimo)
La ricerca di un record con chiave x richiede una ricerca sul file indice + 1 accesso in lettura sul file principale (una volta trovato il blocco corretto).
ricerca binaria
Visto che il file indice è ordinato in base al valore della chiave, la ricerca di un valore che ricopra una chiave x può essere fatto in modo efficiente tramite la ricerca binaria:
- grazie alla Table Of Contents (che ci permette di sapere dove sono tutti i blocchi del file indice):
- accediamo in lettura al blocco e confrontiamo
xconk1(la prima chiave del blocco)- se
x = k1⇒ abbiamo finito. - se
x < k1⇒ vuol dire che la chiave si trova prima - ripetiamo il procedimento considerando i blocchi da a (andiamo al blocco a metà più uno di quell’intervallo) - se
x > k1⇒ può essere o coperta da questa chiave, o da una di quelle successive - ripetiamo il procedimento da (il blocco corrente, che non viene quindi escluso) a .
- se
- ci fermiamo quando lo spazio di ricerca è ridotto ad un singolo blocco (a quel punto basta trovare la chiave che copra
x). - si faranno quindi accessi
ricerca binaria più intelligente
(visto che il costo di accesso è “iniziale”, e scorrere un intero blocco non costa di più di controllare solo la prima chiave,) una soluzione più efficiente può essere quella di eseguire la normale ricerca binaria, ma:
- invece di controllare solo la prima chiave di ogni blocco, controllarle tutte
- se nessuna delle
kiricopre SICURAMENTExallora si continua con la ricerca binaria dividendo di nuovo ecc.
sicuramente perché? perché, se per esempio l’ultima chiave del blocco è
< x, non so sexsarà coperta da una chiave successiva - devo dividere di nuovo e procedere con la ricerca binariaultima chiave del blocco
Seguendo questo metodo, quindi, se si controlla l’ultima chiave di un blocco e si vede che
x > kn, si ha un‘“incertezza” -xpotrebbe essere coperta da essa o da una chiave successiva. Istintivamente, si potrebbe pensare di controllare la prima chiave del blocco successivo, per vedere se è> x(e quindi non la ricopre, e la chiave corretta è l’ultima del blocco precedente) - ma questo sarebbe un errore. Infatti, accedere al blocco successivo costa (è, appunto, un accesso), e lo si farebbe ogni volta - il costo aumenterebbe quindi di molto (e inutilmente: in ogni caso, proseguendo con la ricerca binaria, si arriverà al blocco corretto).
ricerca per interpolazione
La ricerca per interpolazione è basata sulla conoscenza della distribuzione dei valori della chiave:
- deve essere disponibile una funzione che, dati tre valori
k1,k2, k3della chiave, fornisce la frazione dell’intervallo di valori compresi trak2ek3e in cui deve quindi trovarsik1(che stiamo cercando) (quindi una specie di stima normalizzata della posizione relativa dik1rispetto ak2ek3)- nella ricerca binaria, questa frazione è sempre
Come funziona?
k1deve essere confrontato con il valorekdella chiave del primo record del blocco (del file indice), dove- (come nella ricerca binaria, vado al valore )
- Se
k1 < k, il procedimento deve essere ripetuto sui blocchi - se
k1 > k, il procedimento deve essere ripetuto sui blocchi ,
Si va avanti finché la ricerca si restringe ad un unico blocco
La ricerca per interpolazione richiede circa accessi - è quindi molto veloce.
- ma è anche molto difficile conoscere
- inoltre, la distribuzione dei dati potrebbe cambiare nel tempo (funziona solo per le basi di dati statiche)
inserimento
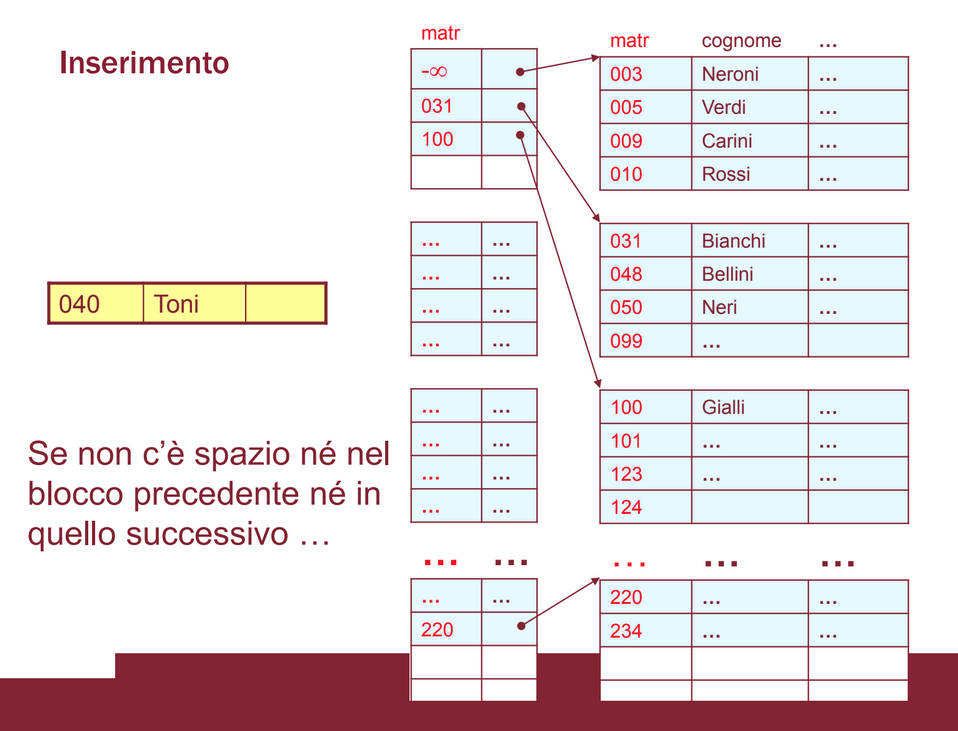
Per inserire un nuovo record, dobbiamo: capire dove, e scriverlo. Il costo sarà quindi costo della ricerca + 1 accesso in scrittura.
spazio non disponibile
Se nel blocco che dovrebbe contenerlo non c’è spazio per un record, si controlla se c’è spazio nel blocco precedente o in quello successivo, e, in caso, si fanno scorrere i record per mantenere l’ordinamento
- a volte bisogna anche cambiare l’indice
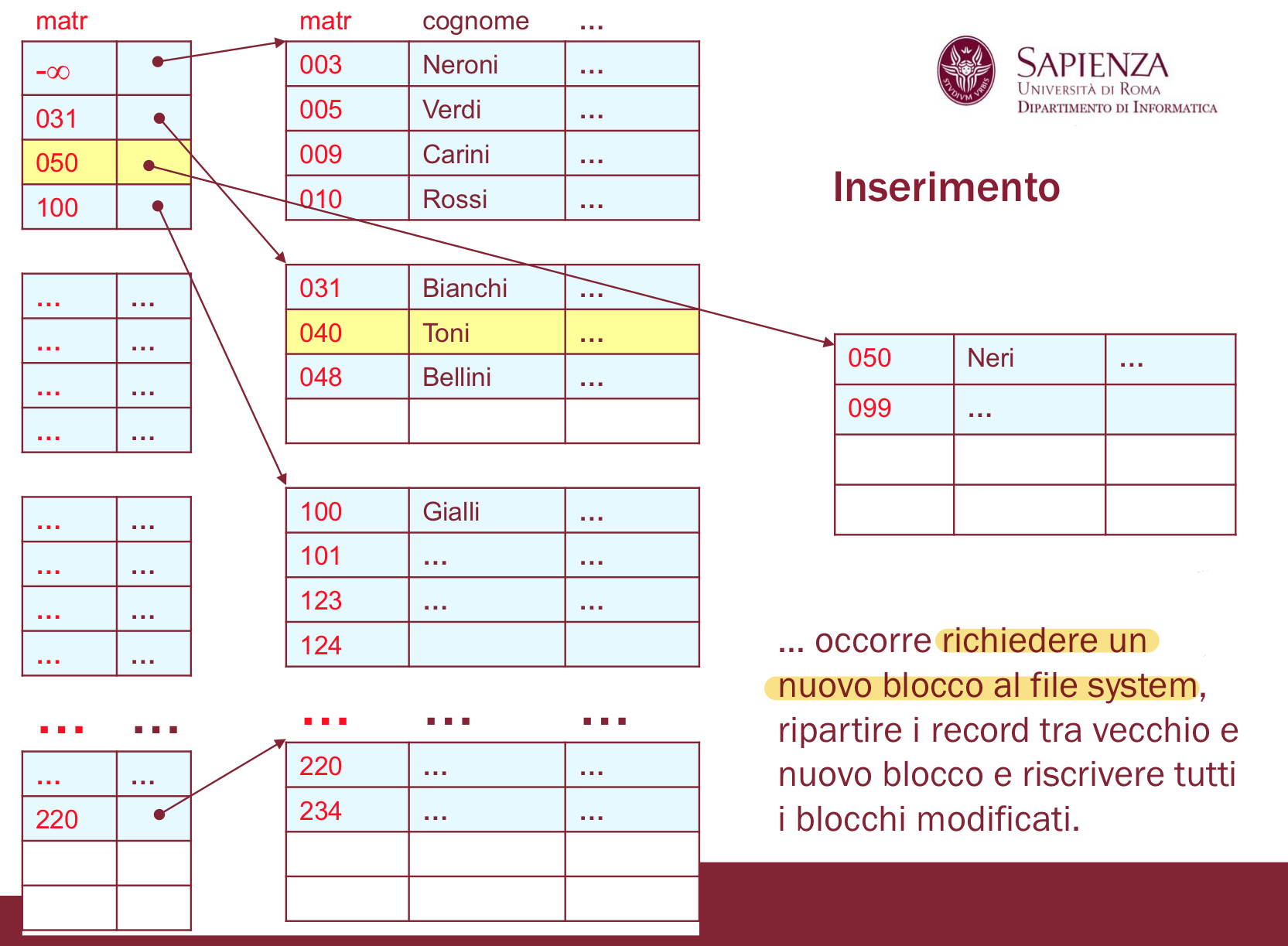
Se non c’è spazio neanche nei blocchi adiacenti, bisogna richiedere un nuovo blocco al file system, e ripartire i record tra vecchio e nuovo blocco.
- non conviene mettere un solo record nel nuovo blocco, ma metterne qualcuno e lasciare dello spazio libero sia nel vecchio che nel nuovo blocco (per facilitare futuri inserimenti)
esempio nuovo blocco
cancellazione
Per cancellare un blocco, dobbiamo trovarlo e cancellarlo. Il costo è quindi costo della ricerca + 1 accesso per scrivere il blocco modificato.
- se il record cancellato è l’unico record del blocco, il blocco viene restituito al sistema e viene modificato l’indice
se cancello il primo record?
Dipende da come è organizzato il file ISAM:
- se come chiave nel file indice tengo sempre la più piccola chiave del blocco corrispondente, devo cambiare l’indice
- (sennò - detto a lezione - posso anche organizzare l’indice con solo chiavi che non sono necessariamente la minima: in quel caso non devo cambiarla)
modifica
Per modificare un blocco dobbiamo trovarlo e poi modificarlo. (Se la modifica non coinvolge la chiave), il costo è quindi costo della ricerca + 1 accesso (per scrivere il blocco modificato)
modifica della chiave
Nel caso in cui dobbiamo modificare la chiave di un record, serviranno una cancellazione e un inserimento (dobbiamo cancellare e reinserire il record - non si può modificare una chiave)
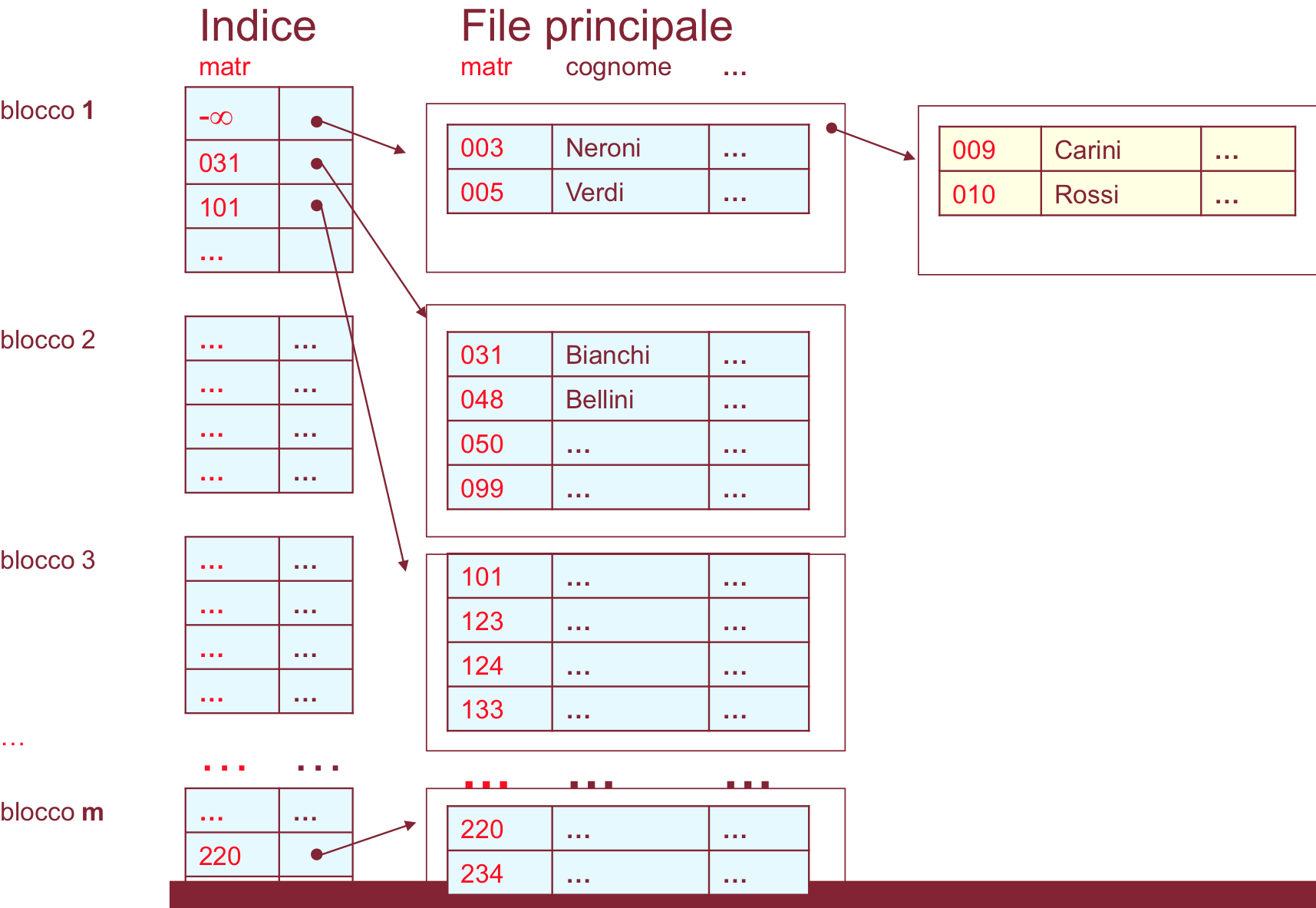
file con record puntati
Consideriamo ora il caso in cui il file principale contiene record puntati.
Nella fase di inizializzazione, è preferibile lasciare più spazio libero nei blocchi per successivi inserimenti.
- poiché i record sono puntati, non possono essere spostati per mantenere l’ordinamento quando se ne inseriscono di nuovi.
Se non c’è spazio sufficiente in un blocco B per l’inserimento, occorre richiedere al sistema un nuovo blocco, che verrà collegato a B tramite un puntatore. Ogni record del file indice punta al primo blocco di un bucket, e il file indice non viene mai modificato (se non per riorganizzare l’intero file).
operazioni
- la ricerca richiede la ricerca sul file indice di una chiave che ricopra il valore che si cerca, e la scansione del bucket corrispondente
- la cancellazione richiede la ricerca del record e la modifica dei bit di cancellazione nell’intestazione del blocco
- la modifica richiede la ricerca del record, la modifica, e la riscrittura del blocco (se non coinvolge la chiave).
- se la modifica coinvolge la chiave, equivale alla cancellazione seguita da un inserimento
- in questo caso, non è sufficiente modificare il bit di cancellazione del record cancellato, ma è necessario inserire in esso un puntatore al nuovo record inserito in modo che sia raggiungibile da qualsiasi record che contenga un puntatore al record cancellato
- per l’inserimento, se un record va inserito in un blocco che è già pieno, bisogna allocare un nuovo blocco che, anzichè essere puntato dall’indice, sarà linkato al blocco originario. (abbiamo cioè una lista di blocchi di overflow che partono da quello originario, dove ognuno punta al successivo).
Visto che non si può mantenere il file principale ordinato, se si vuole seguire l’ordinamento quando si esamina il file, occorre inserire in ogni record un puntatore al record successivo nell’ordinamento.
(Quindi, i record, una volta inseriti, non possono essere spostati per mantenere l’ordinamento - essenzialmente, l’ordinamento vale solo all’inizializzazione).
ripartizione degli intervalli delle chiavi
A differenza dell’ISAM, i record del file indice non vengono mai modificati, quindi rimane valida la ripartizione degli intervalli delle chiavi. (se un blocco si riempie e dobbiamo aggiungere nuovi record, allochiamo un nuovo blocco linkato al blocco originale, ottenendo quindi una lista di blocchi di overflow che partono da quello originario)
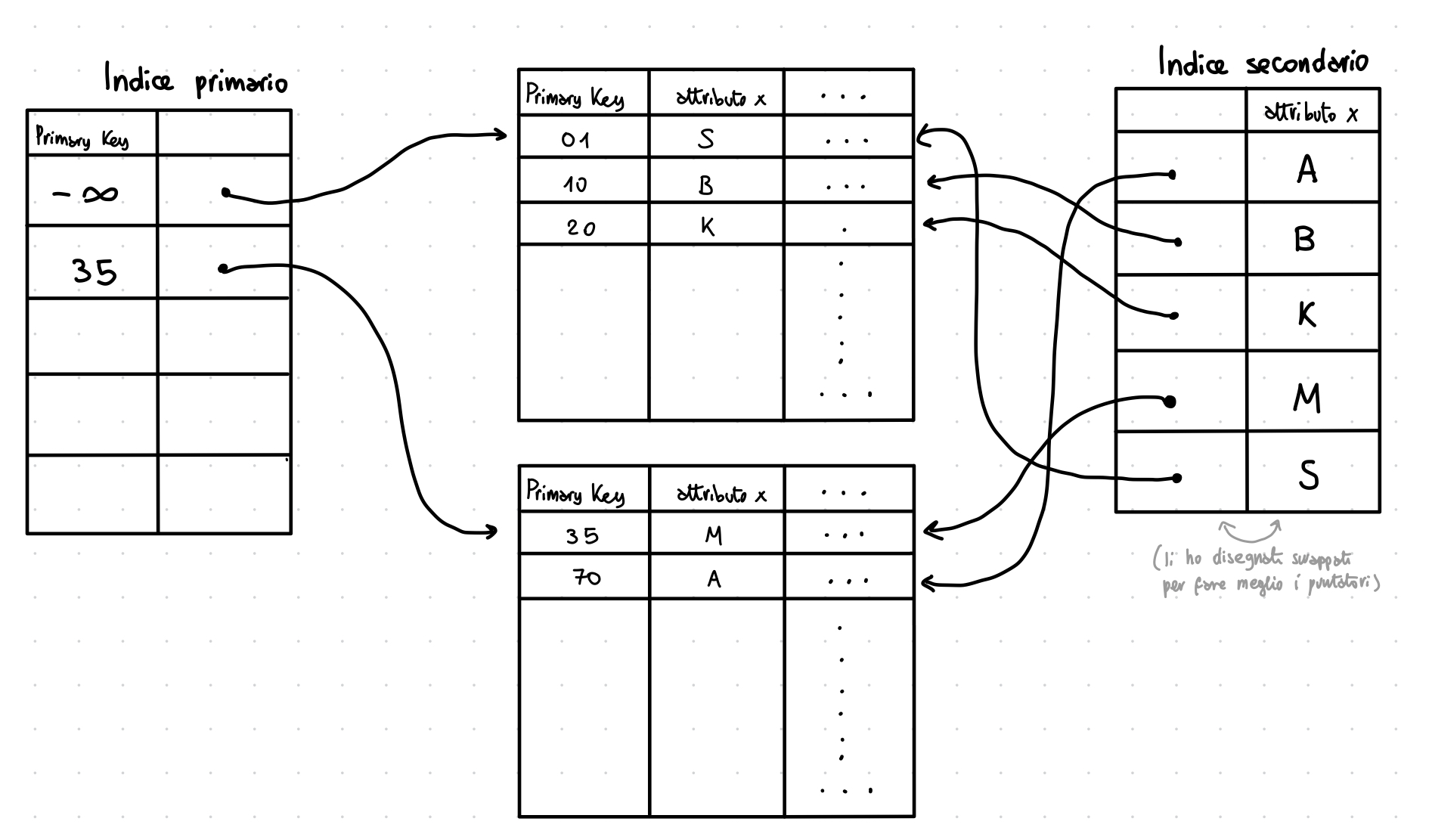
indice sparso e denso
Per alcune operazioni può essere utile definire altri indici oltre alla chiave primaria - ma come si tiene un doppio indice? Invece di un modello a indice sparso (come quello visto sopra, con un record per ogni blocco del file principale), si può usare un indice denso ⇒ un record indice per ogni record del file principale - così, si può mantenere un ordinamento per entrambi (non avrei potuto ordinare blocchi sia per la chiave primaria che per una secondaria).
domande orale
possibili domande orale
- struttura ISAM
- ricerca binaria e interpolazione
- nella ricerca binaria, devo o non devo considerare il blocco corrente quando rifaccio la divisione?
- costo operazioni
- ISAM con record puntati - come funziona? costo operazioni? (non so se l’abbia mai chiesto)
- indice sparso e indice denso