chiave ⟶ non esistono due ennuple della stessa tabella che coincidono sul valore di 1+ attributi
ogni tabella ha una chiave primaria - non può essere NULL
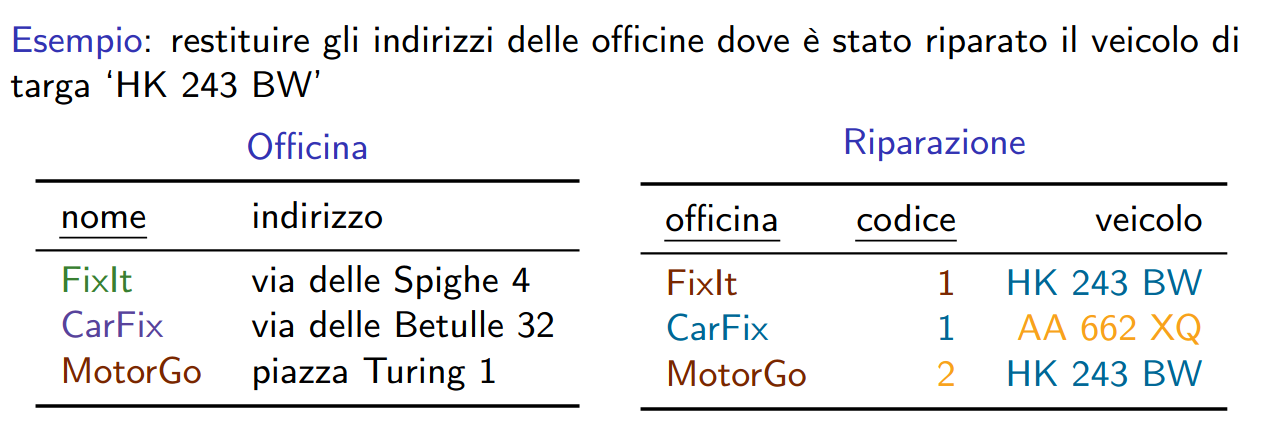
foreign key ⟶ dati in tabelle diverse sono correlati attraverso valori comuni, in particolare, attraverso valori delle chiavi (di solito primarie)
foreign key da un insieme di attributi A di T1 verso tutti gli attributi di una chiave K di T2:
T1(A) references T2(K) significa che tutti i valori di T1(A) devono occorrere come valori della chiave K in una ennupla di T2
foreign key: Modulo(aula) references Aula(codice)
I DBMS seguono un’architettura a 3 livelli:
livello interno ⟶ strutture interne di memorizzazione
livello logico ⟶ modello relazionale dei dati
livello esterno ⟶ viste sui dati (viste diverse per utenti diversi)
creazione database, schemi, tabelle
create database nome_database [opzioni]
crea un database
create schema nome_schema [opzioni]
crea uno schema (namespace) all’interno del database corrente
schema
uno schema di database definisce in che modo i dati vengono organizzati all’interno di un database relazionale; questo include vincoli logici quali nomi di tabelle, campi, tipi di dati e le relazioni tra queste entità.
create table Impiegato ( nome varchar(100) not null, cognome varchar(100) not null, stipendio integer default 0 check (stipendio >= 0))
ogni ennupla deve soddisfare stipendio >= 0
il vincolo viene controllato prima dell’inserimento o modifica di ennuple (in caso di errore, l’inserimento/modifica non ha luogo e viene generato un errore)
vincoli deferrable
Un vincolo di integrità può essere dichiarato deferrable ⟶ è possibile per l’utente decidere se valutarlo solo al termine della transazione corrente.
trigger: vincoli generici
Alcuni vincoli non sono traducibili con le tecniche viste fino ad ora (es. vincoli inter-tabelle). Si possono usare asserzioni (non usate) o trigger.
create [constraint] trigger <nome> { before | after | instead of } {<operaz. intercettata> [ or ... ]} on <tabella> [ from referenced_table_name ] { not deferrable | [deferrable] {initially immediate | initially deferred }} [ for [each] { row | statement } ] [ when ( <condizione> ) ] execute procedure <nome funzione> ( <argomenti> )
l’operazione intercettata può essere insert, update, delete
l’istante dell’invocazione: prima, dopo o invece dell’operazione (instead vale solo per le viste)
deferrable solo se di tipo constraint e after
when: se falsa, la funzione non viene eseguita
for each row ⟶ invocata una volta per ogni ennupla impattata dall’operazione
for statement ⟶ invocata una volta per comando
domini SQL definiti dagli utenti
esistono create type e create domain
Un dominio specializzato definisce un sottoinsieme di valori di un dominio esistente:
create domain nome_dominio as tipo_base [valore di default] [vincolo]
si usano check e value
Example
create domain voto as integer default 0 check (value >= 18 and value <= 30)
Un dominio enumerativo definisce un insieme finito, piccolo e stabile di valori, ognuno identificato da un’etichetta.
create type nome_dominio as enum ("valore 1", ..., "valore N")
I valori di un dominio di tipo record sono record di valori, uno per ogni campo del record. Il valore di ogni campo del record è del rispettivo dominio.
create type nome_dominio as ( campo1 dom1, ..., campoN domN)
Example
create type indirizzo as ( via varchar(200), città varchar(100))
I domini creati dall’utente possono essere modificati o rimossi
alter domain, alter type, drop domain, drop type
vincoli di chiave
primary key ⟶ chiave primaria
unique ⟶ altre chiavi
create table Studente ( matricola integer not null, nome varchar(100) not null, cognome varchar(100) not null, nascita date, cf character(16) not null primary key (matricola), //chiave primaria unique (cf), //altre chiavi unique (cognome, nome, nascita))
count(attributo) ⟶ numero di valori non NULL per l’attributo con duplicati
count(distinct attributo) ⟶ numero di valori non NULL e distinti per l’attributo
funzioni matematiche
sum(attributo) (anche su tempo)
avg(attributo) (anche su tempo)
min(attributo) (su domini ordinati)
max(attributo) (su domini ordinati)
i valori NULL sono ignorati
group by
Le funzioni aggregate possono essere applicate a partizioni delle tuple.
nomi delle persone con figli e stipendio >= 45 con i nomi dei figli
select g.id as gid, g.nome as genitore, f.nome as figliofrom Persona g, GenFiglio gf, Persona fwhere g.id = gf.gen and gf.figlio = f.id and g.stipendio >= 45
nomi delle persone con figli e stipendio >= 45 con il numero di figli
select g.id as gid, g.nome as genitore, count(f.nome) as nFiglifrom Persona g, GenFiglio gf, Persona fwhere g.id = gf.gen and gf.figlio = f.id and g.stipendio >= 45group by g.id, g.nome
mette nello stesso gruppo le ennuple che hanno lo stesso g.id e g.nome
conta quante righe (quanti figli) ci sono in quel gruppo
gli attributi nella target list devono comparire nella clausola group by
having
La condizione having esprime una condizione sui gruppi (e può contenere funzioni aggregate)
si omettono le ennuple dei gruppi che non soddisfano la condizione having
! non si possono usare gli alias nella condizione having
restituire i nomi delle persone con stipendio >= 45 e almeno 2 figli insieme al numero di figli:
select g.id as gid, g.nome as genitore, count(f.nome) as nFiglifrom Persona g, GenFiglio gf, Persona fwhere g.id = gf.gen and gf.figlio = f.id and g.stipendio >= 45group by g.id, g.nomehaving count(f.nome) >= 2
operatori insiemistici
union
queryAunion [all | distinct]queryB
differenza
queryAexcept / minusqueryB
intersezione
queryAintersectqueryB
più efficiente con join
select distinct i.nomefrom Impiegato i, Impiegato jwhere i.nome = j.cognome
query annidate
persone che hanno almeno un figlio
select *from Persona pwhere exists (select * from Paternita where padre = p.nome) or exists (select * from Maternita where madre = p.nome)
le sotto-query non possono contenere operatori insiemistici
non è possibile, in una query, fare riferimento a variabili definite in blocchi più interni
select *from Personawhere reddito = (select max(reddito) from Persona)select *from Personawhere reddito >= all (select reddito from Persona)
select *from Persona pwhere (eta, reddito) not in (select eta, reddito from Persona where nome <> p.nome)
join naturale
select mat.figlio as persona, mat.madre as madre, pat.padre as padrefrom Maternita mat natural join Paternita pat