In sistemi con una singola CPU, i programmi sono eseguiti concorrentemente in modo interleaved (interfogliato), per permettere un uso efficiente della CPU. La CPU può quindi:
- eseguire alcune istruzioni di un programma
- sospendere quel programma
- eseguire istruzioni di altri programmi
- ritornare ad eseguire il primo
(su una base di dati, se vengono effettuate solo letture, l’accesso concorrente non crea problemi, mentre, se vengono effettuate anche scritture, l’accesso deve essere controllato)
transazioni
Noi analizziamo le transazioni: esecuzioni di una parte di un programma che rappresenta un’unità logica di accesso o di modifica del contenuto sulla base di dati.
proprietà delle transazioni
ACID
- Atomicità ⇒ la transizione è indivisibile nella sua esecuzione - deve essere totale o nulla, non può essere parziale (in più, se la transazione viene abortita, bisogna disfare le modifiche che ha fatto)
- Consistenza ⇒ quando la transazione finisce, il database deve essere in uno stato consistente, ovvero non deve violare eventuali vincoli di integrità (non ci devono essere inconsistenze tra i dati archiviati)
- Isolamento ⇒ ogni transazione viene eseguita in modo isolato e indipendente dalle altre transazioni (e un suo eventuale fallimetno non deve interferire con le altre transizioni)
- il risultato non deve dipendere dall’esecuzione di altre transazioni: se ho T1, T2, T3, non posso essere obbligato a eseguirle in un ordine particolare - se ho uno scheduler seriale, quindi, qualunque permutazione di transazione mi dà un risultato corretto.
- Durabilità ⇒ (una volta che una transizione ha richiesto un commit work) i cambiamenti non devono essere più persi
- (per evitare che si verifichino perdite di dati, vengono tenuti dei registri di log dove sono annotate tutte le operazioni sul DB)
schedule
def
Uno schedule di un insieme di transazioni è un ordinamento delle operazioni nelle transazioni che conserva l’ordine che le operazioni hanno all’interno delle singole transazioni. (le operazioni possono essere separate da altre operazioni, ma mai invertite)
schedule seriale
schedule seriale
Uno schedule seriale corrisponde ad una esecuzione sequenziale (non interfogliata) delle transazioni (ogni transazione entra ed esce solo una volta finita). (è quindi una permutazione delle transazioni in )
- tutti gli schedule seriali sono corretti
problemi
Visto che quando un item viene letto, esso viene portato nella memoria centrale in uno spazio privato della singola transazione, possono nascere una serie di problemi.
- se un’altra transazione leggerà lo stesso dato, lo porterà nella sua propria zona di memoria - avremmo quindi due copie dello stesso dato che verranno modificate, e potremmo avere dati sbagliati (una sovrascriverà l’altra)
I possibili problemi sono:
- lost/ghost update
- dato sporco
- aggregato non corretto
ghost/lost update
Avviene quando si perde un aggiornamento di un dato.
esempio
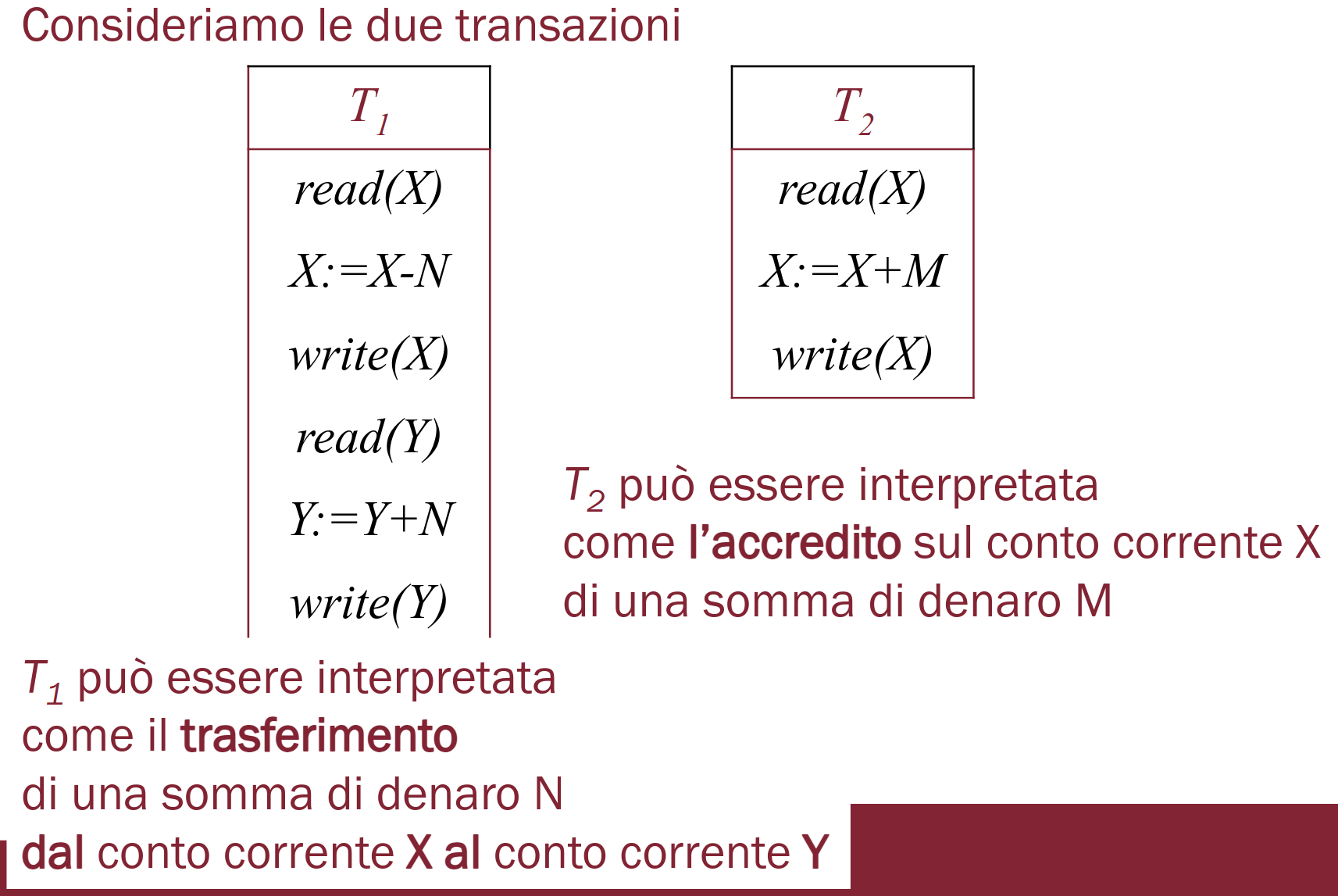
Abbiamo due transazioni,
Consideriamo il seguente schedule:
Se il valore iniziale di è , quello finale dovrebbe essere (sia se mandiamo prima che se mandiamo prima ). Invece, con questo schedule, otteniamo .
- l’aggiornamento di prodotto da viene quindi perso

(risolto dal lock binario)
dato sporco (rollback a cascata)
Avviene quando un valore è il risultato di una transazione fallita (che va quindi “annullata”)
esempio
A causa dell’atomicità delle transazioni, se fallisce, il valore di deve essere riportato a quello iniziale (quindi il
writedi dovrebbe dare risultato - ma, visto che ha usato il dato sporco prima del fallimento di , il risultato sarà )

(risolto dal locking a due fasi stretto)
aggregato non corretto
Avviene quando l’ordine delle operazioni fa sì che alcuni dati vengano processati dopo le operazioni che li richiedono.
esempio
La somma viene eseguita dopo , quindi in mancherà .

risolto dal locking a due fasi
serializzabilità
- tutti gli schedule seriali sono corretti
Uno schedule non seriale è corretto se è serializzabile, ovvero se è equivalente ad uno seriale.
equivalenza
Due schedule sono equivalenti se:
- (per ogni dato modificato) producono valori uguali
- e due valori sono uguali solo se sono prodotti dalla stessa sequenza di operazioni
perché non basta che siano uguali?
questi due schedule producono lo stesso valore solo se il valore iniziale di è 10 - esiste quindi un caso in cui producono lo stesso valore, ma non sono equivalenti

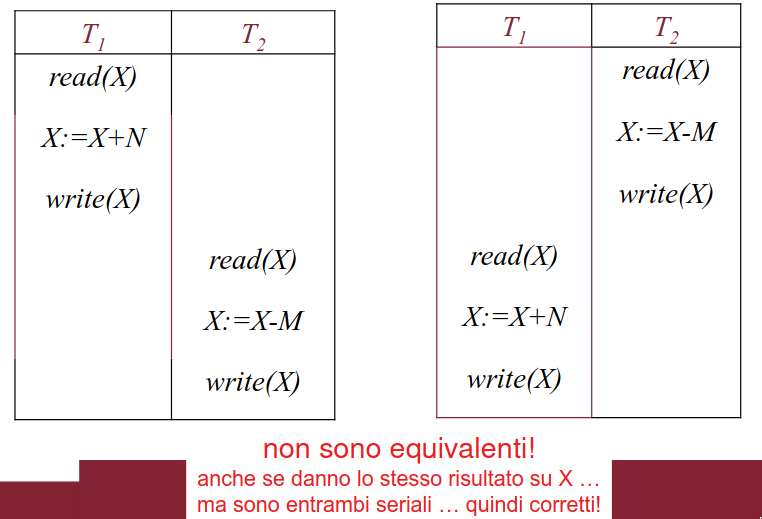
schedule seriali ed equivalenza
Gli schedule seriali possono non essere equivalenti tra loro, ma sono comunque tutti corretti.
esempio
testare la serializzabilità
- non possiamo testare tutta una transazione, tutte le sue versioni seriali, e poi, in caso non fosse serializzabile, “buttare tutto” - è impratico
- in più, è praticamente impossibile determinare in anticipo in che ordine le operazioni verranno eseguite (ci sono troppi fattori che lo determinano)
Ci sono quindi dei metodi che garantiscono la serializzabilità di uno schedule. Si può:
- imporre dei protocolli (es. lock) alla transazioni, in modo da garantire la serializzabilità di ogni schedule
- usare i timestamp delle transazioni - identificatori in base ai quali le operazioni possono essere ordinate in modo da garantire la serializzabilità
item
Gli “oggetti” della base di dati si chiamano item - possono essere tabelle, righe, tuple… e avere quindi dimensioni variabili - e sono le “unità di accesso” delle BD.
- le dimensioni degli item devono essere definite in base all’uso che viene fatto della base di dati in modo tale che, in media, una transazione acceda a pochi item
Le dimensioni degli item utilizzate da un sistema sono dette la sua granularità.
- una granularità grande permette una gestione efficiente della concorrenza
- una granularità piccola può sovraccaricare il sistema, ma aumenta il livello di concorrenza (consente l’esecuzione concorrente di molte transizioni)
domande orale
possibili domande orale
- cos’è una transazione?
- per cosa sta ACID/quali sono le proprietà delle transazioni?
- cos’è uno schedule? cos’è uno schedule serializzabile?
- che problemi possono sorgere nel controllo della concorrenza?
- cosa vuol dire schedule serializzabile?
- cos’è un item?