OpenMP compilers don’t check for dependencies among iterations in a loop that is being parallelized with a parallel for.
When we have a for loop of this form:
for (i = 1 to N) { // S1: writes/reads on location x ... // S2: writes/reads on location x}
we have to be careful when parallelising a loop - since both instructions operate on the same memory location, there is a chance that running the loop in parallel might have unwanted effects.
loop-carried dependence
When results of 1+ iterations of a loop depend on each other, we say that we have a loop-carried dependence - these cases cannot in general be correctly parallelized by OpenMP.
Dependence types
Flow dependence: RAW (Read After Write)
This is a True Dependency. It occurs when S1 writes a value to memory location x, and S2 subsequently reads that value. The execution order S1 , S2must be preserved.
Rule
The read operation (S2) must wait for the write operation (S1) to complete.
S1: Write x⟶S2: Read x
RAW Example
x = 10; // S1: Write to xy = 2 * x + 5; // S2: Read from x (needs the new value 10)
loop-carried RAW example
double v = start;double sum = 0;for(i = 0; i < N; i++){ A[i] = B[i] + 1; B[i+1] = A[i];}
the write is in iteration i, and the read is in iteration i+1
Anti-flow dependence: WAR (Write After Read)
Occurs when S1 reads a value from x, and S2 subsequently writes a new value to the same location x. If the order were to be reversed, S1 would read the wrong (new) value.
Rule
The read operation (S1) must complete before the write operation (S2) begins, to ensure S1 reads the old value.
S1: Read x⟶S2: Write x
WAR Example
y = x + 3; // S1: Read from x (needs the old value)x ++; // S2: Write to x (overwrites the old value)
Output dependence: WAW (Write After Write)
Occurs when both S1 and S2 write to the same memory location x. The execution order S1 then S2must be preserved to ensure the final value of x is the one written by S2.
Rule
The final value of x must be the one produced by the last write (S2).
S1: Write x⟶S2: Write x
WAW Example
x = 10; // S1: Write to x (sets it to 10)x = x + c; // S2: Write to x (this new value must persist)
Input dependence: RAR (Read After Read)
This is NOT an actual dependence that constrains execution order. Since both statements only read from the memory location x, their order does not affect the program’s result.
Rule
The order of two read operations does not matter for correctness.
S1: Read x⟷S2: Read x
RAR Example
y = x + c; // S1: Read from xz = 2 * x + 1; // S2: Read from x
Data dependency resolution
There are 6 techniques used to solve Data Dependency:
reduction/induction variable fix
loop skewing
partial parallelization
refactoring
fissioning
algorithm change
Reduction/Induction Variables
reduction variable ⟶ used to accumulate a value across all iterations, using an associative operation
induction variable ⟶ its value gets increased/decreased by a constant amount each iteration
example
double v = start;double sum = 0;for(i = 0; i < N; i++){ sum = sum + f(v); // S1 v = v + step; // S2 }
There are 3 data dependencies:
RAW(S1) ⟶ loop-carried dependence - caused by the reduction variable sum (iteration i+1 reads the value written in iteration i)
RAW(S2) ⟶ loop-carried dependence - caused by the induction variable v (iteration i+1 reads the value written in iteration i)
v is an induction variable because v = v + step == v = start + i*step
RAW(S2 -> S1) ⟶ loop-carried dependence - caused by the induction variable v (iteration i+1 reads in S1 (f(v)) the value written by S2 (v = v + step in iteration i)
fix
first, we can remove RAW(S2)
we do so by calculating v “by hand” every time
we can also remove RAW(S2->S1)
we do so by switching the order of the instructions
double v;double sum = 0;for(int i = 0; i < N; i++){ v = start + i*step; sum = sum + f(v);}
i = 0 ⟶ v = start
i = 1 ⟶ v = start + step
…
we now have to remove RAW(S1),
we use the reduction directive, executing the reduction in a parallel-friendly way using an openMP construct
double v;double sum = 0;#pragma omp parallel for reduction(+ : sum) private(v)for(int i = 0; i < N; i++){ v = start + i*step; sum = sum + f(v);}
Loop skewing
Loop skewing involves the rearrangement of the loop body statements.
example
for(int i = 1; i < N; i++){ y[i] = f(x[i-1]); //S1 x[i] = f(x[i] + c[i]); //S2}
RAW(S2->S1) on x - iteration i+1 reads x[i], which is written in iteration i
fix
we can make sure that the statements that consume the calculated values that cause the dependence use values generated during the same iteration
To perform loop unskewing, we unroll the loop and see the repetition pattern:
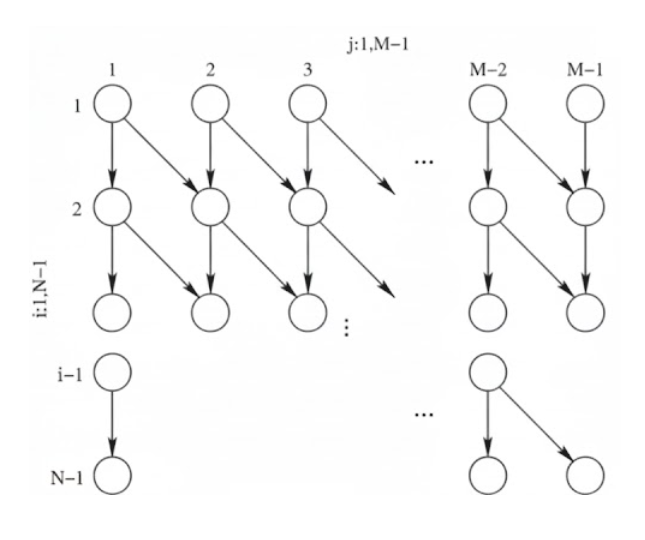
Partial parallelization
Partial parallelization can be achieved through analyzing the Iteration Space Dependency Graph. Its nodes represent a single execution of the loop body, and its edges represent dependencies.
example
for (int i = 1; i < N; i++){ for(int j = 1; j < M; j++){ data[i][j] = data[i-1][j] + data[i-1][j-1]; //S1 }}
RAW(S1) dependence
fix
the graph shows that there are no dependencies between nodes on the same row - that means we can parallelise the j-loop
for (int i = 1; i < N; i++){#pragma omp parallel for for(int j = 1; j < M; j++){ data[i][j] = data[i-1][j] + data[i-1][j-1]; }}
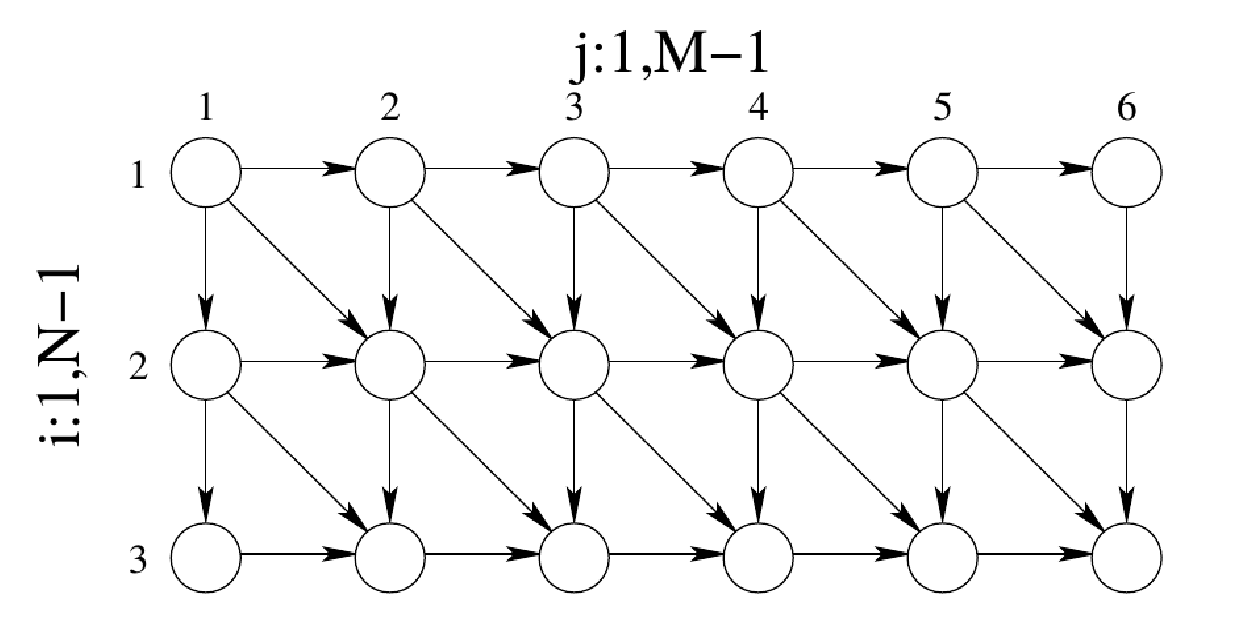
Refactoring
Refactoring consists in rewriting loops so that parallelism can be exposed.
example
for (int i = 1; i < N; i++){ for(int j = 1; j < M; j++){ data[i][j] = data[i-1][j] + data[i-1][j-1]; //S1 }}
RAW(S1) dependence
fix
the ISDG shows that there are no dependencies in diagonals from the right to the left
the intuition is:
for (wave = 0. wave < num_waves; wave++){ diag = F(wave); for (k = 0; k < diag; k++){ int i = get_i(diag, k); int j = get_j(diag, k); data[i][j] = data[i-1][j] + data[i][j-1] + data[i-1][j-1]; }}
Fissioning
Fissioning means breaking the loop apart into a sequential and a parallelizable part.
example
s = b [ 0 ];for (int i = 1; i < N; i++){ a [ i ] = a [ i ] + a [ i - 1 ]; // S1 s = s + b [ i ];}
RAW(S1) dependence
fix
the first part is executed sequentially, eliminating dependencies
// sequential partfor (int i = 1; i < N; i++) a [ i ] = a [ i ] + a [ i - 1 ];// parallel parts = b [ 0 ];#pragma omp parallel for reduction(+ : s)for (int i = 1; i < N; i++) s = s + b [ i ];
Algorithm change
if everything else fails, switching the algorithm may be the answer
example: Fibonacci
For example, the Fibonacci sequence
for(int i = 2; i < N; i++){ int x = F[i-2]; int y = F[i-1]; F[i] = x+y;}
can be parallelised via Binet’s formula 5ϕn−(1−ϕ)n