spanning tree
Dato un grafo , un albero di copertura (o ricoprente/di connessione/di supporto) è un qualsiasi sottografo con , che sia un albero (quindi che sia connesso e aciclico).
- (un albero di copertura di un grafo connesso indiretto è un albero che contiene tutti i nodi del grafo e contiene soltanto un sottoinsieme degli archi: quelli necessari per connettere tra loro tutti i vertici con uno e un solo cammino)
minimum spanning tree
Sia un grafo indiretto connesso pesato. Un albero di copertura minimale è un suo albero di copertura tale che la somma di tutti i pesi degli archi di è minima rispetto a quella di tutti gli altri alberi di copertura.
- un MST non è unico
se si ha un sottografo connesso tale che e tale che la somma dei pesi dei suoi archi sia minima, allora è necessariamente un albero (e quindi un MST)
- (sappiamo che albero = grafo connesso indiretto aciclico)
- supponiamo che ci sia un ciclo in : vorrebbe dire che esiste almeno un arco che può essere eliminato senza che il grafo perda la sua connessione: questo contraddirebbe l’ipotesi per cui la somma dei pesi degli archi di è minima. È perciò impossibile che ci siano cicli, e (poiché e connesso) è quindi un albero.
Il problema è quindi trovare un sottoinsieme di archi che colleghi tutti i vertici e che abbia il minimo peso totale.
algoritmo di Kruskal
L’algoritmo di Kruskal fornisce una soluzione al problema del minimo albero di copertura.
La logica che segue è questa:
- parte con il grafo che contiene tutti i nodi di e nessun arco di
- considera uno alla volta gli archi del grafo in ordine di costo crescente
- se un arco non forma un ciclo in con archi già considerati, lo inserisce in
- al termine restituisce
Anche questo algoritmo rientra nel paradigma della programmazione greedy:
- (decisioni irrevocabili) una volta deciso se inserire o meno un arco in , non ritorna più sulla decisione
- (decisioni prese in base ad un criterio locale) se un arco crea un ciclo, non lo si aggiunge; altrimenti, lo si sceglie in quanto è il meno costoso a non creare cicli
pseudocodice:
kruskal(G):
T = set()
inizializza E con gli archi di G
while E != []:
estrai da E un arco (x,y) di peso minimo
if l'inserimento di (x,y) non crea ciclo con gli archi in T:
inserisci arco (x,y) in T
return T
dimostrazione di correttezza
correttezza
Dobbiamo mostrare che, al termine dell’algoritmo, è un albero di copertura e che non c’è un altro albero che costa meno.
- produce un albero di copertura
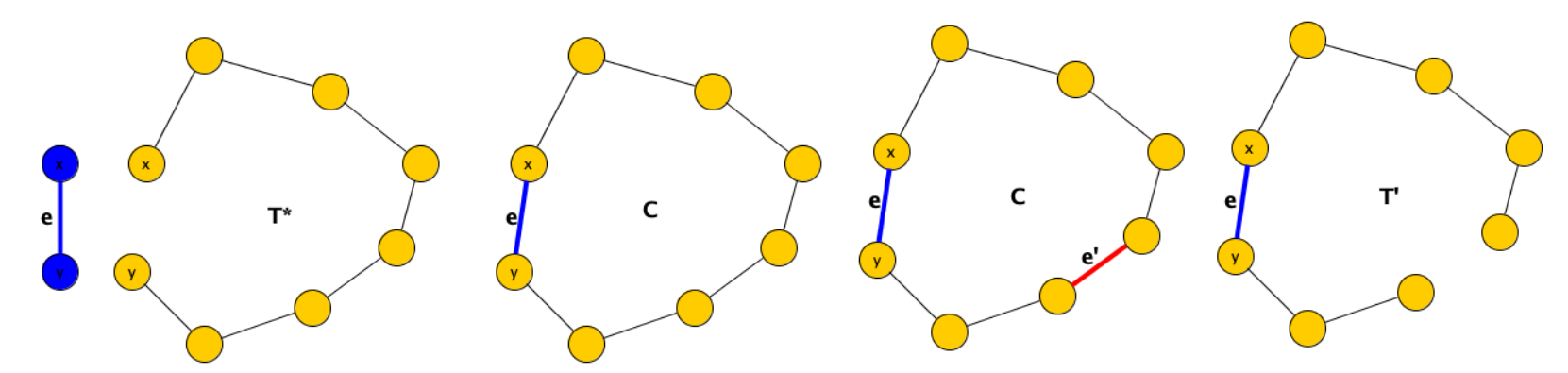
Supponiamo, per assurdo, che al termine dell’algoritmo il sottoinsieme di archi non sia connesso. In tal caso, avrebbe più di una componente connessa. Poiché il grafo iniziale è connesso, esiste almeno un arco che connette due nodi e di due componenti diverse di .
Se non è stato inserito in , significa che è stato scartato perché avrebbe creato un ciclo. Tuttavia, dato che connette due componenti disconnesse, non potrebbe formare un ciclo, poiché non esiste un percorso precedente in che collega a . Questo porta a una contraddizione, in quanto l’algoritmo scarta solo gli archi che causano cicli. Pertanto, il grafo deve essere connesso e aciclico (ovvero un albero).
- non c’è un albero di copertura per che costa meno dell’albero ottenuto
Sia l’albero di copertura prodotto dall’algoritmo di Kruskal, e sia un altro albero di copertura con lo stesso costo minimo. Assumiamo che e differiscano: supponiamo che sia l’albero di copertura con lo stesso costo che differisce nel minor numero di archi da . (il numero di archi dei due rimane lo stesso, ma hanno x archi diversi con x minimo)
Consideriamo l’ordine con cui gli archi sono stati presi in considerazione nel corso dell’algoritmo. Sia il primo arco che compare in e non in . Se fosse inserito in , creerebbe un ciclo (perché è un albero di copertura, quindi l’aggiunta di un altro arco genererebbe necessariamente un ciclo). Il ciclo contiene almeno un arco che non appartiene a (se tutti gli archi di fossero in , allora l’algoritmo non avrebbe aggiunto ).
Consideriamo ora l’albero , ottenuto da inserendo ed eliminando . Il costo del nuovo albero è . Questo non può aumentare rispetto a quello di , perché (perché tra ed , Kruskal ha considerato prima ).
Quindi, è un altro albero di copertura ottimo che differisce da in meno archi di quanto faccia (perché, rispetto a , al posto dell’arco ha l’arco , che appartiene a ), il che contraddice l’ipotesi per cui differisce da nel minor numero di archi.
implementazione
- con un pre-processing, ordino gli archi nella lista così che, scorrendola, ottengo di volta in volta l’arco di costo minimo in tempo
- verifico che l’arco non formi ciclo in controllando se è raggiungibile da in
def kruskal(G):
E = [(c,u,v) for un in range(len(G)) for v,c in G[u] if u < v]
E.sort()
T = [[] for _ in G]
for c,u,v in E:
if not connessi(u,v,T):
T[u].append(v)
T[v].append(u)
return Tdef DFSr(a, b, T, visitati):
visitati[a] = 1
for z in T[a]:
if z == b:
return True
if not visitati[z]:
if DFSr(z, b, T, visitati):
return True
return false
def connessi(u,v,T):
visitati = [0]*len(T)
return DFSr(u, v, T, visitati)- l’ordinamento esterno al
forcosta- ()
- il
forfa iterazioni, e controllare che l’arco non crei un ciclo in costa quanto la visita di un grafo aciclico, ovvero- il
forrichiede quindi
- il
La complessità totale è .
implementazione con union-find in
Union-Find (o Disjoint Set Union) è una struttura dati per gestire insiemi disgiunti che permette operazioni di unione e ricerca efficienti.
In questo caso, gli insiemi disgiunti rappresentano le componenti connesse del grafo.
operazioni fondamentali
Le tre operazioni fondamentali di Union-Find sono:
Crea(C): restituisce una struttura dati Union-Find sull’insieme S di elementi dove ciascun elemento è in un insieme separatoFind(x,C): restituisce il nome dell’insieme nella struttura dati C a cui appartiene l’elemento xUnion(A,B,C): modifica la struttura dati C fondendo la componente A con la componente B e restituisce il nome della nuova componente
L’operazione Find() ci permette di determinare a quale componente connessa appartenga un nodo , e può essere sfruttata per determinare se due nodi e appartengono alla stessa componente.
- se viene aggiunto l’arco al grafo si verifica quindi innanzitutto se e sono nella stessa componente connessa e, se non lo sono, si utilizza l’operazione
Union()per unire le due componenti.
Un modo efficiente di implementare questa struttura dati è mediante vettore dei padri. In questo modo, l’operazione Find() ha costo , in quanto basta risalire alla radice del nodo, e l’operazione Union() costa , in quanto basta rendere una delle due componenti figlia dell’altra.
Ma il costo della Find() si può ridurre ancora per arrivare a un costo di se, ogni volta che si effettua una Union(), si sceglie come nuova radice l’albero che contiene il maggior numero di elementi.
dimostrazione
Dimostriamo che, facendo unioni in base all’altezza (union by rank), si mantiene la proprietà per cui, se una componente ha altezza , essa conterrà almeno nodi, dalla quale possiamo dedurre che l’altezza delle componenti (e quindi il costo della
Find()) non supererà mai .
- (, quindi, se , si avrebbero più di elementi in una componente, il che è impossibile)
Assumiamo per assurdo che durante una delle fusioni si sia formata una nuova componente di altezza per cui la proprietà non è valida. Siano e le due componenti la cui fusione ha generato la nuova componente.
Possono essere accadute due cose:
- e erano componenti con la stessa altezza
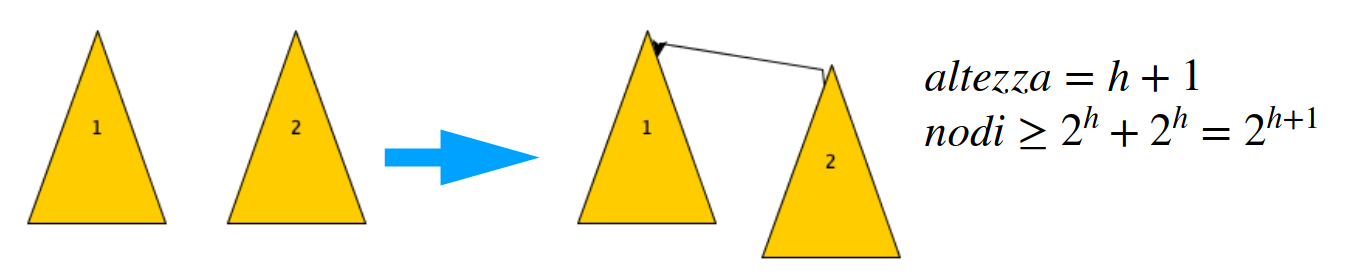
e avevano entrambe altezza e ognuna aveva almeno elementi (perché nelle fusioni precedenti la proprietà era valida). Il numero totale di elementi della nuova componente è ⇒ la proprietà è verificata.
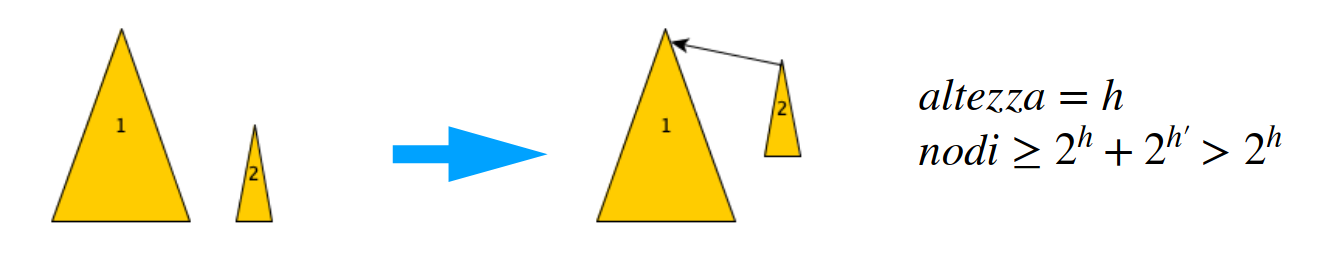
- altezza di > altezza
In questo caso, l’altezza dopo la fusione sarà necessariamente quella di . (Infatti, l’altezza di aumenterà di 1 (la nuova radice), e la situazione sarà ). conteneva già da sola elementi, quindi la proprietà è verificata.
L’implementazione delle operazioni deve quindi tenere conto del numero di elementi in ogni componente. Ogni elemento sarà caratterizzato da una coppia dove è il nome dell’elemento e è il numero di nodi dell’albero radicato in .
def Crea(G):
C = [(i,1) for i in range(len(G))] # si inizializza con una componente per nodo
return Cdef Find(u, C):
while u != C[u]:
u = C[u]
return udef Union(a, b, C):
tota, totb = C[a][1], C[b][1]
if tota >= totb:
C[a] = (a, tota + totb) # a nuova radice
C[b] = (a, totb)
else:
C[a] = (b, tota)
C[b] = (b, tota + totb) # b nuova radicel’implementazione di Kruskal sarà quindi:
def kruskal(G):
E = [(c, u ,v) for u in G for v,c in G[u] if u < v]
E.sort()
T = [[] for _ in G]
C = crea(T)
for c, u ,v in E:
cu = find(u, C)
cv = find(v, C)
if cu != cv:
T[x].append(y)
T[y].append(x)
return T- l’ordinamento costa
- il
forviene iterato volte- l’estrazione dell’arco da costa
- il
Find()costa - la
Union()costa e viene eseguita volte all’interno del for forcosta quindi
Il costo totale è .