// c’è tutto ma vorrei spiegare un po’ meglio alcuni passaggi
divide-et-impera
Il divide et impera è un approccio di risoluzione di problemi che si basa sulla divisione di un problema in sotto-problemi indipendenti, che vengono risolti ricorsivamente. In generale, è formato da 2+1 step:
divide: il problema viene suddiviso in più sotto-problemi simili a quello originale, che vengono a loro volta suddivisi ricorsivamente finché possibile
impera: si risolvono ricorsivamente i sotto-problemi
(combina: i risultati vengono combinati fino a formare una soluzione del problema di partenza)
problema della selezione
Data una lista A di n interi distinti e un intero k, con 1≤k≤n, vogliamo sapere quale elemento occuperebbe la posizione k se il vettore venisse ordinato.
casi particolari
k=1 sarà il minimo di A
k=n sarà il massimo di A
k=⌈2n⌉ sarà il mediano di A
algoritmo naïf
Un possibile algoritmo in Θ(nlogn) è questo:
def selezione1(A, k): A.sort() return A[k-1]
Utilizzando la tecnica del divide et impera, il problema può però risolversi in Θ(n).
si dimostra quindi che il problema della selezione è computazionalmente più semplice di quello dell’ordinamento
algoritmo divide et impera
si sceglie nella lista A l’elemento in posizione A[0] (perno)
a partire da A, si costruiscono due liste A1 e A2, la prima contenente gli elementi minori del perno e la seconda contenente gli elementi maggiori del perno
per trovare l’elemento di rango k:
se ∣A1∣≥k, l’elemento è nel vettore A1
se ∣A1∣=k−1, l’elemento è il perno
se ∣A1∣<k−1, l’elemento è l’elemento di A2 con rango k−∣A1∣−1
def selezione(A, k): if len(A) == 1: return A[0] pivot = A[0] A1, A2 = [], [] for i in range(1,len(A)): if A[i] < pivot: A1.append(A[i]) else: A2.append(A[i]) if len(A1) >= k: return selezione(A1,k) elif len(A1) == k-1: return pivot return selezione(A2, k-len(A1)-1)
La procedura che tripartisce la lista in A1,A[0] e A2 può restituire una partizione massimamente sbilanciata in cui ad esempio ∣A1∣=0 e ∣A2∣=n−1 se il perno è l’elemento minimo nella lista.
Qualora succedesse sistematicamente per tutte le partizioni eseguite dall’algoritmo, allora la complessità dell’algoritmo sarebbe:
T(n)=T(n−1)+Θ(n)=Θ(n2)
In generale, la complessità superiore della procedura è catturata dalla ricorrenza
T(n)=T(m)+Θ(n)
dove m=max(∣A1∣,∣A2∣).
bilanciamento
Se avessimo una regola di scelta del perno in grado di garantire una partizione bilanciata, ovvero m=2n, allora la complessità sarebbe T(n)=T(2n)+Θ(n)=Θ(n).
Ma potremmo anche accontentarci di avere partizioni non perfettamente bilanciate, ma semplicemente non troppo sbilanciate, come quelle per cui m=43n. In questo caso si avrebbe T(n)≤T(43n)+Θ(n)=Θ(n).
In generale, finché m è una frazione di n, la ricorrenza dà sempre T(n)=Θ(n).
scelta equiprobabile di p
Se scegliamo p a caso in modo equiprobabile tra gli elementi della lista, non si creerà necessariamente una partizione bilanciata ma la complessità rimane lineare in n.
def selezioneR(A,k): if len(A)==1: return A[0] pivot = A[randint(0, len(A)-1)] A1, A2 = [], [] for x in A: if x<pivot: A1.append(x) elif x>pivot: A2.append(x) if len(A1) >= k: return selezioneR(A1,k) elif len(A1) == k-1: return pivot return selezioneR(A2, k-len(A1)-1)
Analisi formale del caso medio
Con la randomizzazione introdotta per la scelta del pivot possiamo assumere che uno qualunque degli elementi del vettore, con uguale probabilità n1, diventi pivot e, poiché la scelta dell’elemento di rango k produce ∣A1∣=k−1 e ∣A2∣=n−k, per il tempo atteso dell’algoritmo va studiata la ricorrenza:
dove l’ultima diseguaglianza segue prendendo c in modo che (4cn−2c−a⋅n)≤0; basta ad esempio prendere c≥8a.
Abbiamo quindi dimostrato che il tempo dell’algoritmo selezioneR è O(n) con alta probabilità.
ovviamente, nel caso peggiore (quando si verifica che il perno scelto a caso risulta sempre vicino al massimo o al minimo della lista), la complessità dell’algoritmo rimane O(n2); questo accade però con probabilità molto piccola
algoritmo deterministico in O(n)
Riuscire a selezionare un perno che garantisca che nessuna delle due sottoliste A1 e A2 abbia più di c⋅n elementi per una qualche costante 0<c<1 porta ad una complessità di O(n).
Esiste un metodo chiamato mediano dei mediani che permette di selezionare un perno che garantisce sempre due sottoliste A1 e A2 con ciascuna non più di 43n elementi.
algoritmo
si divide l’insieme A contenente n elementi in gruppi da 5 elementi ciascuno (l’ultimo gruppo potrebbe avere meno di 5 elementi).
si considerano solo i primi ⌊5n⌋ gruppi, ciascuno composto esattamente da 5 elementi.
si trova il mediano di ciascuno di questi ⌊5n⌋ gruppi
si calcola il mediano p dei mediani ottenuti al passo precedente, e si usa come pivot per A
esempio:
proprietà
Se la lista A contiene almeno 120 elementi e il perno p viene scelto in base alla regola, si può dire per certo che la dimensione delle due sottoliste sarà limitata da 43n.
dimostrazione p ha la proprietà di trovarsi in posizone ⌈10n⌉ nella lista degli ⌊5n⌋ mediani selezionati. Ci sono dunque ⌈10n⌉−1 mediani di valore inferiore a p e ⌊5n⌋−⌈10n⌉.
prova per A2
Consideriamo i ⌈10n⌉−1 mediani di valore inferiore a p. Ognuno di questi appartiene ad un gruppo di 5 elementi in n. Ci sono dunque in A altri 2 elementi inferiori a p per ogni mediano. In totale abbiamo quindi
3(⌈10n⌉−1)≥310n−3
elementi di A in A1.
Quindi,
∣A2∣≤n−(310n−3)=107n+3≤43n
(dove 107n+3≤43n perché n≥120).
prova per A1
Ci sono invece
⌊5n⌋−⌈10n⌉≥(5n−1)−(10n+1)=10n−2
mediani di valore superiore a p. Ognuno di questi appartiene ad un gruppo di 5 elementi in A. Ci sono quindi in A altri due elementi superiori a p per ogni mediano.
In totale abbiamo quindi almeno 310n−6 elementi di A che finiranno in A2.
Abbiamo quindi
∣A2∣≤n−(310n−6)=107n+6≤43n
(dove 107n+6≤43n perché n≥120)
implementazione:
from math import ceildef selezione(A,k): if len(A)<=120: # costo costante 120 log 120 A.sort() return A[k-1] # inizializza B con i mediani dei len(A)//5 gruppi di 5 elementi di A # (sorta i gruppi di 5 e prende il terzo elemento) B = [sorted(A[5*1 : 5*i+5])[2] for i in range(len(A)//5)] # # individua il pivot p con la regola del mediano dei mediani pivot = selezione(B, ceil(len(A)/10)) A1, A2 = [], [] for x in A: if x<pivot: A1.append(x) elif x>pivot: A2.append(x) if len(A1) >= k: return selezione(A1,k) elif len(A1) == k-1: return pivot return selezione(A2, k-len(A1)-1)
sappiamo che:
ordinare 120 elementi richiede O(1)
ordinare una lista di n elementi in gruppi da 5 richiede Θ(n)
selezionare i mediani dei mediani di gruppi da 5 da una lista in cui gli elementi sono stati ordinati in gruppi da 5 richiede Θ(n)
Sappiamo che per n≥120, si ha ∣A1∣≤43n e ∣A2∣≤43nl quindi per la complessità T(n) dell’algoritmo si ha:
T(n)≤{O(1)T(5n)+T(43n)+Θ(n)se n≤120altrimenti
equazione di ricorrenza
La ricorrenza è del tipo
T(n)=T(α⋅n)+T(β⋅n)+Θ(n)
con α+β=51+43=2019<1, e questo tipo di ricorrenze hanno tutte come soluzione T(n)=Θ(n).
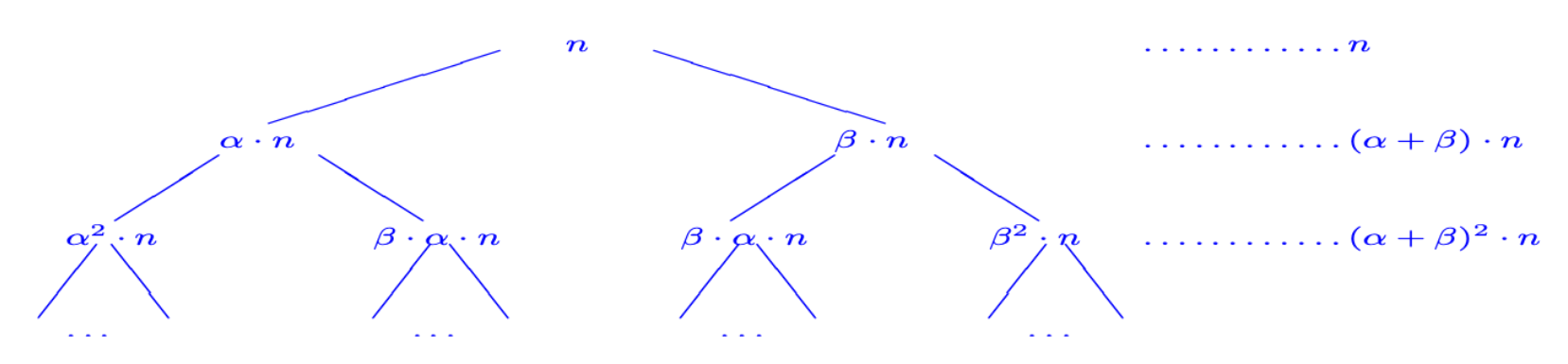
dimostriamolo (metodo dell'albero)
Il fatto che α+β<1 gioca un ruolo fondamentale nella prova.
Consideriamo l’albero delle chiamate ricorsive e analizziamone il costo per livelli:
al primo livello abbiamo un costo (α+β)⋅n, al secondo un costo (α+β)2⋅n, al terzo un costo (α+β)3⋅n e così via
Il tempo di esecuzione totale è la somma dei costi dei vari livelli:
(dove nel calcolare la serie si sfrutta il fatto che α+β<1 e la serie geometrica ∑i=0∞xi con x<1 converge a 1−x1)
Abbiamo quindi dimostrato che il problema della selezione può essere risolto in
tempo lineare., con un algoritmo che risolve il problema in O(n) al caso pessimo.
Tuttavia, a causa delle grandi costanti moltiplicative nascoste dall’O(n), nella pratica l’algoritmo randomizzato che ha tempo O(n) con alta probabilità si comporta molto meglio.