Collective communication involves a group of processes within a specified communicator.
every process needs to call the collective function
collective functions are highly optimized in their MPI implementations, so it makes sense to use them over their manual implementations
collective calls are matched solely based on communicator and calling order (there are no tags)
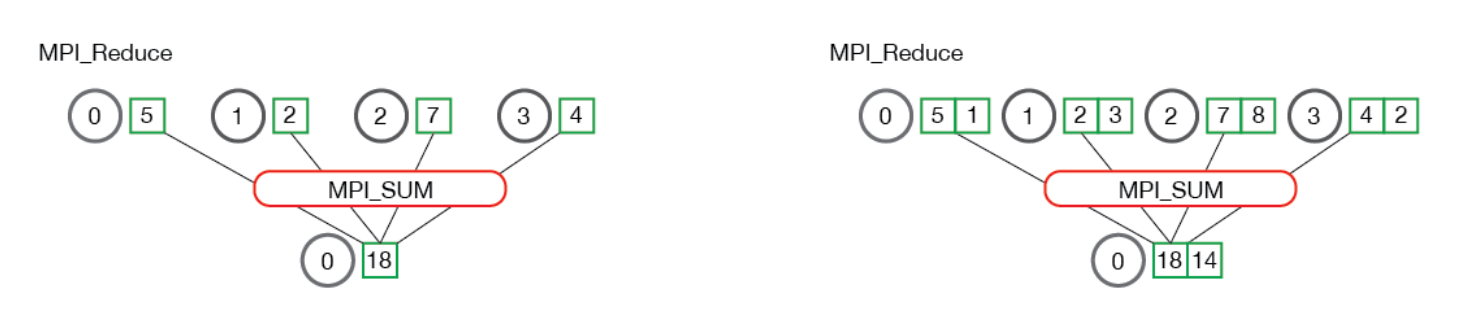
MPI_Reduce()
MPI_Reduce takes an array of input elements from each process, processes them reducing them into a single result, which gets sent to the root process.
example
header
MPI_Reduce( void* send_data, // in void* recv_data, // *out* int count, // in MPI_Datatype datatype, // in MPI_Op operator, // in int root, // in MPI_Comm comm // in);
send_data is an array of elements (or an element) of type datatype that each process wants to reduce
recv_data is only relevant to the process of rank root, and it contains the reduced result
its size is sizeof(datatype) * count
even though it doesn’t concern them, all of the processes still need to pass in an actual argument corresponding to recv_data, even if it’s just NULL
MPI_Op is the reduction operation
custom operators can be created with MPI_Op_create()
collective operations
operation value
meaning
MPI_MAX
maximum
MPI_MIN
minimum
MPI_SUM
sum
MPI_PROD
product
MPI_LAND
logical and
MPI_BAND
bitwise and
MPI_LOR
logical or
MPI_BOR
bitwise or
MPI_LXOR
logical exclusive or
MPI_BXOR
bitwise exclusive or
MPI_MAXLOC
maximum and location of maximum
MPI_MINLOC
minimum and location of minimum
only one call to MPI_Reduce is made - the function will distinguish between the different processes
other caveats
the arguments passed by each process must be “compatible”
for example, if one process passes in 0 as the dest_process and another passes in 1, then the outcome of a call to MPI_Reduce is erroneous and the program is likely to hang or crash
example - average
float *rand_nums = NULL;rand_nums = create_rand_nums(num_elements_per_proc);// sum the numbers locallyfloat local_sum = 0;int i;for (i = 0; i < num_elements_per_proc; i++) { local_sum += rand_nums[i];}// print the random numbers on each processprintf("Local sum for process %d - %f, avg = %f\n", world_rank, local_sum, local_sum / num_elements_per_proc);// reduce all of the local sums into the global sumfloat global_sum;MPI_Reduce(&local_sum, &global_sum, 1, MPI_FLOAT, MPI_SUM, 0, MPI_COMM_WORLD);// print the resultif (world_rank == 0) { printf("Total sum = %f, avg = %f\n", global_sum, global_sum / (world_size * num_elements_per_proc));}
each process creates random numbers and makes a local_sum calculation.
the local_sum is then reduced to the root process using MPI_SUM
the global average is then global_sum / (world_size * num_elements_per_proc)
MPI_Bcast
MPI_Bcast sends data belonging to a single process to all of the processes in the communicator
header
int MPI_Bcast( void* data_p, // in/out int count, // int MPI_Datatype datatype, // in int root, // in MPI_Comm comm, // int);
although the root process and receiver processes do different jobs, they all call the same MPI_Bcast function.
when the root process calls MPI_Bcast, the data_p variable will be sent to all other processes
when all of the receiver processes call MPI_Bcast, the data_p variable will be filled in with the data from the root process.
example
void Get_input( int my_rank, // in int comm_sz, // in double* a_p, // out double* b_p, // out int* n_p, // out ) { if (my_rank == 0) { printf("Enter a, b, and n\n"); scanf("%lf %lf %d", a_p, b_p, n_p); } MPI_Bcast(a_p, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(b_p, 1, MPI_DOUBLE, 0, MPI_COMM_WORLD); MPI_Bcast(b_p, 1, MPI_INT, 0, MPI_COMM_WORLD);}
the process with rank 0 sends the values to the other processes, which will find the values in the same variables used for sending
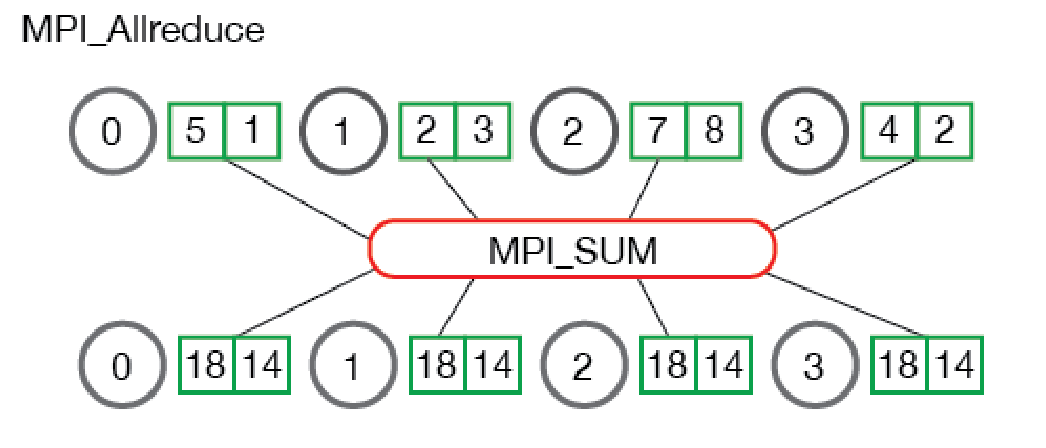
MPI_Allreduce
An MPI_Allreduce is conceptually an MPI_Reduce followed by an MPI_Bcast - the data is processed and the result is distributed to all the processes.
example
header
int MPI_Allreduce( void* input_data_p, // in void* output_data_p, // out int count, // in MPI_Datatype datatype, // in MPI_Op operator, // in MPI_Comm comm // in);
the argument list is identical to that of MPI_Reduce, but there is no root since all the processes will get the results
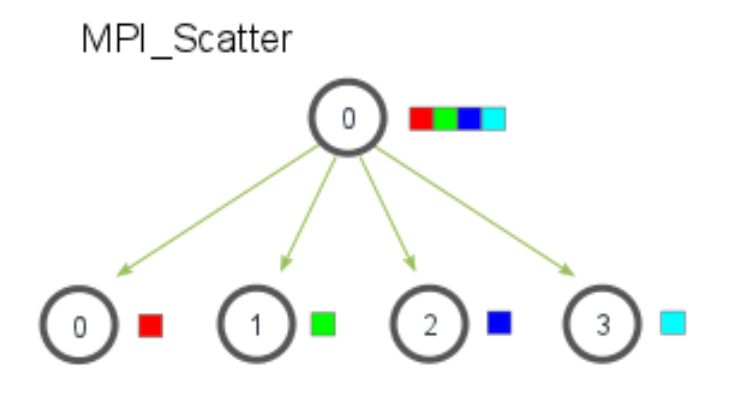
MPI_Scatter
MPI_Scatter involves a designated root process sending data to all processes in a communicator - but, instead of sending the same piece of data to all processes (like MPI_Bcast), it sends different chunks to different processes.
it reads in an entire vector on process 0 and only sends the needed components to each of the other proccesses
header
int MPI_Scatter( void* send_data_p, // in int send_count, // in MPI_Datatype send_type, // in void* recv_buf_p, // out int recv_count, // in MPI_Datatype recv_type, // in int root, // in MPI_Comm comm // in);
send_data_p ⟶ array of data that resides on the root process
send_count and recv_count should match according to datatype (as in, if it’s the same datatype, they should be equal, and if the datatype is different, they should be equivalent (eg. if i send 4 ints and receive chars, i will expect 16 chars))
send_count ⟶ how many elements of send_type will be sent to each process
MPI_Scatterv
MPI_Scatterv can be used if extra capabilities are needed:
gaps are allowed between messages in source data (but the individual message must be contiguous)
irregular message sizes are allowed
data can be distributed to processes in any order
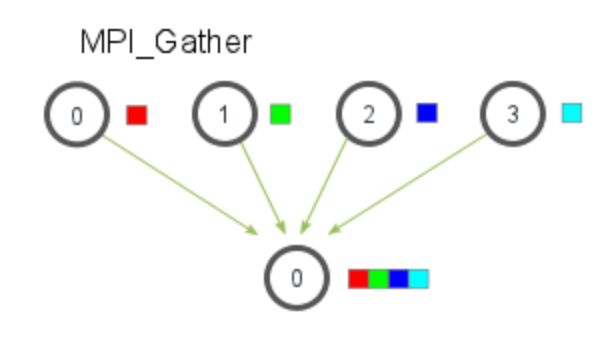
MPI_Gather
(the inverse of MPI_Scatter)
MPI_Gather takes elements from many processes and gathers them to one single process.
elements are gathered in order of the processes’ rank
header
int MPI_Gather ( void* send_data_p, // in int send_count, // in MPI_Datatype send_type, // in void* recv_buf_p, // out int recv_count, // in MPI_Datatype recv_type, // in int dest_proc, // in MPI_Comm comm // in);
only the root process needs to have a valid receive buffer (all the other processes can pass NULL for recv_data_p)
recv_count is the count of elements that each process sends
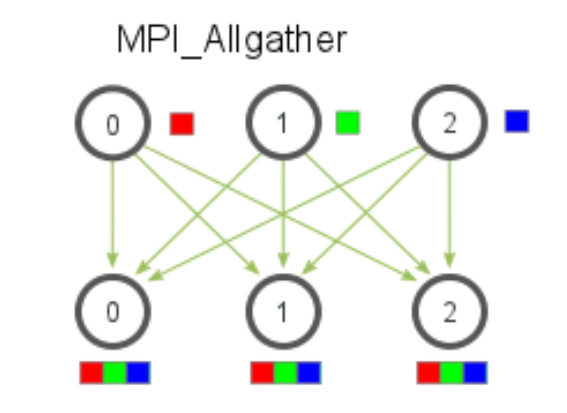
MPI_Allgather
conceptually, a gather + broadcast.
(many-to-many communication pattern)
Given a set of elements distributed across all processes, MPI_Allgather will gather all of the elements to all the processes.
Header
MPI_Allgather( void* send_data_p, // in int send_count, // in MPI_Datatype send_type, // in void* recv_data_p, // out int recv_count, // in MPI_Datatype recv_type, // in MPI_Comm comm // in);
send_count = number of elements sent by each process
recv_count = number of elements to receive from each process (not the total number of elements to receive from all processes altogether)
MPI_Reduce_scatter
Reduces data from all processes and then scatters portions of the reduced result back to the processes.
header
int MPI_Reduce_scatter( const void* sendbuf, // in void* recvbuf, // out const int* recvcounts,// in MPI_Datatype datatype, // in MPI_Op op, // in MPI_Comm comm // in);
sendbuf ⟶ input data for each process
recvbuf ⟶ buffer to store each process’s portion of the reduced data
recvcounts ⟶ int array specifying how many elements each process receives from the reduced result
(each process provides sum(recvcounts) input items and receives recvcounts[rank] reduced results)
Performs a complete data exchange among all processes in a communicator - every process sends a distinct chunk of data to every other process, and receives a distinct chunk from every other process.
header
int MPI_Alltoall( const void* sendbuf, // in int sendcount, // in MPI_Datatype sendtype, // in void* recvbuf, // out int recvcount, // in MPI_Datatype recvtype, // in MPI_Comm comm // in);
sendcount ⟶ number of elements sent to each process
recvcount ⟶ number of elements received from each process
(all processes must send and receive the same amount of data)