(con memoria, si intende RAM)
- le applicazioni richiedono sempre più memoria - se il sistema operativo lasciasse a ogni processo la gestione della propria memoria, ogni processo utilizzerebbe tutta la memoria a disposizione
Quindi, il Sistema Operativo gestisce la memoria, illudendo i processi di lasciare loro tutta la memoria.
- gestire la memoria include lo swap intelligente di blocchi di dati alla memoria secondaria (disco)
requisiti per la gestione della memoria
il sistema operativo, per la gestione della memoria, deve garantire:
- rilocazione e protezione
- importante che ci sia aiuto hardware
- condivisione
- organizzazione logica
- organizzazione fisica
rilocazione
Il programmatore (il compilatore o chi usa l’assembler) non sa e non deve sapere in quale zona della memoria il programma verrà caricato.
- se per caso viene copiato su disco, quando torna in memoria RAM può anche trovarsi un una posizione diversa.
I riferimenti alla memoria non sono quindi “veri”, ma devono essere tradotti nell’indirizzo fisico che rappresentano:
- o in pre-processing, o a run-time (caso in cui serve supporto hardware)
indirizzi
Un processo ha quindi:
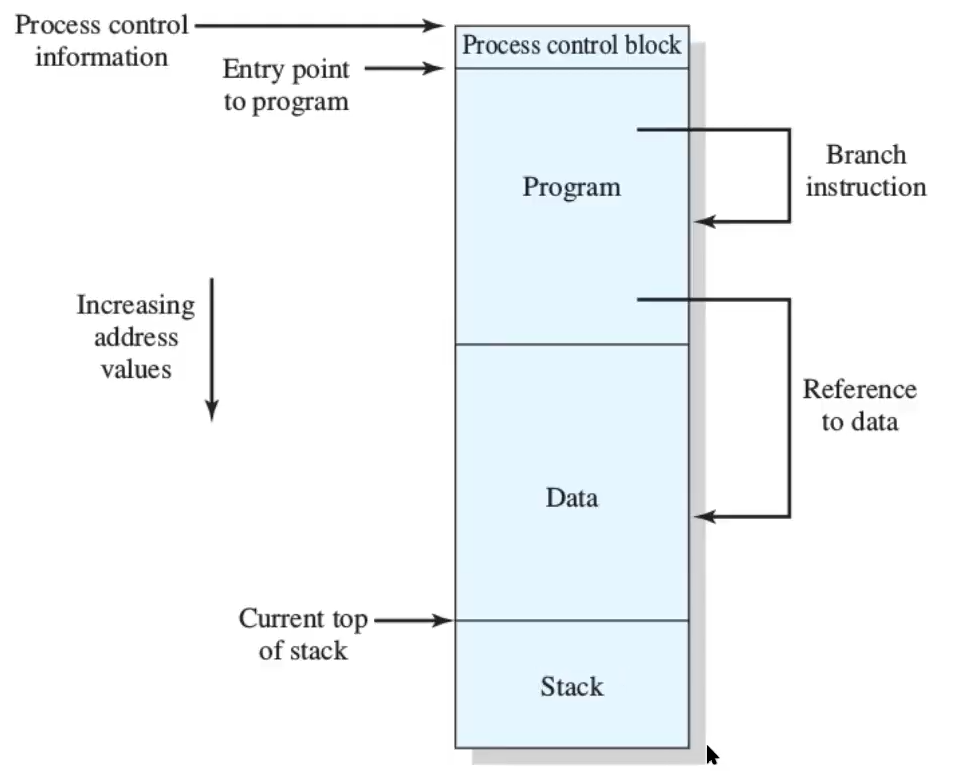
- una zona che contiene le informazioni sul processo (PCB)
- una zona con il programma in linguaggio macchina (Program)
- una zona con i dati condivisi - variabili globali (Data)
- una zona con lo stack delle chiamate
Gli indirizzi che si possono avere sono o indirizzi di salto (jump) o riferimento a dati (lw, sw…) - tutti questi devono essere ricalcolati per trovare i veri indirizzi.
compilazione di un programma
Un programma eseguibile viene prima scritto in una serie di moduli (che fanno cose diverse), tra cui uno per le librerie statiche utilizzate. Ognuno dei moduli viene compilato separatamente e si crea un file oggetto per ciascuno - il tutto viene collegato dal linker per creare un programma eseguibile - il load module, che può essere preso e caricato nella RAM dal loader. Nel farlo, potrebbe aver bisogno di librerie dinamiche.
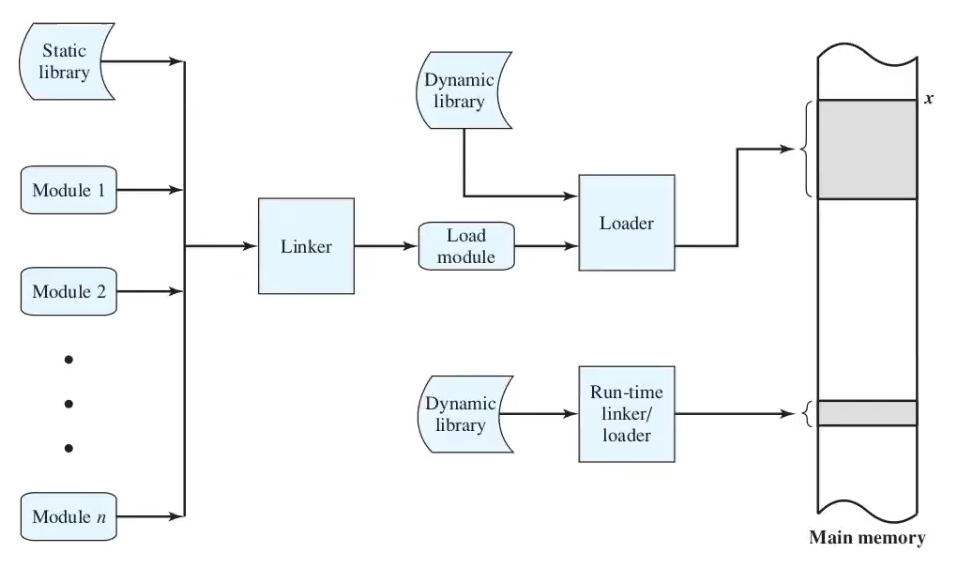
un singolo modulo è fatto da una parte di programma e una parte di dati condivisi:
- su un modulo ancora scritto su disco ci possono essere indirizzi simbolici
- invece, quando viene trasformato in qualcosa di eseguibile, ci sono due possibilità:
- indirizzo assoluto - funziona solo se si sa da dove si parte
- indirizzo relativo - suppongo di partire da 0 e uso l’indirizzo relativo rispetto al mio inizio ⟶ l’esecuzione non va alla zona di memoria x, ma x + (indirizzo dell’inizio di dove mi trovavo)
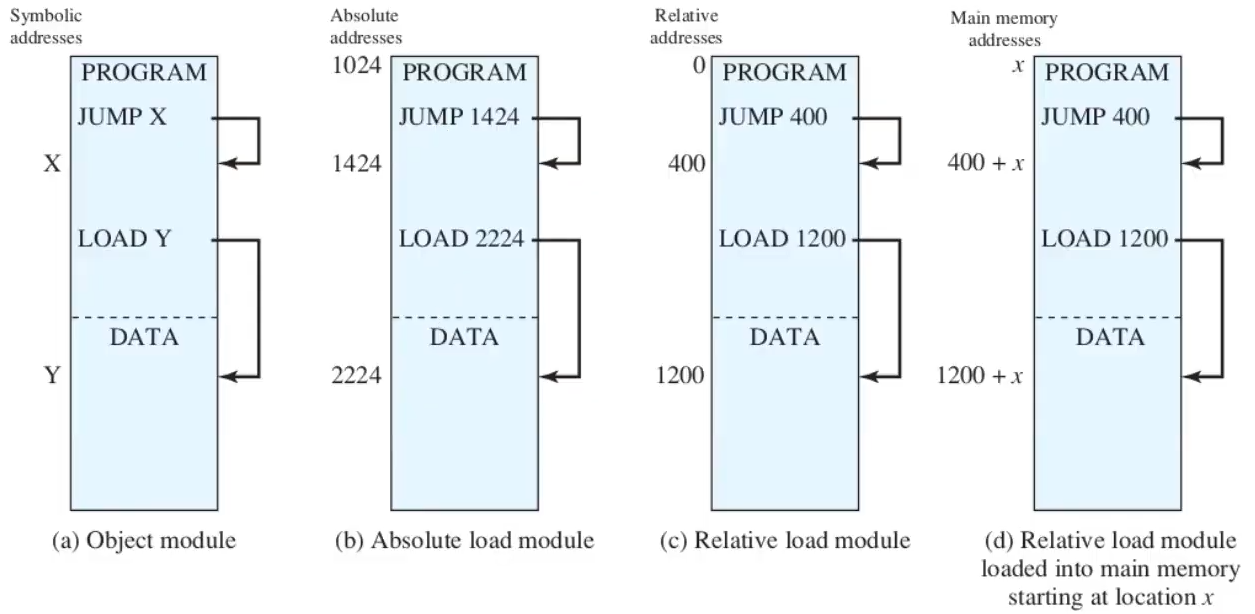
tipi di indirizzi
i tipi di indirizzi sono quindi:
- logici - il riferimento in memoria è indipendente dall’attuale posizionamento del programma in memoria - si trovano nelle istruzioni e vengono poi tradotti
- relativi - il riferimento è espresso come uno spiazzamento rispetto a un punto noto (sono un caso particolare degli indirizzi noti)
- fisici o assoluti - riferimento effettivo alla memoria
rilocazione
Vecchissima soluzione (CTSS (quindi tipo 1961)) - gli indirizzi assoluti vengono determinati nel momento in cui il programma viene caricato in memoria:
- non si può fare senza hardware dedicato
rilocazione a runtime senza hardware speciale
- ogni volta che un processo viene riportato in memoria, potrebbe essere in un posto diverso (e altri processi potrebbero aver preso il suo posto)
- bisognerebbe quindi sostituire mano a mano tutti i riferimenti agli indirizzi ad ogni caricamento in RAM
- troppo overhead: serve hardware dedicato
Soluzione più recente - gli indirizzi assoluti vengono determinati nel momento in cui si fa riferimento alla memoria
- anche qui serve hardware dedicato
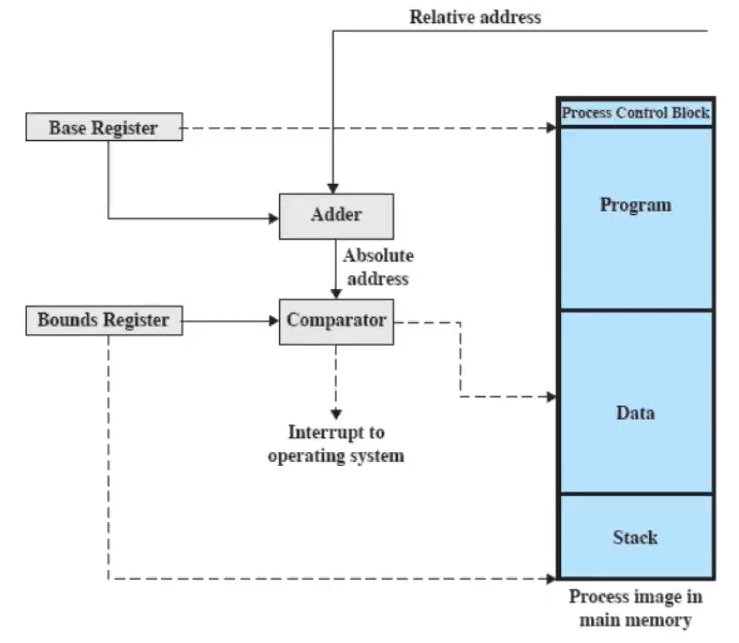
rilocazione a runtime con hardware speciale
- l’hardware della macchina sa che il valore deve essere sommato a un certo registro per ottenere l’indirizzo fisico
- il valore giusto da sommare è inserito dal sistema operativo nel Base Register
Servono quindi i registri:
- Base register
- Bounds register - indica il limite oltre il quale il processo non si può spingere
e i loro valori vengono settati quando il processo viene posizionato in memoria.
è un esempio di collaborazione tra sistema operativo e hardware: l’hardware fa sempre Base Register + Relative Address, e il Sistema Operativo deve ogni volta mettere l’inizio del processo nel Base Register.
protezione
- i processi non devono poter accedere a locazioni di memoria di un altro processo a meno che non siano autorizzati
- non si può fare a tempo di compilazione a causa della rilocazione, quindi serve aiuto hardware
condivisione
- deve essere possibile permettere a più processi di accedere alla stessa zona di memoria
- può succedere sia per opera del programmatore, che per opera del Sistema Operativo: se più processi vengono creati eseguendo più volte lo stesso codice sorgente, è efficiente che lo condividano.
organizzazione logica
a livello hardware, la memoria è organizzata in modo lineare (si parte da 0 e si va avanti), ma, a livello software non vi si può accedere così (i programmi sono scritti in moduli, scritti )
- il Sistema Operativo deve quindi fare da ponte tra il software e l’organizzazione della memoria
organizzazione fisica
- gestione del flusso di dati tra RAM e disco
- non può essere lasciata al programmatore - per esempio, se si scrive un programma che richiede troppa memoria, in passato il programmatore doveva gestire manualmente lo swapping attraverso l’overlaying (sovrapposizione di moduli nella stessa zona di memoria in tempi diversi), ma ora ci pensa il Sistema Operativo
partizionamento (senza memoria virtuale)
uno dei primi metodi per la gestione della memoria è quello del partizionamento (oggi non molto usato), che può essere:
- fisso - uniforme e variabile
- dinamico
- paginazione semplice
- segmentazione semplice
Con la memoria virtuale, i metodi invece saranno:
- paginazione con memoria virtuale
- segmentazione con memoria virtuale
partizionamento fisso uniforme
la memoria è suddivisa in partizioni di ugual lunghezza.
- se un processo ha una dimensione ⇐ di una partizione, può essere caricato in una partizione libera
- se un processo ha una dimensione maggiore, sta al programmatore organizzarlo così da non occupare mai più di una partizione in ogni momento
- il Sistema Operativo può rimuovere un processo da una partizione

- un programma potrebbe non entrare in una partizione
- uso inefficiente della memoria
- problema della frammentazione interna - all’interno di una partizione c’è una parte usata e una non usata
partizionamento fisso variabile
- mitiga i problemi di quello fisso ma non li risolve
le partizioni sono di dimensione variabile, piccole e grandi - non “dinamiche”, vengono decise all’inizio e non cambiano più.

algoritmo di posizionamento
questa organizzazione pone fin da subito un problema: dove collocare un processo? ci vuole un algoritmo !
- un processo va nella partizione più piccola che può contenerlo, per minimizzare lo spazio sprecato
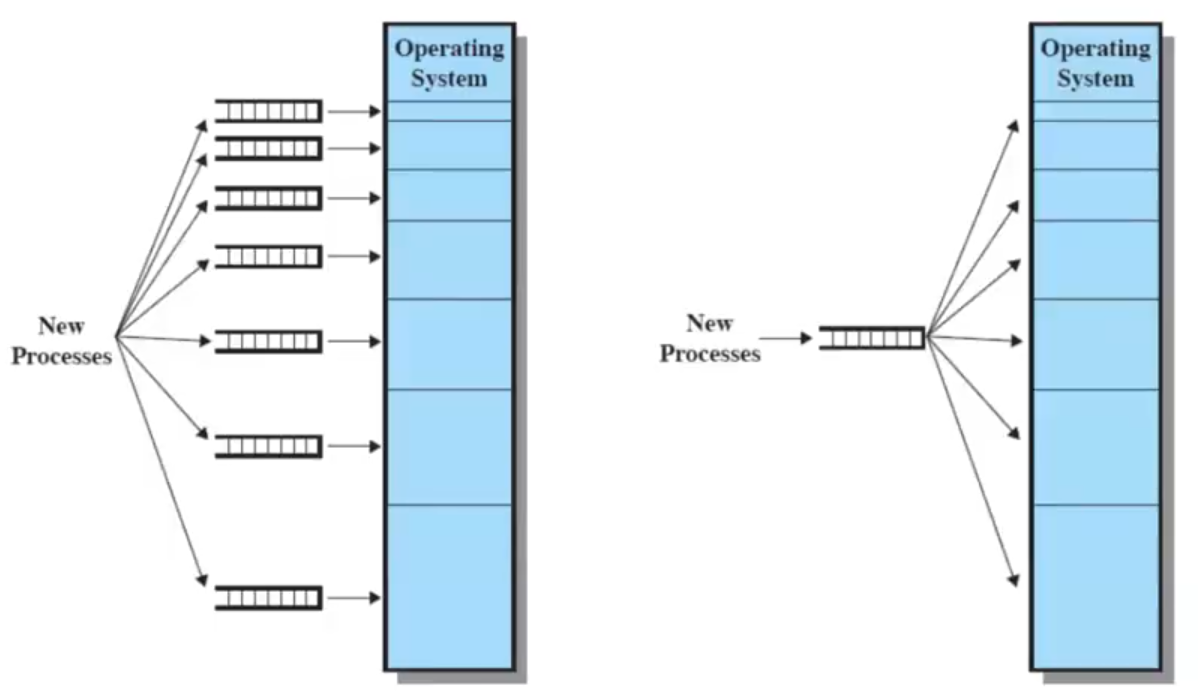
ci sono due possibilità di progettazione:
- una coda per ciascun tipo di partizione, o una coda unica
- (nel caso della coda unica, se per esempio la partizione della dimensione corretta è occupata, potrebbe essere necessario collocare un processo in una partizione più grande di esso per non far attendere i processi in coda)
rimangono dei problemi irrisolti:
- c’è un numero massimo di processi in memoria principale
- se ci sono molti processi piccoli, la memoria verrà usata in modo inefficiente
partizionamento dinamico
- le partizioni variano in misura e in quantità
- per ciascun processo viene allocata esattamente la quantità di memoria che serve
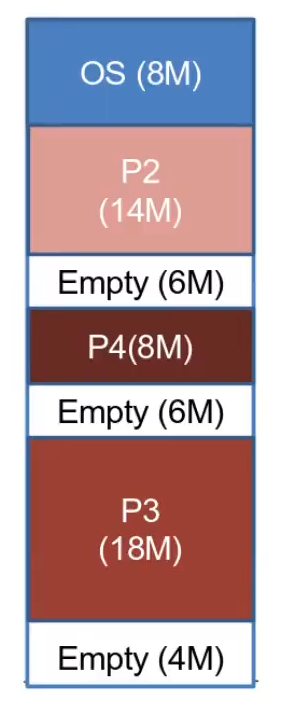
- nota: quando arriva un nuovo processo, se la memoria non basta, il Sistema Operativo sceglie un altro processo da copiare su disco e il nuovo processo lo sostituisce
problemi
Se ci troviamo nella situazione della foto e arriva un processo > 6M, la memoria libera non potrà essere “sommata” e utilizzata perché non contigua, quindi questo dovrà prendere il posto di un altro processo - frammentazione esterna: la memoria che non è usata per nessun processo viene frammentata:
- si può risolvere con la compattazione: il Sistema Operativo sposta i processi in modo che siano contigui, ma ha un elevato overhead
dove collocare un processo?
Il Sistema Operativo deve decidere a quale blocco assegnare un processo:
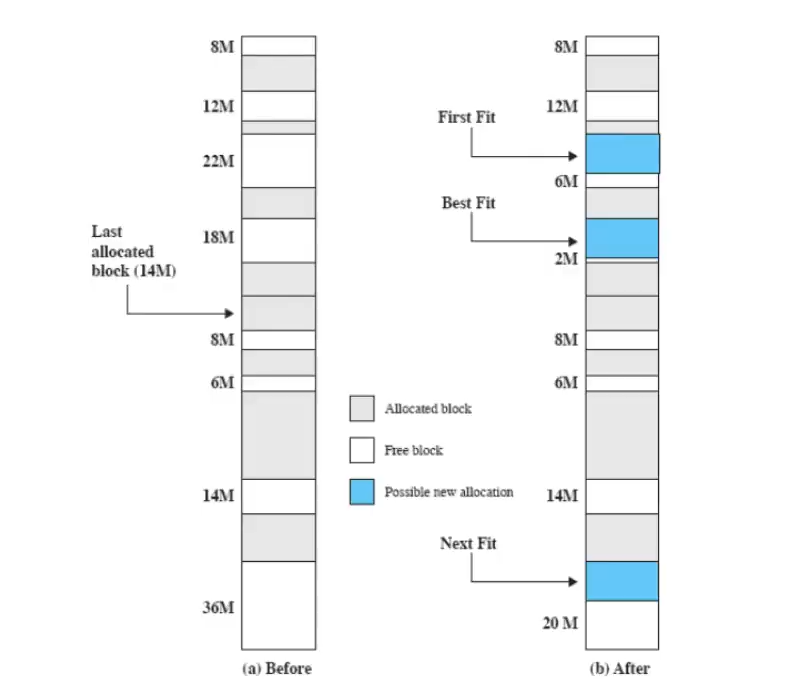
- algoritmo best-fit:
- si sceglie il blocco più piccolo tra quelli adatti
- è l’algoritmo con risultati peggiori, perché lascia frammenti molto piccoli, costringendo spesso a fare la compattazione
- algoritmo first-fit:
- comincia dall’inizio della memoria e sceglie il primo blocco con abbastanza memoria (funziona perché il partizionamento è dinamico - la memoria rimasta libera può essere assegnata)
- molto veloce, ma tende a riempire solo la prima parte della memoria
- algoritmo next-fit:
- come il first-fit, ma parte dall’ultima posizione di memoria assegnata ad un processo
- assegna più spesso il blocco a fine memoria
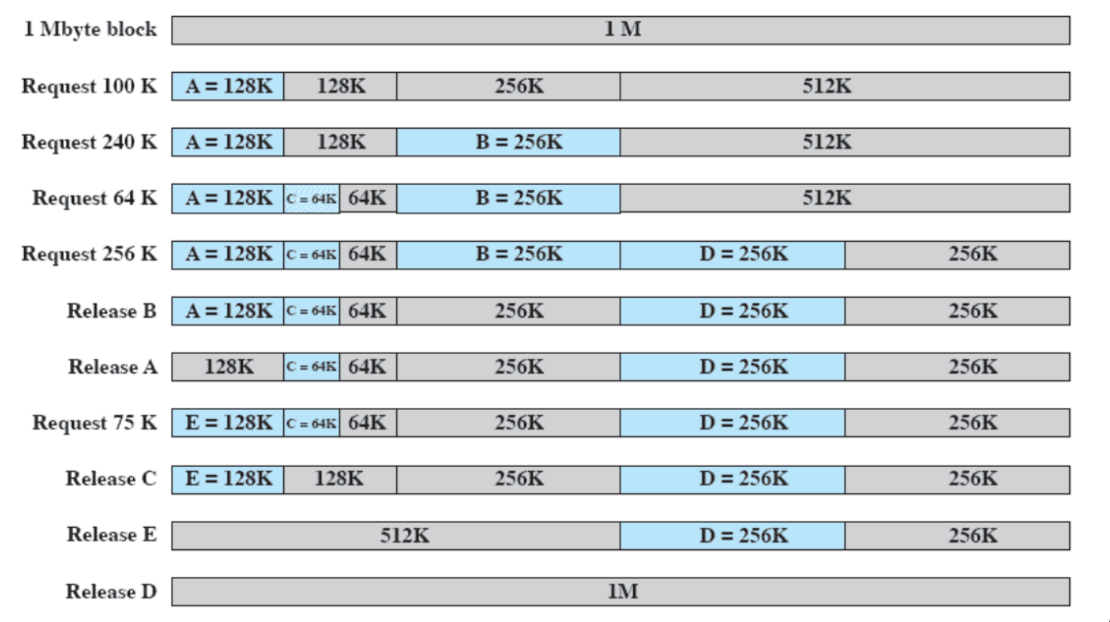
buddy-system
- compromesso tra partizionamento fisso e dinamico
Abbiamo a disposizione una dimensione per lo spazio utente di . Supponiamo che arrivi un processo che richiede bytes di RAM. Il buddy-system comincia a dividere per due fino a che non si arriva a una dimensione che è un logaritmo intero di quello che voglio (un tale che )
- con ( lower bound: non si possono creare partizioni troppo piccole).
Ho quindi creato due partizioni, e una si userà per il processo.
Quando un processo finisce, dovrei farlo combaciare con un altro (buddy) per creare una partizione libera più grande - la fusione può essere effettuata solo nel caso in cui è possibile costruire una partizione di dimensione (il successivo multiplo di due)
esempio
- bisogna stare attenti a come si ricreano le partizioni del buddy system - se rilascio B (release B), ora la sua partizione è libera, ma andrebbe ricomposta: dovrei farlo combaciare con un suo compagno per creare una porzione libera più grande (a release B non posso, perché la successiva di 256 sarebbe 512 ma non posso ancora formarla perché la memoria contigua non basta - la formo a release E)
il buddy system si presta bene ad essere rappresentato con un albero:
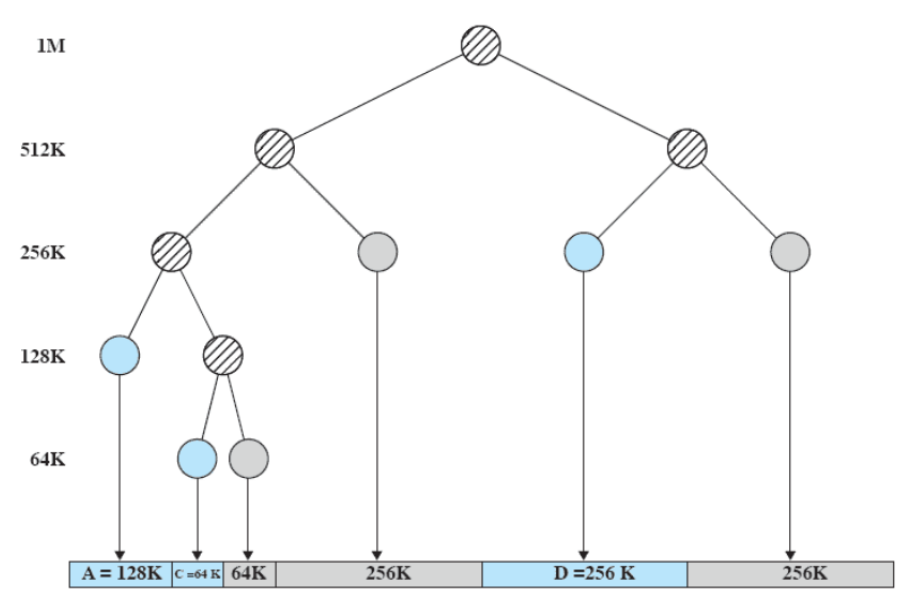
paginazione semplice
(non usata, importante concettualmente)
- sia la memoria che i processi vengono spezzettati in pezzetti di grandezza uguale e piccola
- i pezzetti di processi sono chiamati pagine
- i pezzetti di memoria sono chiamati frame
- ogni pagina, per essere usata, deve essere collocata in un frame (visto che pagine e frame hanno la stessa dimensione, avviene in maniera semplice)
- pagine contigue di uno stesso processo possono essere collocate in frame distanti (perché una pagina può essere messa in qualunque frame)
I Sistemi Operativi che adottano la paginazione devono mantenere una tabella delle pagine per ogni processo - (gli indirizzi devono essere reali, la tabella dice in quale frame effettivo si trova)
- quando c’è un process switch, la tabella delle pagine del nuovo processo deve essere ricaricata
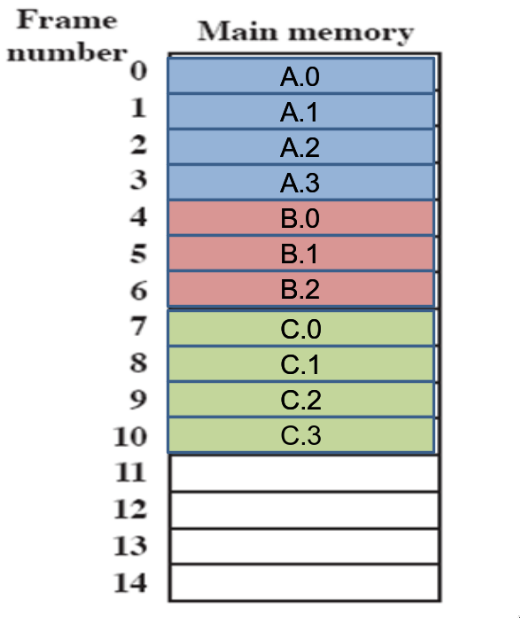
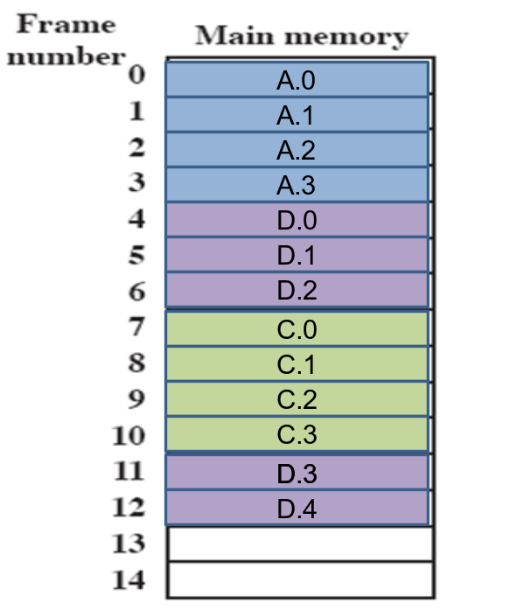
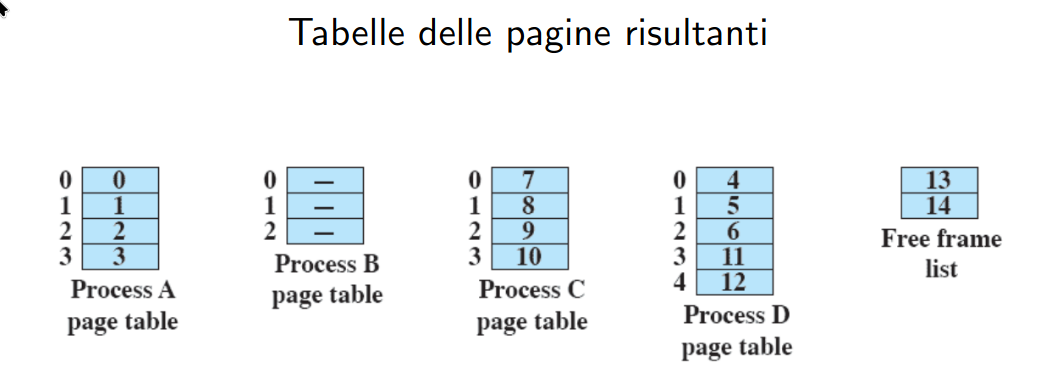
esempio
(i numeri rappresentano i numeri di frame - es. se il frame è grande 1k, dentro 0 ci saranno gli indirizzi da 0 a 1023)
partiamo con la RAM vuota:
- supponiamo che arrivino prima un processo da 4 pagine, poi uno da 3 e un altro da 4
- supponiamo poi che il processo B se ne vada, e che ne arrivi uno da 5 pagine: con il partizionamento dinamico, avrei dovuto compattare A e C per avere lo spazio necessario - qui invece non devo:
da un punto di vista delle tabelle delle pagine, la situazione è questa:

segmentazione
- un programma può essere diviso in segmenti di lunghezza variabile con un limite massimo
- un indirizzo di memoria è rappresentato da un numero di segmento e uno spiazzamento al suo interno
- come per la tabella delle pagine, ci deve essere una tabella dei segmenti, che comunichi da dove parte il segmento in RAM e la sua lunghezza
- simile al partizionamento dinamico, ma è il programmatore a decidere come deve essere segmentato un processo (a mettere i segmenti in RAM e risolvere gli indirizzi ci pensa il Sistema Operativo)
paginazione e segmentazione: indirizzi
Bisogna gestire gli indirizzi:
- anche qui, gli indirizzi sono logici - non sono i veri indirizzi in memoria
Per la paginazione:
- sappiamo che la frammentazione interna, se c’è, è molto piccola e si trova solo nell’ultima pagina del processo
- per trovare un indirizzo devo:
- capire in quale pagina si trova
- ho un offset rispetto all’inizio della pagina
- devo usare la tabella delle pagine per capire dove si trova quella pagina (dal numero di frame so dove si trova ogni pagina) e sommare l’offset
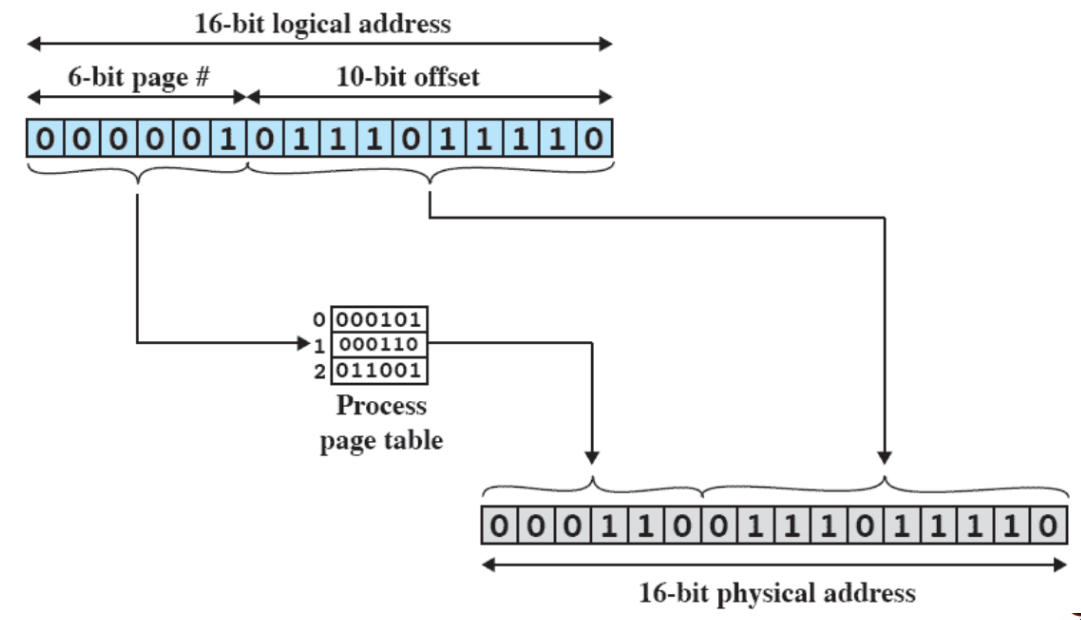
come funziona
- supponiamo che si riceva un indirizzo logico di 16 bit
- le dimensioni delle pagine sono sempre scelte per essere una potenza di 2 - per trovare la pagina dovrei dividere per la potenza di due, ma a quel punto posso direttamente ignorare gli ultimi x bit (con x=esponente di 2), e prendere i bit rimanenti - quelli avranno il risultato corretto
- invece, l’offset sarà rappresentato dal resto dei bit
- quindi, trovata la pagina nella process page table, prendo l’indirizzo e lo sostituisco a quello che era il numero della pagina (essenzialmente concatenandolo all’offset)
Per i segmenti:
- funziona in maniera analoga rispetto alla paginazione, ma bisogna considerare che i segmenti sono di dimensione variabile
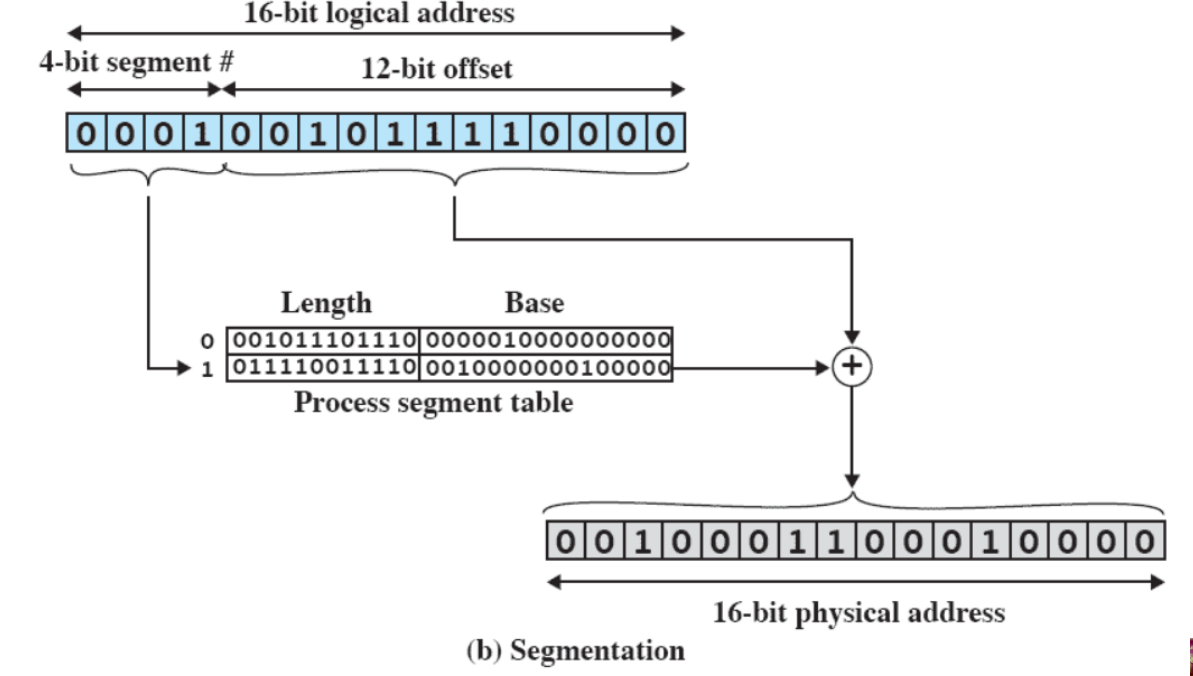
come funziona
- supponiamo che si riceva un indirizzo logico di 16 bit, e che non possano esserci segmenti più grandi di bytes
- si prende sempre la parte iniziale dell’indirizzo ignorando i 12 bit (dimensione massima) finali
- la tabella dei segmenti non può solo dirmi il numero di frame, ma da dove parte il segmento in RAM e quanto è lungo
- per ottenere l’indirizzo, bisogna sommare (vera e propria somma) l’indirizzo vero e sommare i 12 bit di offset
memoria virtuale
(veloce ripasso) concetti fondamentali
- i riferimenti alla memoria sono indirizzi logici che vanno tradotti in indirizzi fisici a tempo di esecuzione
- un processo può essere spezzato in più parti, che non devono per forza occupare sezioni contigue di memoria
l'idea geniale
Non occorre che tutte le pagine o tutti i segmenti di un processo siano in memoria principale per far sì che al processo venga concesso il processore:
- l’unica cosa che serve è che ci sia la pagina che contiene l’istruzione che va eseguita, e i dati di cui essa ha bisogno
- il sistema operativo porta in memoria principale solo alcuni pezzi (pagine) del programma - l’insieme di queste viene chiamato resident set
- quando un processo accede a una zona di memoria che non è nel resident set, avviene un page fault
- viene generato un interrupt, il Sistema Operativo va a prendere la pagina dalla memoria secondaria e la porta in RAM - questa è una richiesta di I/O a tutti gli effetti, quindi, fino a quando non sarà completata, il Sistema Operativo metterà il processo in stato blocked (e altri processi andranno in esecuzione).
- quando l’operazione viene completata, un interrupt farà sì che il processo torni ready
- quando verrà eseguito, dovrà eseguire nuovamente la stessa istruzione che aveva causato il fault
Quindi, ci sono molti benefit:
- possono esserci molti più processi in memoria virtuale
- è molto più probabile che ci sia sempre un processo ready - il processore viene sfruttato al meglio senza che diventi idle
- un processo può richiedere più dell’intera RAM disponibile
definizioni e terminologia / recap
La memoria virtuale è uno schema di allocazione di memoria, in cui la memoria secondaria può essere usata come se fosse principale
- gli indirizzi usati nei programmi (logici) e quelli usati nel sistema sono diversi (fisici) - c’è una fase di traduzione automatica da logici a fisici
- la dimensione della memoria virtuale è limitata dallo schema di indirizzamento, oltre che dalla dimensione della memoria secondaria
- si può andare ben oltre la dimensione della memoria principale
- indirizzo virtuale: indirizzo associato ad una locazione della memoria virtuale (indirizzo logico)
- spazio degli indirizzi virtuali: quantità di memoria virtuale assegnata ad un processo
- spazio degli indirizzi: quantità di memoria assegnata ad un processo (limitato alla dimensione della RAM)
- indirizzo reale: indirizzo di una locazione di memoria principale (indirizzo fisico)
effetti collaterali: il thrashing
avviene quando il Sistema Operativo passa la maggior parte del suo tempo a swappare pezzi di processi invece di eseguire istruzioni - ovvero quando quasi ogni richiesta di pagina dà luogo ad un page fault.
- per evitarlo, il Sistema Operativo cerca di indovinare quali pezzi di processo saranno utilizzati con quanta probabilità nella prossima istruzione da eseguire (sulla base della storia recente)
principio di località
trovare quali pezzi di processo saranno utilizzati, ci si basa sul principio di località, ovvero il fatto che i riferimenti che un processo fa tendono ad essere vicini (sia per i dati che per le istruzioni) - quindi si può prevedere abbastanza bene quali pezzi processi saranno necessari
supporto hardware
Anche la memoria virtuale ha bisogno di supporto hardware per la paginazione e segmentazione: il Sistema Operativo deve essere in grado di muovere pagine tra disco e RAM e tenere traccia di dove mette le cose.
paginazione
- ogni processo ha la sua tabella delle pagine
- il control block di un processo punta a quella tabella (alla prima entry)
- ogni entry della tabella contiene:
- il numero di frame in memoria principale
- (il numero di pagina è usato per indicizzare la tabella: pagina 0 riga 0 ecc)
- un bit per indicare se è in memoria principale o bisogna andarla a prendere su disco - bit di presenza
- un altro bit per indicare se la pagina è stata modificata dopo l’ultima volta che è stata caricata in memoria principale - modified bit

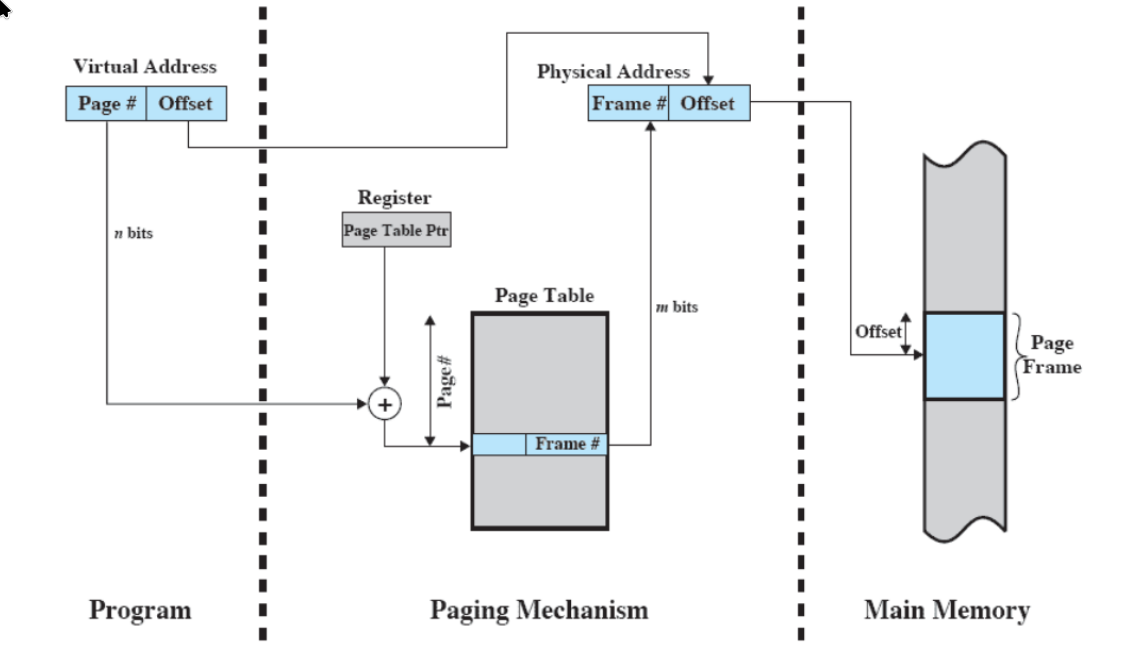
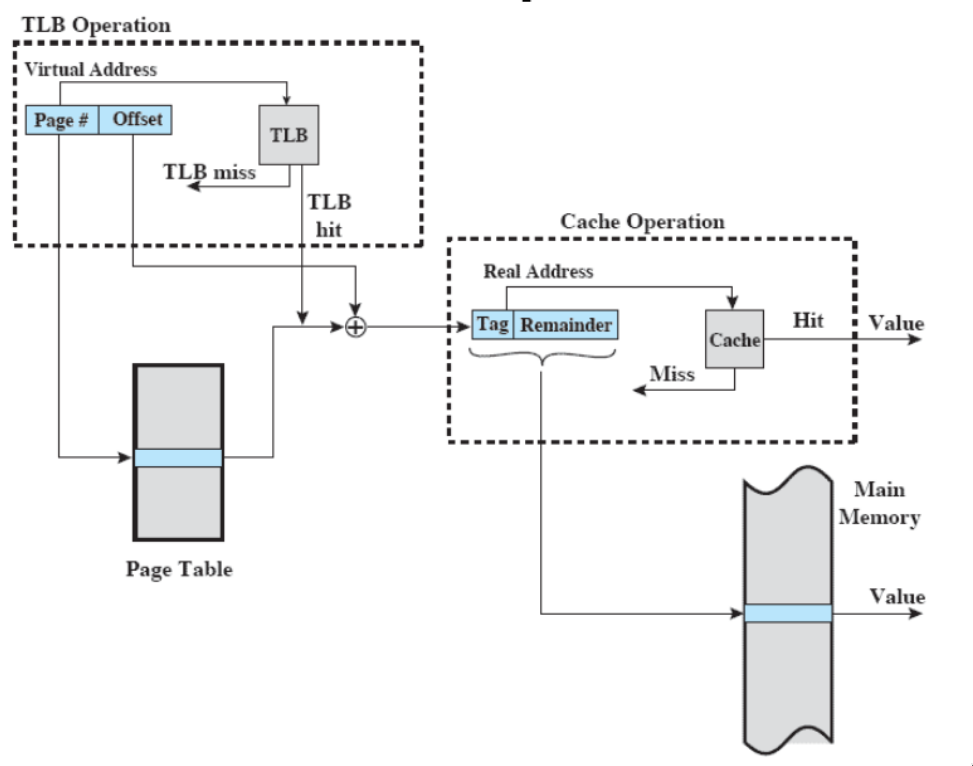
traduzione degli indirizzi
La traduzione è fatta dall’hardware.
- come detto prima, il virtual address è formato da numero di pagina e offset, con il numero di bit dell’offset = x con dimensione della pagina.
- i bit del numero di pagina vanno sommati al punto di partenza della page table, ma in realtà deve anche essere moltiplicato per il numero di byte che occupa una page table entry.
- il frame, come prima, sostituisce il numero di pagina, lasciando inalterato l’offset.
Affinché lo schema funzioni, il Sistema Operativo deve, non appena un processo viene caricato per la prima volta o c’è un process switch, mettere l’indirizzo della page table del processo in un apposito registro.
problema dell'overhead
- le tabelle delle pagine potrebbero contenere molti elementi
- quando un processo viene eseguito, viene assicurato che almeno una parte della sua tabella delle pagine sia in memoria principale
Supponiamo 8GB di RAM con 1kB per ogni pagina → (8gb/1kB) di entries per ogni tabella delle pagine.
- in un’architettura a 32 bit, mi servono: (l’indirizzo max 32 bit - 10 bit dei frame) quindi 22 bit=3byte per indicizzare i frame, + 1 byte per i bit di controllo = 4 byte per ogni entry
- per ogni processo, il Sistema Operativo si prende di overhead che non potranno essere usati per la memoria di un processo
- quindi, per esempio, con una RAM di 1GB, bastano 20 processi per occupare più di metà RAM
tabella delle pagine a 2 livelli
(ovviamente, l’hardware deve essere già costruito pensando a una tabella a due livelli)
- c’è una tabella di livello 1 che, invece di puntare a zone di RAM con al loro interno il processo, punta a zone di RAM che a loro volta contengono altre tabelle di pagine, e da lì si arriva ai processi
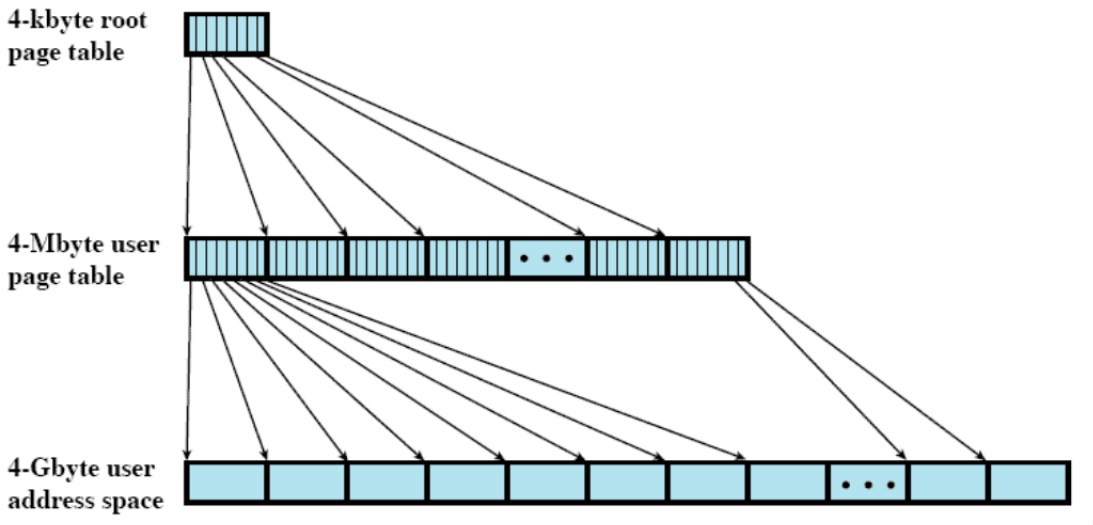
traduzione
la traduzione si complica un pochino (va spezzata in k+1 parti con k=numero di livelli)
- la prima tabella delle pagine è indicizzata dalla primissima parte dell’indirizzo - “directory” (bit che si sommano al punto di partenza della “root page table”)
- quello che si trova, sommato con la parte “di mezzo” dell’indirizzo virtuale, permette di accedere ad un’altra tabella delle pagine, che porta al numero di frame che, come prima, va solo affiancato all’offset
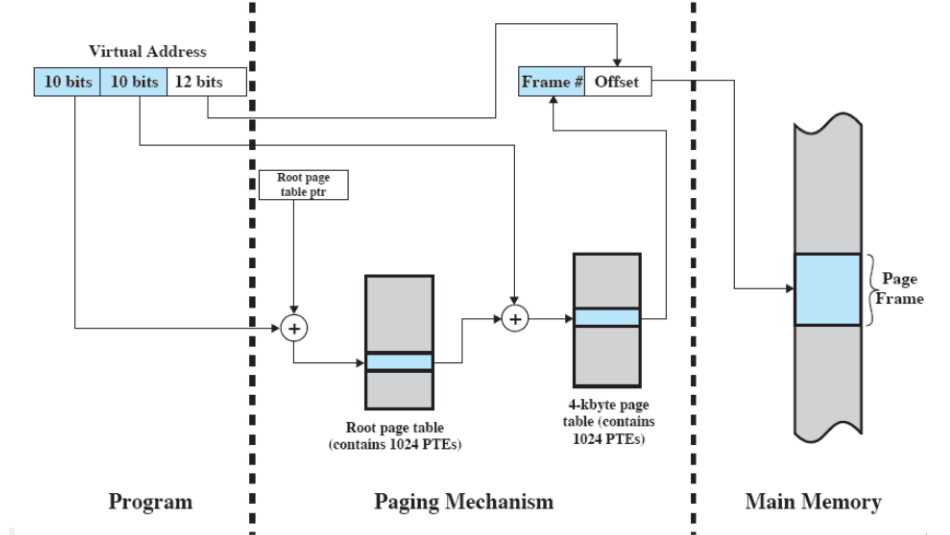
perché conviene?
Supponiamo nuovamente di avere 8GB di spazio virtuale e 33bit di indirizzo; dividiamoli in 15bit per il primo livello, 8bit per il secondo, e i rimanenti 10 per l’offset
- (spesso i processori impongono che una page table di secondo livello entri in una pagina)
Così, l’overhead di ogni processo:
- dovrebbe essere 32MB per ogni livello (come prima), più per l’occupazione del primo livello, MA:
- a questo punto diventa facile paginare la tabella delle pagine: ci basta che in RAM ci sia il primo livello (128kB), più solo una tabella del secondo livello (che entra in una pagina)
- ora, con una RAM da 1GB, ci vorrebbero 1000 processi
translation lookaside buffer
- spesso usato insieme alla memoria virtuale
- potremmo tradurlo con “memoria temporanea per la traduzione futura”
Ogni riferimento alla memoria virtuale può generare due accessi alla memoria:
- uno per la tabella delle pagine
- uno per prendere il dato
L’idea è che si usa una specie di cache per gli elementi delle tabelle delle pagine che contiene gli indirizzi di frame
- contiene le parti delle tabelle delle pagine usate più recentemente
come funziona?
- Dato un indirizzo virtuale, il processore esamina prima il TLB
- se la pagina è presente (TLB hit), prende il frame number e ricava l’indirizzo reale
- altrimenti (TLB miss) accede alla “normale” tabella delle pagine del processo
- dopodiché, il TLB viene aggiornato includendo la pagina appena consultata
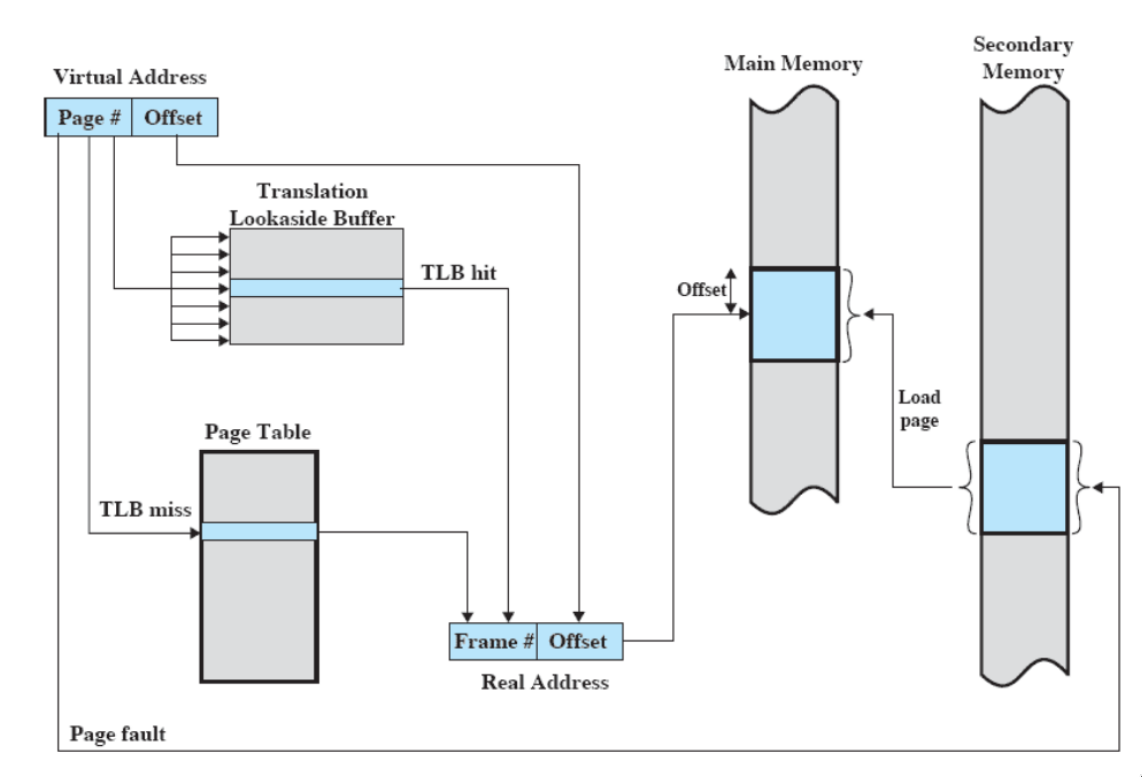
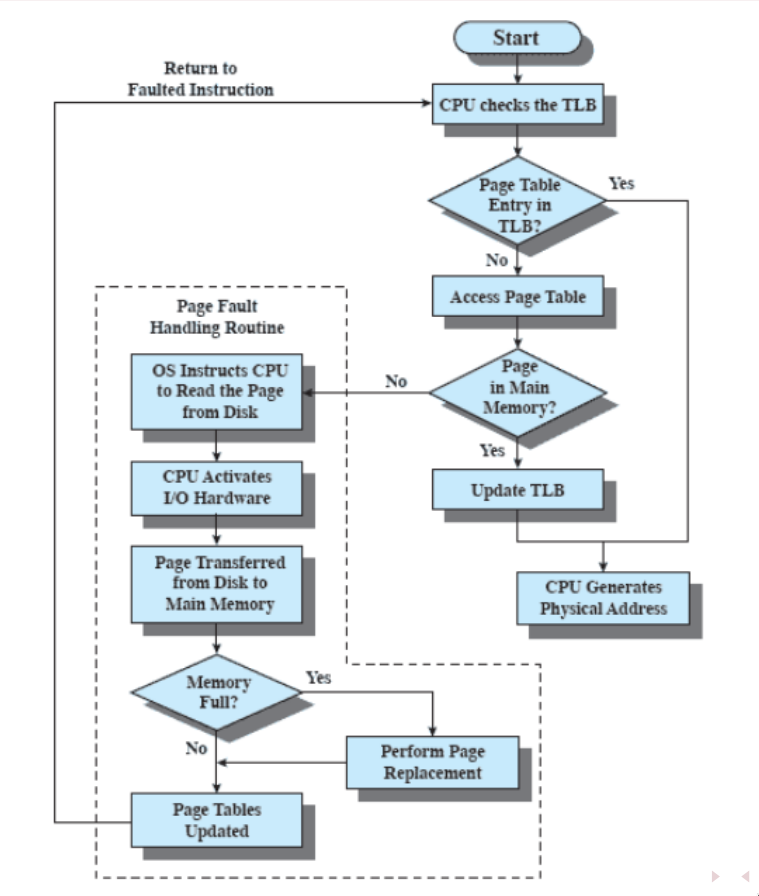
Il TLB è completamente hardware (come la cache), ma il sistema operativo entra in gioco.
- il Sistema Operativo deve poter resettare il TLB (che è relativo ad un processo, quindi ad ogni process switch deve essere resettato)
- alcuni processori permettono:
- di etichettare con il PID ciascuna entry del TLB (quindi non serve resettarlo, basta controllare il PID attuale e quello della entry del TLB)
- di invalidare alcune parti del TLB (alla fine inefficiente)
Anche senza TLB, è necessario dire al processore dov’è la nuova tabella delle pagine (step del process switch - ogni volta che cambio processo, il Sistema Operativo sa dove si trova almeno il primo livello delle page tables, e quell’indirizzo va caricato).
mapping associativo
Mentre la tabella delle pagine contiene tutte le pagine di un processo, il TLB (che deve essere veloce) contiene solo alcuni elementi. Quindi non si può accedere via indice alle entry del TLB - serve controllare, per ogni entry, se è quella che si sta cercando:
- visto che il TLB è hardware, è possibile controllare tutte le entry contemporaneamente per capire se c’è TLB hit
- questa ricerca veloce si chiama mapping associativo
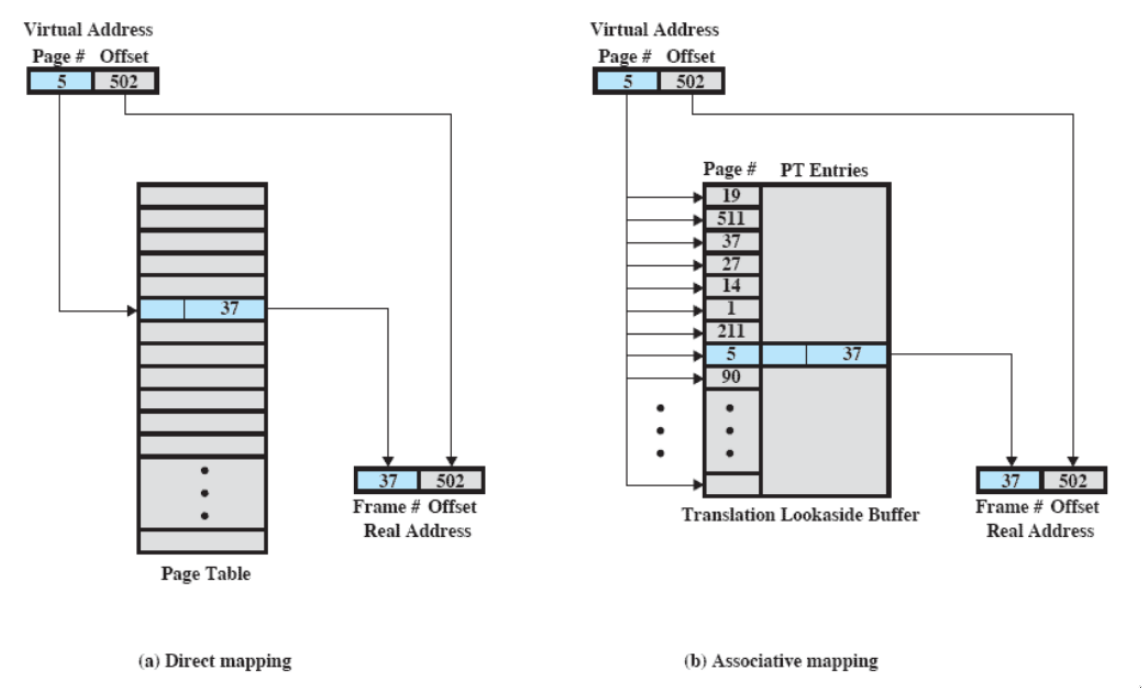
c’è un altro problema: bisogna fare in modo che il TLB contenga solo pagine che sono in RAM (una volta ottenuto il real address, non possono esserci page fault perché potrebbe essere difficile accorgersene) - quindi, ogni volta che il Sistema Operativo swappa una pagina dalla tabella delle pagine (quindi mette il bit di presenza a 0), deve anche eliminarla dal TLB.
schema generale più o meno completo
dimensione delle pagine
- più piccola è una pagina, minore è la frammentazione all’interno delle pagine
- ma anche maggiore il numero di pagine per processo
- (e più grande è la tabella delle pagine)
- quindi la maggior parte delle tabelle delle pagine finisce in memoria secondaria
- ma maggiore è il numero di pagine che si trovano in memoria principale, minori saranno i page fault (visto che i riferimenti saranno vicini)
Bisogna quindi trovare un giusto compromesso:
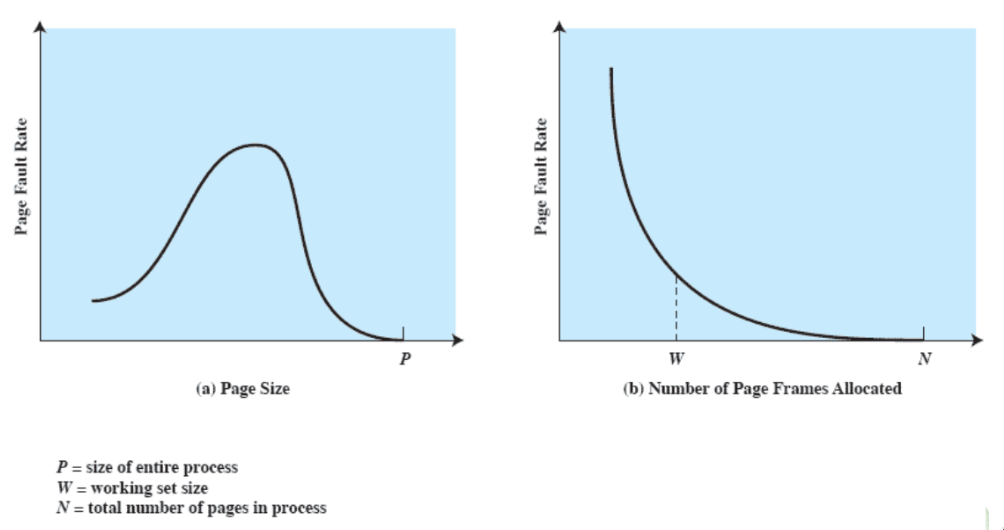
Le moderne architetture hardware supportano diverse dimensioni delle pagine (anche fino ad 1GB).
- il sistema operativo ne sceglie una: Linux sugli x86 va con 4kB
- Le dimensioni più grandi sono usate in sistemi operativi di architetture grandi: cluster, grandi server, ma anche per alcuni casi particolari di sistemi operativi stessi (kernel mode)
segmentazione (con memoria virtuale)
permette al programmatore di vedere la memoria come un insieme di segmenti di indirizzi.
- la dimensione degli indirizzi può anche essere variabile e dinamica
- semplifica la gestione di strutture dati che crescono (per esempio, lo stack delle chiamate - è tipico fare un segmento che se ne occupa)
- permette di condividere e proteggere dati in maniera semplice (metto i dati condivisi in un segmento e quelli protetti in un altro)
organizzazione
- ogni processo ha una sua tabella dei segmenti (puntata dal control block)
- ogni entry della tabella contiene:
- indirizzo di partenza in memoria principale del segmento
- lunghezza del segmento
- bit di presenza in memoria principale
- modified bit (se è stato modificato dopo l’ultima volta che è stato caricato in memoria principale)
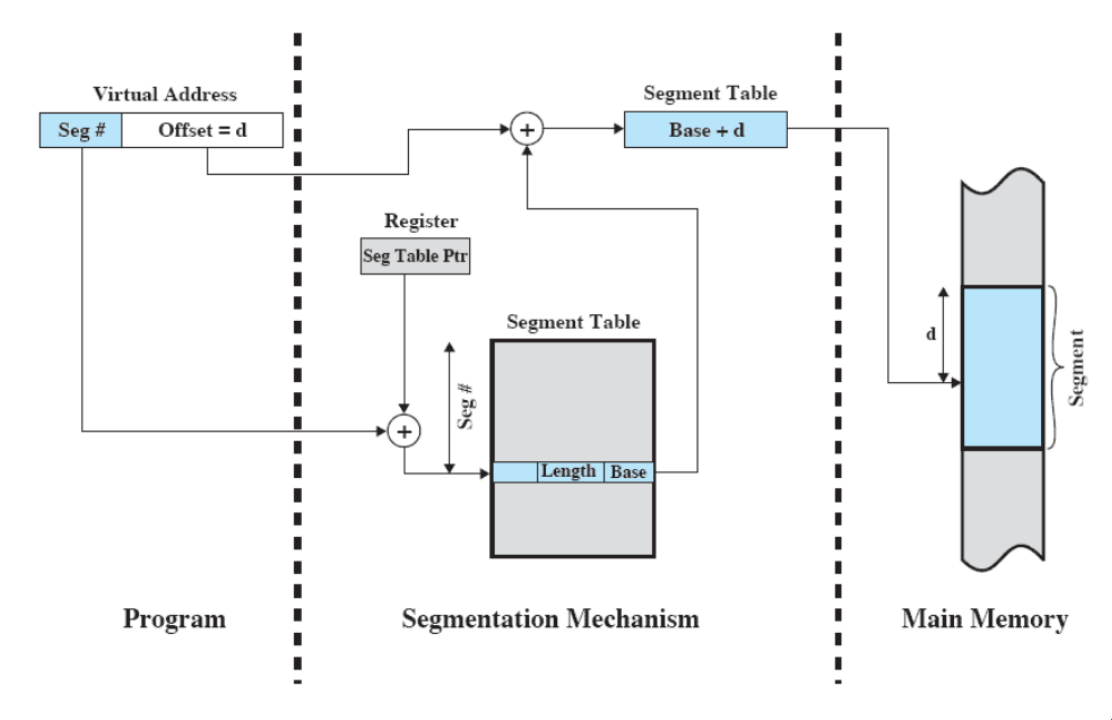
paginazione e segmentazione
- la paginazione è trasparente al programmatore (egli non ne è a conoscenza)
- la segmentazione è visibile al programmatore (se programma in assembler)
tipicamente, paginazione e segmentazione sono combinate - i segmenti possono essere enormi, e li divido in pagine.
- prima uso una parte dell’indirizzo per accedere alla tabella dei segmenti e vedo di che segmento si tratta
- quel segmento è paginato, quindi prendo il giusto frame dalla tabella delle pagine
elementi centrali per il progetto di un sistema operativo
- fetch policy
- placement policy
- replacement policy
- gestione del resident set
- politica di pulitura
- controllo del carico
il tutto, cercando di minimizzare i page fault; non c’è una politica sempre vincente
fetch policy
(partiamo con l’immagine di un processo tutta su disco) Decide quando una pagina data debba essere portata in memoria principale. Si usano principalmente due politiche:
- demand paging - quando chiedo una pagina che non è in RAM, vado su disco e la porto in memoria principale
- all’inizio ci saranno molti page fault (quando parto, in RAM c’è solo la pagina che contiene la prima istruzione da eseguire)
- prepaging - cerca di anticipare le necessità del processo, portando in RAM più pagine di quelle richieste (in base al principio di località e alla capacità dei dischi moderni, ottimizzati per trasferimento di grandi blocchi)
placement policy
decide dove mettere una pagina in memoria quando c’è almeno un frame libero.
- tipicamente, si mette nel primo frame libero (indirizzo numericamente più basso).
replacement policy
decide dove mettere una pagina in memoria quando non ci sono frame liberi.
-
come con la cache, qualche pagina va sostituita
-
una volta deciso il frame, il Sistema Operativo deve:
- prendere la pagina che ha appena preso da disco e sostituirla nella tabella delle pagine mettendo il bit di presenza a 1 e il giusto frame
- prendere la pagina che ha appena sostituito nella tabella delle pagine e mettere il bit di presenza a 0
-
bisogna evitare che la pagina appena sostituita venga subito richiesta
algoritmi di sostituzione
la RAM è piena, e per un dato processo sappiamo quanti frame bisogna allocare. come decidiamo cosa sostituire?
esempi
gli esempi che seguono usano la sequenza di richiesta a pagine: si suppone inoltre che ci siano solo 3 frame in memoria principale
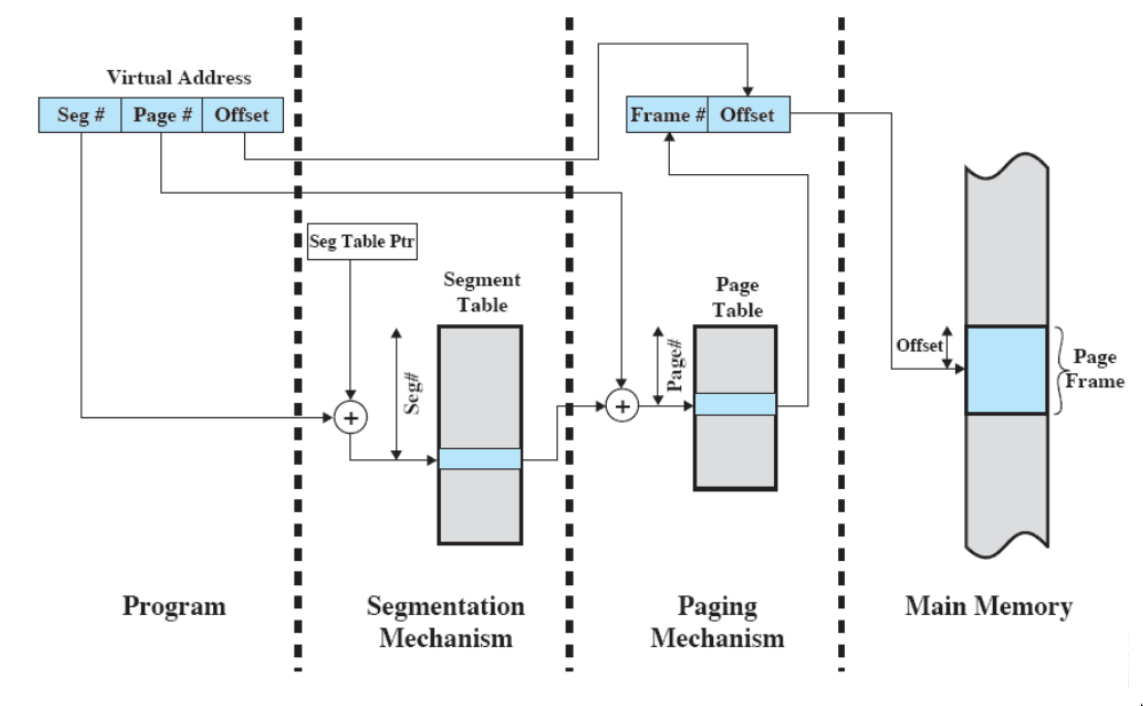
sostituzione ottima (per confronti)
- sostituisce la pagina che verrà chiesta più in là nel futuro
- ovviamente non è implementabile (perché bisognerebbe conoscere il futuro) ma viene usato per confronti sperimentali
esempio
questa policy causerebbe solo tre page faults
LRU (least recently used)
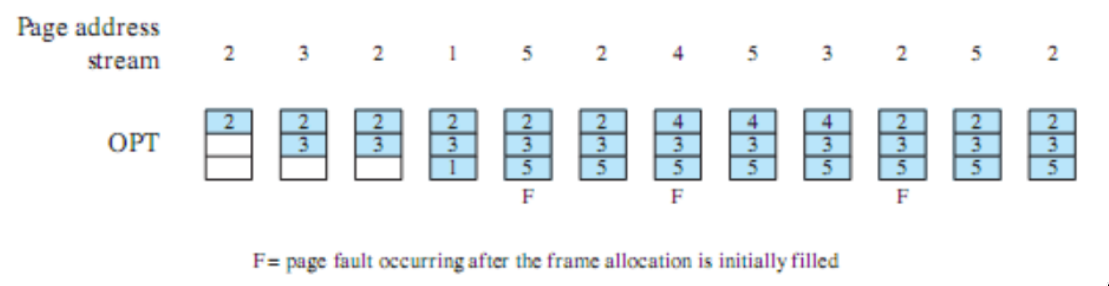
- sostituisce la pagina a cui non è stato fatto riferimento per il tempo più lungo, (per il principio di località, dovrebbe essere la pagina che ha meno probabilità di essere usata nel futuro)
- l’implementazione è problematica:
- bisogna etichettare ogni frame con il time stamp dell’ultimo accesso, e, mentre la cache usa questa tecnica perchè è implementata in hardware, per la quantità di frame della RAM è troppo costoso - tanto overhead
esempio
questa policy causerebbe solo 4 page faults (solo uno in più della soluzione ottimale)
FIFO
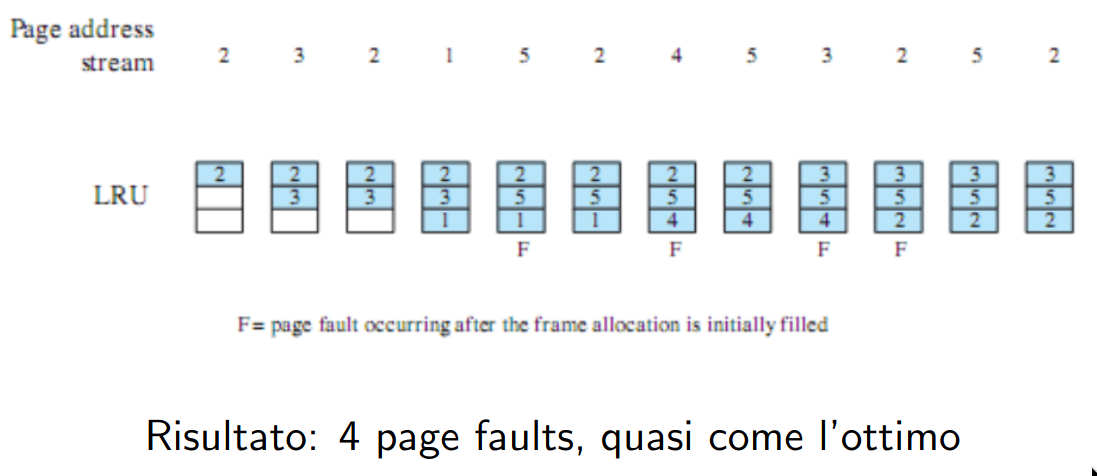
- si ricerca l’overhead minore possibile
- i frame allocati ad un qualche processo vengono trattati come una coda circolare, da cui le pagine vengono rimosse a turno (round robin)
- l’implementazione è semplice
- si rimpiazzano le pagine che sono state in memoria per più tempo (che però potrebbero servire - magari avevano molti accessi)
esempio
questa policy causa 6 page faults (non si accorge che 2 e 5 sono molto richieste)
sostituzione ad orologio (clock)
- compromesso tra LRU e FIFO
- per ogni frame, viene aggiunto uno “use bit”, che indica se la pagina caricata nel frame è stata riferita di recente
- faccio FIFO
- quando carico una pagina, lo use bit è 1, e ogni volta che c’è un riferimento (page hit) viene messo a 1
- viene invece messo a 0 durante la ricerca stile FIFO - se il Sistema Operativo incontra una pagina con il bit a 1, lo mette a 0 e procede con la prossima
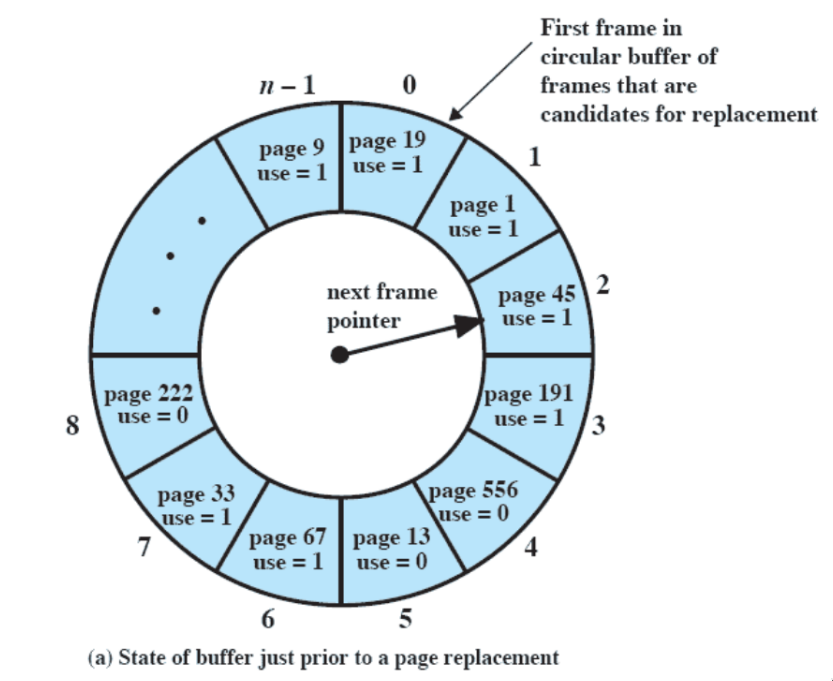
- in questo caso, il Sistema Operativo settera gli use bit di 2 e 3 a 1 e sostituirà 4.
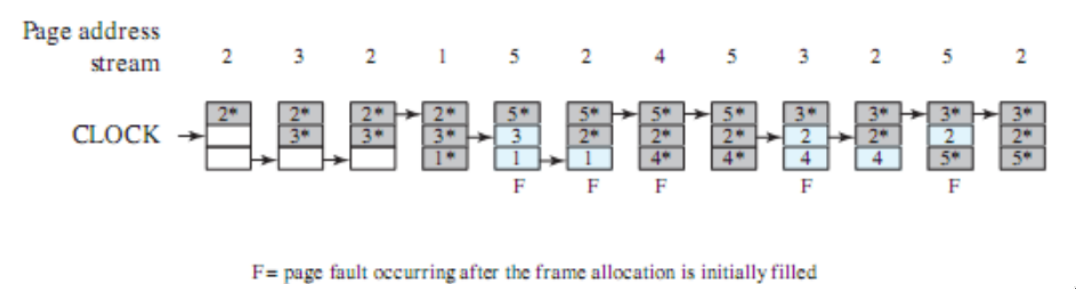
esempio
questa policy causa 5 page faults, e si accorge che 2 e 5 sono molto richieste
buffering delle pagine
una cache non-hardware per le pagine
- serve per avvicinare il FIFO alle prestazioni del clock
Si dà un po’ di memoria in meno al processo, e quella in più si uilizza come una cache.
- se decido di rimpiazzare una pagina, non la butto ma la metto in questa cache (così da riportarla velocemente in memoria se viene nuovamente referenced)
- tipicamente è divisa tra pagine modificate e non
- si cerca di scrivere le pagine modificate tutte insieme (si scrive su disco quando la lista delle pagine modificate diventa piena o quasi)
gestione del resident set
risponde a due necessità:
- resident set management - decidere, per ogni processo non ancora terminato, quanti frame vanno allocati
- allocazione fissa: il numero di frame è deciso al tempo di creazione di un processo
- allocazione dinamica - il numero di frame varia durante la vita del processo
- replacement scope - molto spesso la memoria si riempie e bisogna rimpiazzare i frame: quando questo succede, devo scegliere solo tra i frame del processo corrente o si può sostituire un frame qualsiasi?
- politica locale - si rimpiazzano solo frame dello stesso processo
- politica globale - si può scegliere qualsiasi frame
possibili strategie
Nonostante io abbia quattro opzioni, le possibili combinazioni non sono 4 ma 3: infatti, se scelgo l’allocazione fissa, non posso usare la politica globale (altrimenti si amplierebbe il numero di frame di un processo e non sarebbe più fissa)
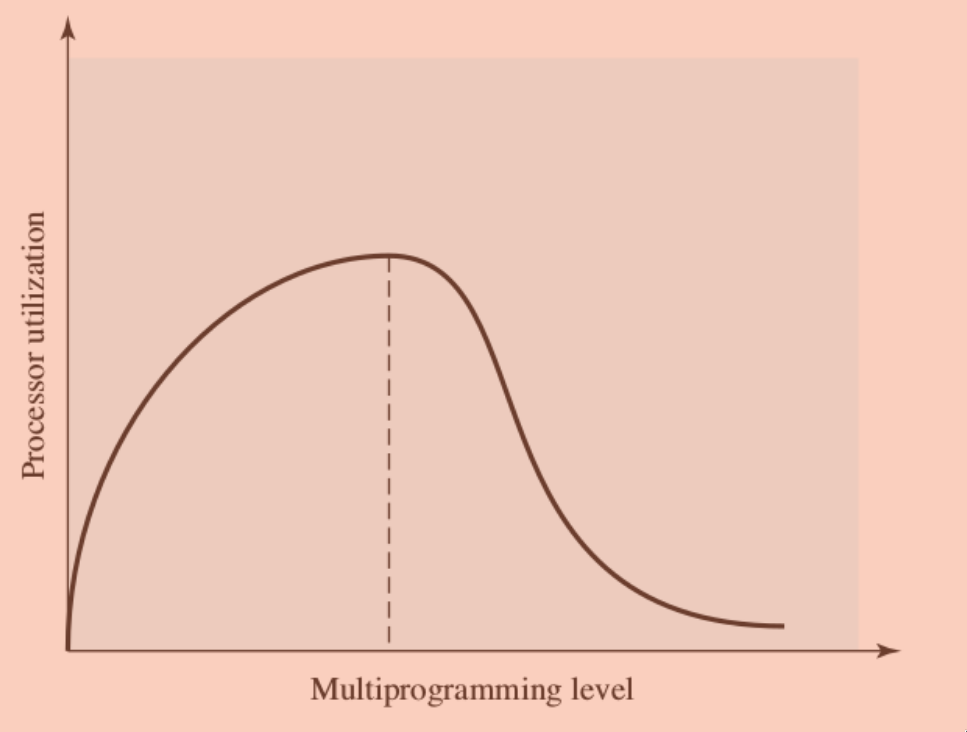
sweet spot
si nota come nel secondo grafico, lo “sweet spot” è W, non N (se carico tutte le pagine di un processo in RAM, la multiprogrammazione diminuisce drasticamente)
frame locking
bisogna tenere a mente che alcuni frame potrebbero essere bloccati: se è il caso, non possono essere sostituiti.
- di solito vengono bloccati i frame del Sistema Operativo o alcuni di altri processi
- avviene a livello di kernel tramite l’assegnazione di un bit ad ogni frame
politica di pulitura
Se un frame viene modificato, la modifica va riportata anche nella corrispondente pagina su disco. Il problema è: quando farlo?
- non appena avviene la modifica
- non appena il frame viene sostituito
(di solito, si fa una via di mezzo tra le due opzioni, intrecciata con il page buffering)
controllo del carico (medium-term scheduler)
L’idea è di cercare di mantenere più alta possibile la multiprogrammazione (quanti processi sono presenti in RAM: ovvero, nel caso della memoria virtuale, quanti hanno un resident set maggiore di 0).
- ma non deve essere troppo alta - il resident set di ogni processo sarebbe troppo basso e ci sarebbero troppi page fault
compiti del medium-term scheduler
si può controllare il carico in due modi:
- o si prende un processo
suspend(ed)e lo si rende “attivo”- si deve cercare di scegliere processi che sono o saranno ready, perché possano andare in esecuzione
- o il contrario: si prende un processo con un resident set>0 e lo si fa diventare
suspend(ed)- si deve cercare di scegliere processi o bloccati o che si bloccheranno tra poco
Per fare ciò, si usano delle politiche di monitoraggio, invocate ogni tot page fault (fanno parte dell’algoritmo di rimpiazzamento).
come si sceglie un processo da sospendere?
- processo con minore priorità
- processo che ha causato l’ultimo page fault
- ultimo processo attivato
- processo con il working set (numero di frame allocati in memoria principale) più piccolo
- processo con immagine più grande (più grande numero di pagine)
- processo con più alto tempo rimanente di esecuzione
gestione della memoria in linux
in Linux, c’è una netta distinzione tra richieste di memoria da parte del kernel e di processi utente.
- il kernel si fida di se stesso, quindi ci sono pochi controlli (se non nessuno) per richieste da parte di se stesso
- invece, per i processi utente ci sono controlli di protezione e di rispetto dei limiti assegnati
cenni di gestione di memoria del kernel
il kernel potrebbe dover aver bisogno di RAM. Può fare sia richieste di RAM molto piccole o anche molto grandi, tutte contemporaneamente. I due tipi di richieste sono gestite in maniera diversa:
- se la richiesta è piccola - fa in modo di avere alcune pagine già pronte da cui prendere i pochi bytes richiesti (slab allocator)
- se la richiesta è grande (fino a 4MB) - fa in modo di allocare più pagine contigue in frame contigui
- importante per il DMA (che permette a un dispositivo di I/O di scrivere direttamente in RAM), che ignora la paginazione e va direttamente in RAM
- usa essenzialmente il buddy system
gestione della memoria utente
- fetch policy - paging on demand
- placement policy - primo frame libero
- replacement policy - [citato sotto]
- gestione del resident set - politica dinamica con replacement scope molto globale (vi rientra anche la cache del disco)
- politica di pulitura: ritardare il più possibile le scritture
- o quando la page cache (cache del disco) è molto piena con molte richieste pending
- o quando ci sono pagine troppo “sporche” (modificate solo in RAM ma non su disco) o una pagina sporca da troppo tempo
- controllo del carico: assente
replacement policy
(in realtà, kernel più recenti usano un LRU con meno overhead)
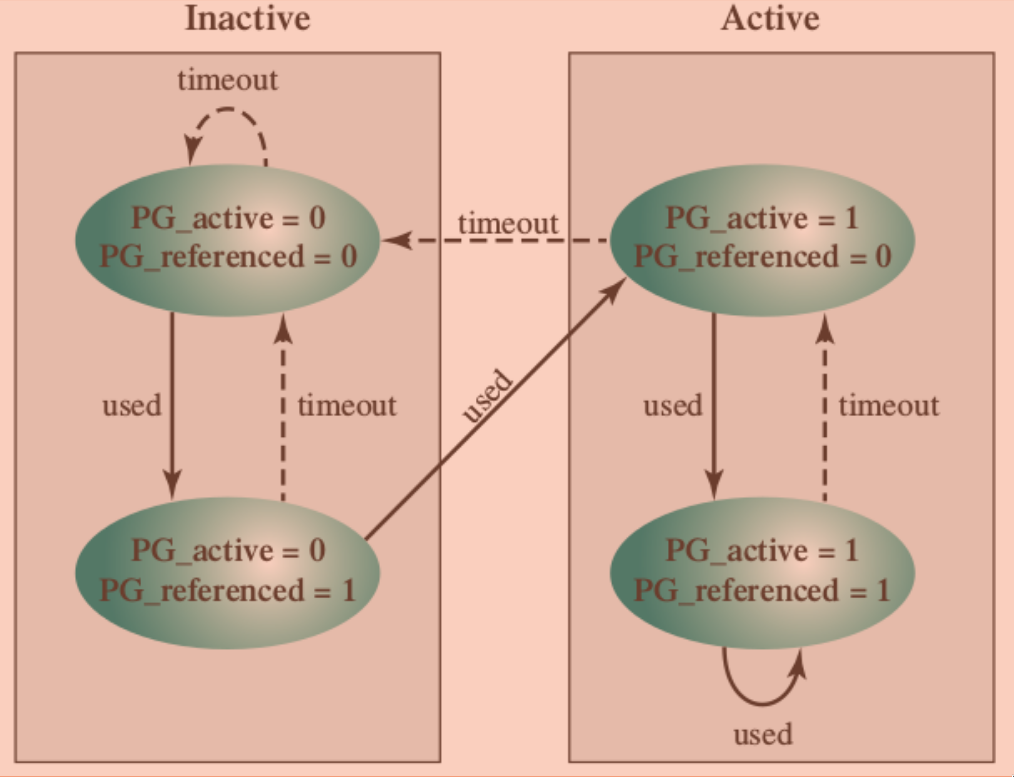
è un algoritmo dell’orologio “corretto”:
- ci sono due flag in ogni entry delle page table:
PG_referenced(è stato fatto riferimento) ePG_active(effettivamente attive)- sulla base di
PG_active, tiene due liste di pagine: attive e inattive
- sulla base di
- c’è il kernel thread
kswapd, di esecuzione periodica, che scorre solo le pagine inattivePG_referencedè settato quando la pagina viene richiesta, e poi ci sono due possibilità:- o arriva prima
kswapd-PG_referencedtorna a 0 - o un altro riferimento - quindi è stata chiesta due volte in poco tempo ed è quindi importante - diventa attiva
- o arriva prima
- chiaramente, solo le pagine inattive possono essere rimpiazzate