OpenMP is an API for shared-memory parallel programming.
MP stands for MultiProcessing
When using OpenMP, the system is viewed as a collection of cores or CPUs, all of which have access to the main memory.
OpenMP’s aim is to decompose a sequential program into components that can be executed in parallel
with the assistance of the compiler, it allows an “incremental” conversion of sequential programs into parallel ones
it relies on compiler directives for decorating portions of the code, which the compiler will attempt to parallelize
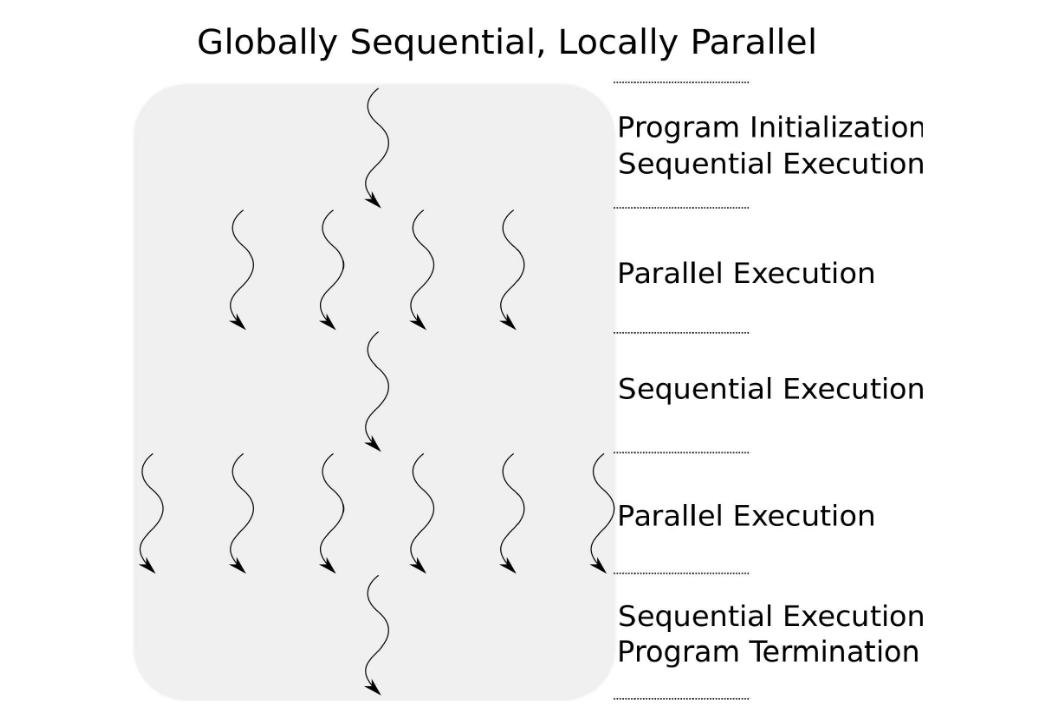
GSLP
OpenMP programs are Globally Sequential, Locally Parallel, and they follow the fork-join paradigm.
terminology
Team ⟶ collection of threads executing the parallel block
Master ⟶ original thread of execution
Parent ⟶ thread that encountered a parallel directive and started a team of threads (often the master)
Children ⟶ threads started by the parent
pragmas
OpenMP uses special preprocessor instructions called pragmas.
They are added to a system to allow behaviors that aren’t part of the basic C specification.
compilers that don't support pragmas ignore them
# pragma omp parallel
# pragma omp parallel is the most basic parallel directive
included in the omp.h library
the number of threads that run the following block of code is determined by the run-time system
syntax
# pragma omp parallel clause
in which clause can be:
if(exp) ⟶ executes in parallel only if exp evaluates to a nonzero value at runtime (only one if clause can be specified !)
num_threads(thread_count) ⟶ number of threads to use for the parallel region; if dynamic adjustment of the number of threads is also enabled, then thread_count specifies the maximum number of threads to be used
The OpenMP standard doesn't guarantee that this will actually start thread_count threads.
There might be system-defined limitations on the number of threads that a program can start.
example
#include <stdio.h>#include <stdlib.h>#include <omp.h>void Hello(void);int main(int argc, char* argv[]) { /* get # of threads from CLI */ int thread_count = strtol(argv[1], NULL, 10); # pragma omp parallel num_threads(thread_count) Hello(); return 0;}void Hello(void){ int my_rank = omp_get_thread_num(); int thread_count = omp_get_num_threads(); printf("Hello from thread %d of %d\n", my_rank, thread_count);}
To compile a program that uses OpenMP, the -fopenmpflag is necessary.
gcc -g -Wall -fopenmp -o omp_hello omp_hello.c
Thread Team Size Control
There are three levels at which the number of threads can be specified:
Universally - via the OMP_NUM_THREADSenvironment variable
sets the default number of threads for all OpenMP programs executed in the current shell section
export OMP_NUM_THREADS=x to set it, echo ${OMP_NUM_THREADS} to query it
Program level - via the omp_set_num_threadsfunction (called outside an OpenMP construct)
Pragma level - via the num_threadsclause (seen above)
sets the number of threads for a single specific parallel construct
The most specific setting “overwrites” the others (so, a pragma level specification will “win” over a universal one).
Two very useful functions are:
omp_get_num_threads ⟶ returns the active threads in a parallel region (if called in a sequential part, 1)
omp_get_thread_num ⟶ returns the id of the calling thread
Compiler support
If the compiler doesn’t support OpenMP, the #ifdef construct can be used:
#ifdef _OPENMP#include <omp.h>#endif
this way, the header only gets included if it’s actually supported
The same #ifdef has to be used before the OpenMP functions are called, though, since they can’t be executed without the library.
#ifdef _OPENMP int my_rank = omp_get_thread_num ( ); int thread_count = omp_get_num_threads ( );#else int my_rank = 0; int thread_count = 1;#endif
Mutual Exclusion
When parallelising with OpenMP, one has to be careful: in cases in which shared variables are involved, results are unpredictable when 2+ threads attempt to simultaneously execute (because the variable copies stored in the registers are not guaranteed to be consistent - changes could be lost/overwritten).
The solution to that is mutual exclusion (critical sections).
only one thread at a time can execute a critical section
# pragma omp critical global_result += my_result;
(the compiler likely replaces it with pthread lock and unlocks)
If supported by the CPU, the atomic clause ensured that a specific memory operation is performed as an indivisible action at the hardware level
named critical sections
OpenMP provides the option of adding a name to a critical directive:
# pragma omp critical(name)
this way, two blocks protected with critical directives with different names can be executed simultaneously.
Since these names are set at compile time, what can we do if we want to have multiple critical sections but we don’t yet know how many at compile time? We can use locks:
locks
lock example
omp_lock_t writelock;omp_init_lock(&writelock);#pragma omp parallel forfor(i = 0; i < x; i++){ // some stuff omp_set_lock(&writelock); // one thread at a time stuff omp_unset_lock(&writelock); // some other stuff}omp_destroy_lock(&writelock);
critical vs atomic vs locks
keep in mind
the atomic directive has the potential to be the fastest method of obtaining mutual exclusion, but some atomic clause implementations might enforce mutual exclusion across all atomic directives in the program (even between ones who do not share the same critical section)
the use of locks should be probablly reserved for situations in which mutual exclusion is needed for a data structure rather than a block of code
you shouldn’t mix the different types of mutual exclusions for a single critical section
there is no guarantee of fairness in mutual exclusion constructs (the waiting queue is unordered)
it can be dangerous to nest mutual exclusion constructs
Variable scope
In OpenMP, the scope of a variable refers to the set of threads that can access the variable in a parallel block.
A variable that can be accessed by all the threads in the team has a shared scope; a variable that can only be accessed by a single thread has a private scope.
The default scope for variables declared before a parallel block is shared (inside a parallel block, it’s obviously private)
int x; // shared#pragma omp parallel{ int y // private}
default clause
The default clause lets the programmer specify the scope of each variable in a block.
none ⟶ no policy will be applied by default; the programmer is required to explicitly declare the data-sharing policy of every variable
shared ⟶ variables not explicitly assigned a policy will be considered as having been passed implicitly to a shared clause
private ⟶ creates a separate copy of a variable for each thread in the team.
private variables are not initialised !!
firstprivate ⟶ behaves like the private clause, but the private variable copies are initialised to the value of the “outside” object
lastprivate ⟶ behaves like the private clause, but the thread finishing the last iteration of the sequential block copies the value of its object to the “outside” object
threadprivate ⟶ creates a thread-specific persistent storage for global data;
copyin is used in conjunction with the threadprivate clause to initialise the threadprivate copies of a team of threads from the master thread’s variables
copyprivate could also be used - in that case, the value of a private variable is changed by a thread entering the parallel region, and, at the end of the section, is broadcasted to the other threads’ private copies of the variable (see example)
example
int total = 0; // shared variable int N = 1000; // shared variable // Using default(none) forces the programmer to explicitly state // the scope of 'total', 'N', and 'i'. #pragma omp parallel for default(none) private(i) shared(total, N) reduction(+:total) for (i = 0; i < N; i++){ total += i; // Error-free because 'total' is in reduction, 'i' and 'N' are handled }}
threadprivate examples and explanation
with copyin
private_data = 999; // set the master thread's initial value// use copyin to initialize all private copies#pragma omp parallel copyin(private_data) num_threads(2){ // all threads print the value copied from the master (999) printf("Thread %d (Start): %d\n", omp_get_thread_num(), private_data); // each thread modifies its OWN private copy private_data += omp_get_thread_num(); // all threads print their modified private value printf("Thread %d (End): %d\n", omp_get_thread_num(), private_data); } // check the master thread's final value (modified by the master thread) printf("Master Thread (After Parallel): %d\n", private_data);}
with copyprivate
// private_var is a private variableint private_var;#pragma omp threadprivate(private_var)// initially, the value in each thread's private_var is uninitializedint main() { #pragma omp parallel num_threads(4) { // this whole block is executed by ONLY ONE thread (the "single" thread). #pragma omp single copyprivate(private_var) { // the chosen thread sets its own private copy. private_var = 4; // the implicit barrier at the end of this 'single' region will perform the broadcast. // copyprivate(private_var) copies the value (4) to all other threads' private_var copies. } // implicit barrier + copyprivate occurs here // now, the threads now have the value 4, regardless of their initial value. printf("Thread %d (After Single): private_var = %d\n", omp_get_thread_num(), private_var); } }
reduction clause
Say that we want to have an output parameter global_result, where each thread accumulates the result of a function.
We could make the function return the computed area and use a critical section like this:
it’s likely that OpenMP will implement a tree reduction
it’s always better to use a reduction clause rather than a critical section (worst case scenario, OpenMP will use a critical section itself, but in most cases it will use a faster implementation)
The private variables created for a reduction clause are initialised to the identity value for the operator.
The reduction at the end of the parallel section accumulates the outside value and the private values computed inside the parallel region.
(wrong) example
int acc = 6;#pragma omp parallel num_threads(5) reduction(* : acc) // * operation{ acc += omp_get_thread_num(); // uses + instead of * printf("thread %d: private acc is %d\n",omp_get_thread_num(),acc);}printf("after: acc is %d\n",acc)
This example doesn’t work: you should never use an operation that is different from the one specified in the reduction clause (since the private variables will be initialised to its identity value, using a different operation will not hold the same result)
parallel for clause
A parallel for forks a team of threads to execute the following structured block.
The structured block following the parallel for directive must be a for loop
The system parallelizes the for loop by dividing the iterations of the loop among threads.
example
h = (b - a)/n;approx = (f(a) + f(b)) / 2.0;# pragma omp parallel for num_threads(thread_count) reduction(+: approx)for (i = 1; i <= n - 1; i++) approx += f(a + i*h);approx = h*approx;
legal forms for parallelizable for statements
plus:
the variable index must have an integer or pointer type
the expressions start, end and incr must have a compatible (with index) type
the expressions start, end and incrmust not change during the execution of the loop
during the execution of the loop, the index variable can only be modified by the “increment expression” in the for statement
non-parallelizable for loops
for (i = 0; i < n; i++){ if(...) break; //cannot be parallelized}for (i = 0; i < n; i++){ if(...) return 1; //cannot be parallelized}for (i = 0; i < n; i++){ if(...) exit(); //can be parallelized but shouldn't}for (i = 0; i < n; i++){ if(...) i++; //cannot be parallelized}
example: odd-even sort
the code might fork/join new threads every time the parallel for is called (depending on the implementation)
if we have nested for loops, it is often enough to simply parallelize the outermost loop
but sometimes, the outermost loop is too short, and not all threads are utilized: we could try to parallelize the inner loop, but there is no guarantee that the thread utilization will be better
The correct solution is to collapse it into one single loop that does all of the iterations.
We can do so manually:
or ask OpenMP to do it for us:
nested parallelism
Nested parallelism is disabled in OpenMP by default, so nested for pragmas will be ignored (and enabling it is not recommended).