visione d’insieme
I file sono l’elemento principale per la maggior parte delle applicazione (fanno spesso da input e output).
- “sopravvivono” ai processi (a differenza della RAM dei processi, che viene sovrascritta)
proprietà desiderabili dei file:
- esistenza a lungo termine
- condivisibilità con altri processi (tramite nomi simbolici)
- strutturabilità (directory gerarchiche)
gestione dei file
i file sono gestiti dal File Management System - insieme di programmi e librerie di utilità che vengono eseguiti in kernel mode.
- le librerie, invece, vengono invocate come syscall (sempre in kernel mode)
Hanno a che fare con la memoria secondaria (dischi, USB…).
- in Linux, invece, selezionate porzioni di RAM possono essere trattate come file
Forniscono un’astrazione sotto forma di operazioni tipiche, e per ogni file vengono mantenuti degli attributi (metadati) - proprietario, data di creazione ecc.
operazioni su file
Le operazioni tipiche su file sono:
- creazione (e scelta del nome)
- cancellazione
- apertura
- lettura (solo su file aperti)
- scrittura (solo su file aperti)
- chiusura (necessaria per la performance)
terminologia
Si introduce della terminologia utile:
campi
- dati di base
- contengono valori singoli
- caratterizzati da lunghezza e tipo di dato
- es. carattere ASCII
record
- insieme di campi correlati, ognuno trattato come un’unità
- es. un impiegato ha i record nome, cognome, matricola ecc.
file
- hanno un nome
- sono insiemi di record correlati
- nei Sistemi Operativi generici moderni, ogni record è un solo campo con un byte
- ognuno trattato come un’unità con nome proprio
- possono implementare meccanismi di controllo all’accesso
database
- collezione di dati correlati
- mantengono relazioni tra gli elementi memorizzati
- vengono realizzati con uno o più file
- i DBMS (database managing systems) sono tipicamente processi di un Sistema Operativo
file managing systems
I sistemi per la gestione di file forniscono servizi agli utenti e alle applicazioni per l’uso di file, e definiscono il modo in cui i file sono usati.
obiettivi
- rispondere alla necessità degli utenti riguardo la gestione dei dati
- garantire che i dati nei file siano validi
- ottimizzare le prestazioni (sia dal punto di vista del Sistema Operativo - throughput - che dell’utente - tempo di risposta -)
- fornire supporto per diversi tipi di memoria secondaria
- minimizzare la perdita di dati
- fornire un insieme di interfacce standard per i processi utente
- fornire supporto per l’I/O effettuato da più utenti in contemporanea
requisiti
- ogni utente deve essere in grado di creare, cancellare, leggere, scrivere e modificare un file
- ogni utente deve poter accedere, in modo controllato, ai file di un altro utente
- ogni utente deve poter leggere e modificare i permessi di accesso ai propri file
- ogni utente deve poter ristrutturare i propri file in modo attinente al problema affrontato
- ogni utente deve poter muovere dati da un file a un altro
- ogni utente deve poter mantenere una copia di backup dei propri file (in caso di danno)
- ogni utente deve poter accedere ai propri file tramite nomi simbolici
organizzazione del codice
elementi centrali per il progetto di un sistema operativo
- Directory Management - tutte le operazioni utente che hanno a che fare con i file
- File System - struttura logica ed operazioni fisiche
- Organizzazione Fisica - da identificatori di file a indirizzi fisici su disco (allocazione/deallocazione)
- Scheduling & Control - qui ci sono i vari SCAN ecc.
le directory
Le directory sono dei file speciali. Esse contengono le informazioni sui file (attributi, posizione, proprietario) e forniscono il mapping tra nomi dei file e file stessi.
operazioni
Le operazioni che si effettuano su una directory sono:
- ricerca
- creazione file
- cancellazione file
- lista del contenuto
- modifica della directory
elementi di una directory
Gli elementi di una directory sono:
- informazioni di base:
- nome del file (unico in una directory data)
- tipo del file
- organizzazione del file (per sistemi che supportano diverse possibili organizzazioni)
- informazioni sull’indirizzo:
- volume ⟶ dispositivo su cui il file è memorizzato
- indirizzo di partenza (da quale traccia o disco)
- dimensione attuale (in byte, word o blocchi)
- dimensione allocata ⟶ dimensione massima del file
- controllo di accesso:
- proprietario ⟶ può concedere e negare i permessi ad altri utenti, e cambiare tali impostazioni
- informazioni sull’accesso ⟶ potrebbe contenere username e password per ogni utente autorizzato a leggere/scrivere
- azioni permesse ⟶ per controllare lettura, scrittura, esecuzione, spedizione tramite rete
- informazioni sull’uso:
- data di creazione
- identità del creatore
- date dell’ultimo accesso in lettura e in scrittura
- identità dell’ultimo lettore e dell’ultimo scrittore
- data dell’ultimo backup
- uso attuale (lock, azione corrente…)
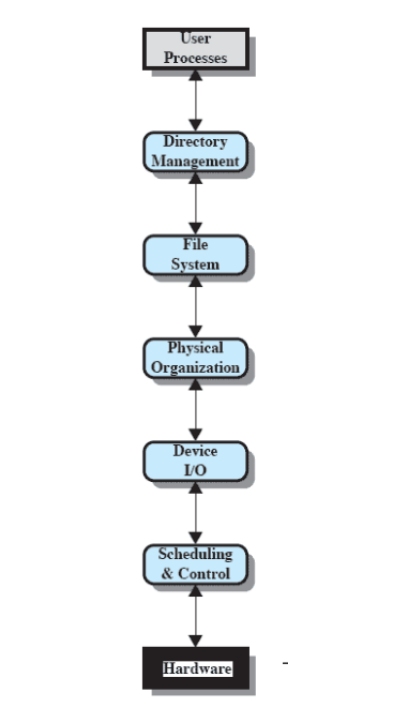
strutture per le directory
Inizialmente, il metodo usato per la memorizzazione delle informazione era quello di una lista di entry, una per ogni file. Ma questa soluzione non è sufficiente per la quantità di file presenti, e per esempio non permette di dare lo stesso nome a due file diversi. Si è passati quindi a uno schema a due livelli:
schema a due livelli
Prevede una directory per ogni utente, più una (master) che le contiene.
- la master contiene anche indirizzo e informazioni per il controllo dell’accesso
Ma ogni directory utente è solo una lista di files di quell’utente - non offre una struttura per insieme di files.
Si è quindi passati ad un modello gerarchico ad albero:
schema gerarchico ad albero
Prevede una directory master che contiene tutte le directory utente. Ogni directory utente può contenere file oppure altre directory utente.
- ci sono anche sottodirectory di sistema dentro la directory master.
nomi
Gli utenti devono poter fare riferimento ad un file usando solo il suo nome - i nomi devono essere unici (all’interno della stessa directory), ma un utente può non avere accesso a tutti i file del sistema. La struttura ad albero permette di trovare un file seguendo un directory path nell’albero.
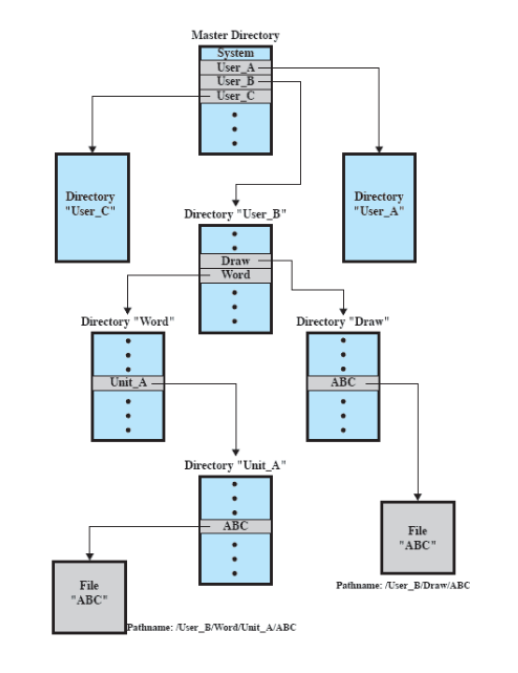
working directory
Dover dare ogni volta il path completo prima del nome di un file può essere lungo: per questo, solitamente, gli utenti o i processi interattivi hanno associata una working/current directory:
- tutti i nomi sono relativi ad essa
- è sempre possibile esplicitare l’intero percorso se necessario
gestione della memoria secondaria
Il Sistema Operativo è responsabile dell’assegnamento di blocchi a file. Ci sono due problemi correlati:
- occorre allocare spazio per i file e mantenerne traccia
- occorre tener traccia anche dello spazio allocabile.
I file si allocano in “porzioni” o “blocchi”:
- l’unità minima è il settore del disco - ogni porzione o blocco è una sequenza contigua di settori
problemi da affrontare
Per quanto riguarda l’allocazione dei file, ci sono vari problemi da affrontare:
- decidere tra preallocazione o allocazione dinamica
- decidere tra porzioni di dimensione fissa (blocchi) o dinamica (porzioni)
- decidere il metodo di allocazione: contiguo, concatenato o indicizzato.
- gestire la file allocation table, che mantiene le informazioni su dove sono, su disco, le porzioni che compongono i file
preallocazione vs allocazione dinamica
Per poter attuare la preallocazione, occorre che la massima dimensione sia dichiarata a tempo di creazione: per alcune applicazioni, è facilmente stimabile, mentre per altre non lo è - in questi casi, utenti e applicazioni sovrastimeranno la dimensione per poter memorizzare le informazioni, risultando però in uno spreco di spazio su disco, a fronte di un modesto risparmio di computazione.
Per questo l’allocazione dinamica è quasi sempre preferita:
- la dimensione del file viene aggiustata in base alle syscall
appendetruncate
dimensione delle porzioni
Per decidere la dimensione delle porzioni si hanno due opzioni agli estremi:
- si alloca una porzione larga abbastanza per l’intero file ⟶ opzione efficiente per il processo che vuole creare il file (viene allocata memoria contigua)
- si alloca un blocco alla volta ⟶ efficiente per il Sistema Operativo che deve gestire molti file
- ciascun blocco è una sequenza di settori contigui, con fisso e piccolo (spesso =1)
Si cerca quindi un trade-off tra efficienza del singolo file e del sistema: è ottimo, per le prestazioni di accesso al file, fare porzioni contigue, ma non possono essere troppo piccole (richiederebbero grandi tabelle di allocazione e quindi grande overhead). Ma bisogna anche evitare porzioni fisse grandi per non rischiare di avere troppa frammentazione interna (rimane possibile la frammentazione esterna: i file possono essere cancellati).
Alla fine, rimangono due possibilità valide:
- porzioni grandi e di dimensione variabile:
- ogni allocazione è contigua
- la tabella di allocazione non è troppo grande
- complicata la gestione dello spazio libero: servono algoritmi ad hoc
- porzioni fisse e piccole:
- (tipicamente, un blocco per porzione)
- spazio molto meno contiguo dell’opzione precedente
- per lo spazio libero basta guardare una tabella di bit
Con la preallocazione viene naturale utilizzare porzioni grandi e di dimensione variabile. Infatti, non sarebbe necessaria la tabella di allocazione - per ogni file basta l’inizio e la lunghezza (ogni file è un’unica porzione).
- come per il partizionamento della RAM si parlerebbe di best fit, first fit, next fit (ma qui non c’è un vincitore, ci sono troppe variabili).
- è però inefficiente per la gestione dello spazio libero: neccessita periodica compattazione (più oneroso che compattare la RAM).
come allocare spazio per i file
Ci sono tre modi per allocare spazio:
- contiguo
- concatenato
- indicizzato
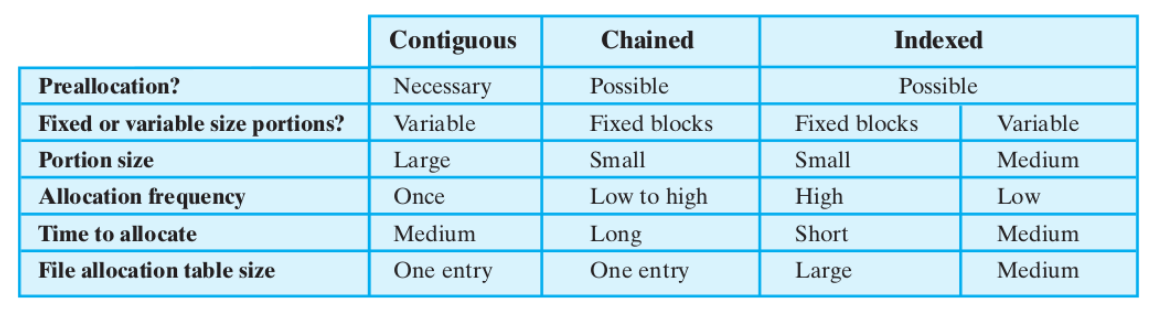
allocazione contigua
Un insieme di blocchi viene allocato alla creazione di un file.
- è necessaria la preallocazione - serve sapere quanto lungo, al massimo, sarà il file (altrimenti, se il file cresce oltre il limite massimo, può incontrare blocchi già occupati)
- basta una sola entry nella tabella di allocazione dei file: blocco di partenza e lunghezza del file
- ci sarà frammentazione esterna
allocazione contigua:
compattazione:
(la compattazione permette di memorizzare file che altrimenti non potrebbero esserlo (pur essendo la loro dimensione minore di quella dello spazio libero))
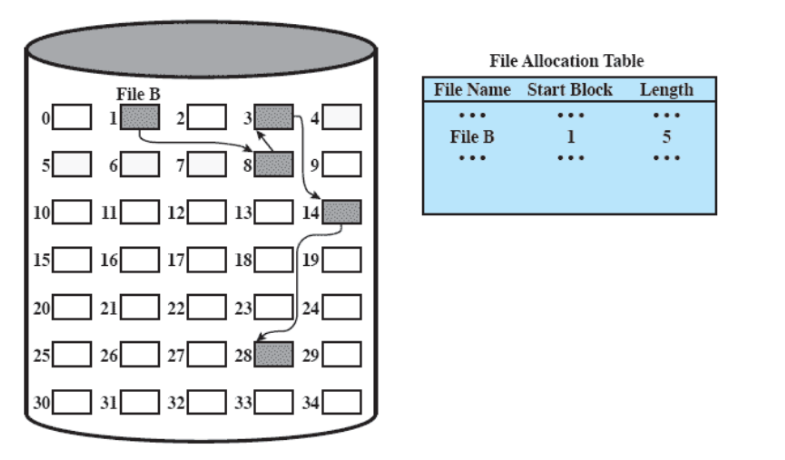
allocazione concatenata
Viene allocato un blocco alla volta, e ogni blocco ha un puntatore al blocco successivo (alla fine del blocco).
- basta una sola entry nella tabella di allocazione dei file: blocco di partenza e lunghezza del file
- non c’è frammentazione esterna
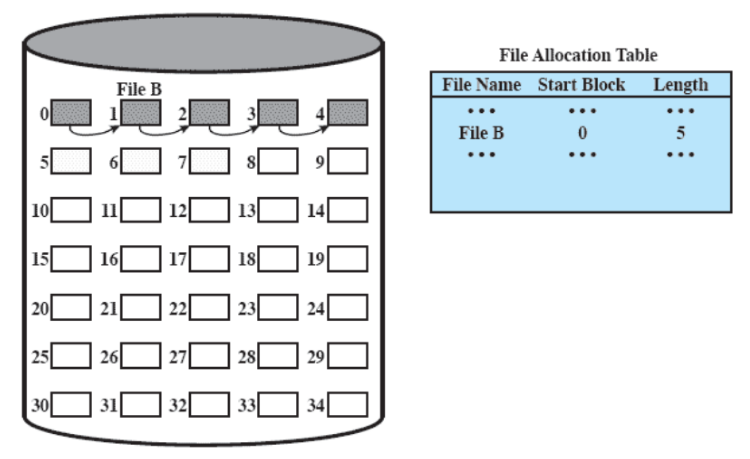
Funziona bene per accedere sequenzialmente, ma se serve un blocco che si trova a x blocchi da quello iniziale, serve scorrere tutta la lista. Per risolvere questo problema, si ricorre al consolidamento (analogo alla compattazione), per rendere contigui i blocchi di un file e migliorare l’accesso non sequenziale.
allocazione concatenata:
consolidamento:
allocazione indicizzata
L’allocazione indicizzata è una via di mezzo tra quella contigua e quella concatenata, e ne risolve quasi tutti i problemi.
- la tabella di allocazione dei file contiene apparentemente una sola entry, con l’indirizzo di un blocco, che, in realtà, ha una entry per ogni porzione allocata al file
- se il file è troppo grande, si fanno più livelli
- ci deve essere un bit che indica se un blocco è un indice o contiene dati
L’allocazione può essere con:
- blocchi di lunghezza fissa: niente frammentazione esterna (un eventuale consolidamento migliora la località)
- blocchi di lunghezza variabile: migliora la località (un eventuale consolidamento riduce la dimensione dell’indice)
allocazione indicizzata con porzioni di dimensione fissa:
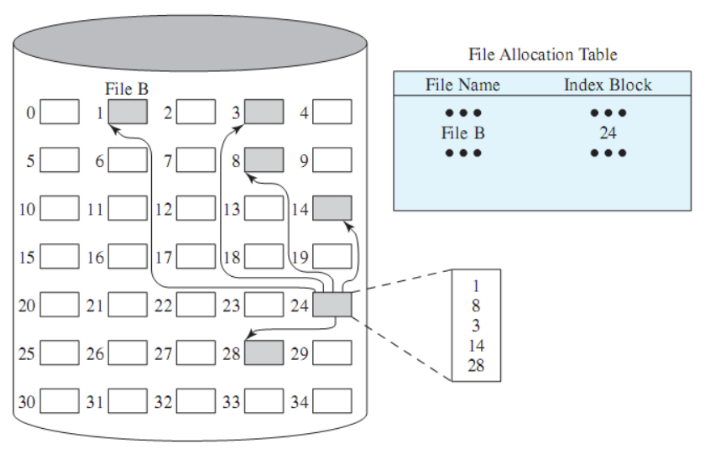
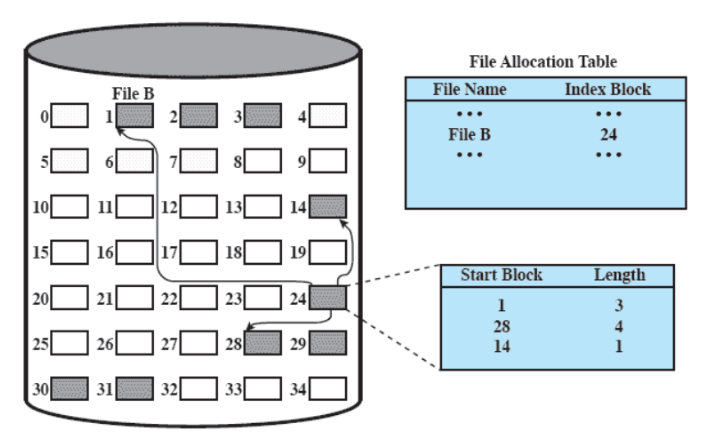
allocazione indicizzata con porzioni di lunghezza variabile:
gestione dello spazio libero
Per allocare i file, è necessario sapere dov’è lo spazio libero: non è realistico dover guardare la tabella di allocazione di tutti i file per determinare quali blocchi o porzioni sono liberi. Serve una tabella di allocazione di disco.
- ogni volta che si alloca o cancella un file, lo spazio libero va aggiornato
È necessario che si sappia in RAM (almeno in minima parte) quanto e quale sia lo spazio libero sul disco.
Ci sono vari modi per gestirla:
- tabelle di bit
- porzioni libere concatenate
- indicizzazione
- lista dei blocchi liberi
tabelle di bit
Le tabelle di bit sono vettori con un bit per ogni blocco su disco: (0 = libero, 1 = occupato).
- funziona con tutti gli schemi visti fino ad ora
- minimizza lo spazio richiesto alla tabella di allocazione del disco
Però, se il disco è quasi pieno, la ricerca di uno spazio libero può richiedere molto tempo:
- il problema è risolvibile con tabelle riassuntive di porzioni della tabella di bit
porzioni libere concatenate
Le porzioni libere possono essere concatenate le une alle altre con un puntatore e un intero per la dimensione.
- quasi zero overhead di spazio
- va bene per tutti gli schemi visti fino ad ora
problemi
- se c’è frammentazione, le porzioni sono tutte da un blocco e la lista diventa lunga
- occorre leggere un blocco libero per sapere quale sia il prossimo (se se ne allocano molti, diventa time-consuming)
- è lungo cancellare file molto frammentati
indicizzazione
Tratta lo spazio libero come un file, e usa un indice come per i file. Per motivi di efficienza, l’indice gestisce le porzioni come se fossero di lunghezza variabile: c’è quindi una entry per ogni porzione libera nel disco. È un approccio che fornisce un supporto efficiente a tutti i metodi di allocazione visti fino ad ora.
lista dei blocchi liberi
Ad ogni blocco viene assegnato un numero sequenziale, e la lista di questi numeri viene memorizzata in una parte dedicata del disco. (sembra poco efficiente ma l’overhead di spazio non è grande)
Per avere parti della lista in memoria principale, si può:
- organizzare la lista come una pila (stack), e tenere soo la parte alta (
popper allocare spazio libero,pushper deallocare spazio occupato) - quando si fanno troppi
pope si esaurisce lo spazio della porzione caricata, se ne prende una nuova parte dal disco.
volumi
Un volume è essenzialmente un “disco logico”: è una partizione di un disco, che può essere trattata in maniera indipendente dal file system, oppure è formato da più dischi messi insieme visti come un disco solo (LVM). Sono quindi un insieme di settori in memoria secondaria che possono essere usati dal Sistema Operativo o dalle applicazioni, che li vedranno come formati da settori contigui anche se non lo sono.
- un volume può essere l’unione di volumi più piccoli
dati e metadati
info
- dati ⟶ contenuto dei file
- metadati ⟶ lista di blocchi liberi, lista di blocchi all’interno dei file, data di ultima modifica ecc.
I metadati, come i dati, si devono trovare su disco (perché devono essere persistenti), ma, per efficienza, vengono tenuti anche in memoria principale. Però, mantenere consistenti i metadati in memoria principale e su disco è inefficiente - si fa quindi di tanto in tanto, quando il disco è poco usato, e con più aggiornamenti insieme.
Questa tecnica si chiama journaling, e consiste nel tenere traccia di cosa è stato modificato in una zona del disco dedicata (log), per poi scrivere tutto insieme in un secondo momento.
- in caso di reboot dopo un crash, basta leggere il log.
eventi imprevisti
Se il computer viene spento all’improvviso senza una procedura di chiusura (per esempio per mancanza di corrente), o se il disco viene rimosso senza dare un appropriato comando (
unmount), ci potrebbero essere problemi. Per risolverli, basta scrivere un bit all’inizio del disco, per indicare se il sistema è stato spendo correttamente. Al reboot, se il bit è0, occorre eseguire un programma di ripristino del disco, operazione assai complessa senza il journaling - con il journaling, invece, basta consultare il log.
journaling
Per il journaling, è necessaria una zona dedicata del disco in cui scrivere le operazioni, prima di farne il commit nel file system.
- generalmente, viene implementato come log circolare
- evita di avere file system corrotti:
- se la scrittura nel journal è completa, in caso di crash è possibile recuperare l’errore
- se invece c’è un crash durante la scrittura nel journal, il file system rimane integro
recupero dati
Se al reboot il bit di shutdown è 0:
- si confronta il journal allo stato corrente del file system
- si correggono le inconsistenze nel file system basandosi sulle operazioni salvate nel journal
Ci sono due tipi di journaling:
- fisico ⟶ copia nel journal tutti i blocchi che dovranno essere scritti nel file system, inclusi i metadati
- nel caso di crash, basta copiare il contenuto del journal nel file system al boot successivo
- logico ⟶ copia nel journal soltanto i metadati delle operazioni effettuate
- nel caso di crash, si copiano i metadati dal journal al file system, ma si rischia la corruzione di dati (per esempio un append modifica la lunghezza, ma i contenuti aggiunti sono andati persi perché non salvati nel journal)
alternative al journaling
- Soft Updates File Systems → Le scritture su file system sono riordinate in modo da non avere mai inconsistenze, o meglio, consentono solo alcuni tipi di inconsistenze che non portano a perdita di dati (storage leaks)
- Log-Structured File Systems → L’intero file system è strutturato come un buffer circolare, detto log: dati e metadati sono scritti in modo sequenziale, sempre alla fine del log e ci possono essere diverse versioni dello stesso file, corrispondenti a diversi momenti.
- Copy-on-Write File Systems → Evitano sovrascritture dei contenuti dei file; scrivono nuovi contenuti in blocchi vuoti, poi aggiornano i metadati per puntare ad i nuovi contenuti.
gestione file in UNIX
In UNIX, esistono sei tipi di file:
- normale
- directory
- speciale (mappano su nomi di file i dispositivi di I/O)
- named pipe (per far comunicare i processi)
- hard link (collegamenti, nome di file alternativo)
- symlink (il contenuto è il nome del file a cui si riferisce)
inode
UNIX utilizza l’inode - sta per “index note” -, ispirato al metodo di allocazione indicizzata con dimensione fissa dei blocchi. L’inode è una struttura dati che contiene le informazioni essenziali per un dato file.
tip
Un inode potrebbe essere associato a più nomi di file (attraverso hard link), ma un inode attivo è associato ad un solo file, e ogni file è controllato da un solo inode.
Il Sistema Operativo mantiene una tabella per tutti gli inode corrispondenti a file aperti in memoria principale, mentre tutti gli altri inode solo in una zona di disco dedicata (i-list).
inode in freeBSD
(freebsd è più unix-like di linux) All’interno di un inode, sono contenuti:
- tipo e modo di accesso del file
- identificatore dell’utente proprietario e del gruppo a cui appartiene
- tempo di creazione e di ultimo accesso (lettura o scrittura)
- flag utente e flag per il kernel
- dimensione delle informazioni aggiuntive
- altri attributi (controllo di accesso e altro)
- dimensione
- numero di blocchi, o numero di file
- dimensione dei blocchi
- sequenze di puntatori ai blocchi
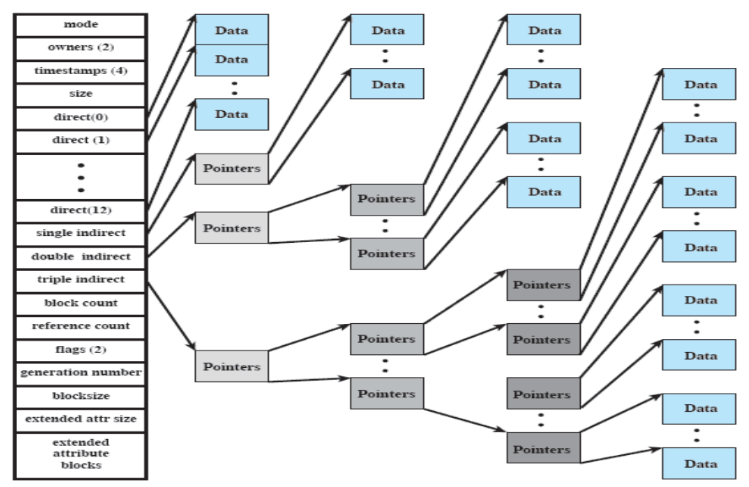
Per file piccoli (di grandezza massima di ), i dati sono puntati direttamente da direct (quindi puntano direttamente ai blocchi che contengono i dati). I puntatori indiretti, invece, puntano ai cosiddetti “blocchi di indirizzamento”, in cui sono contenuti gli indirizzi dei blocchi in cui si trovano i datii. Questi vengono utilizzati sono nel momento in cui i puntatori diretti non sono sufficienti.
allocazione di file
L’allocazione di file è dinamica e viene fatta a blocchi (anche non contigui). L’indicizzazione tiene traccia dei blocchi dei file, e parte dell’indice è memorizzata nell’inode (che ha alcuni puntatori diretti e 3 indiretti).
inode e directory
Le directory sono file che contengono una lista di coppie (nome file, puntatore ad inode).
Alcuni di questi file possono essere a loro volta directory (struttura gerarchica).
- una directory può essere modificata solo dal sistema operativo, ma letta da ogni utente.
accesso ai file
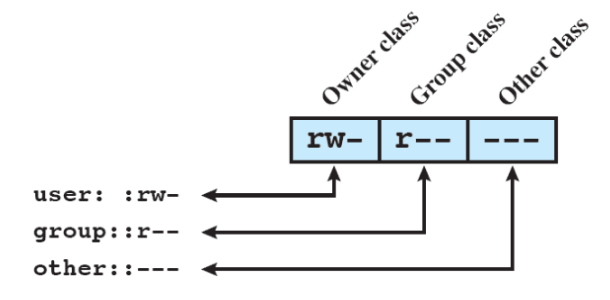
Per ogni file, ci sono tre terne di permessi:
- lettura, scrittura, esecuzione
- per il proprietario, per il suo gruppo, per tutti gli altri
gestione file condivisi
Per gestire file condivisi, fare copie è inutilmente costoso - si usano quindi i symlink e gli hardlink ! Per i symlink, esiste un solo descrittore del file originale (es. i-node), e i symlink contengono il cammino completo sul file system verso il file.
- possono esistere symlink a file non più esistenti
Gli hardlink sono invece puntatori diretti al descrittore del file originale (es. i-node). Il file condiviso non può essere cancellato finché esiste un link remoto ad esso.
- l’i-node contiene un contatore dei file che lo referenziano
UNIX: regioni del volume

(manca i-node list)
- boot sector ⟶ simile al blocco di boot per FAT (vedi sotto) - contiene informazioni e dati necessari per il bootstrap
- superblock ⟶ contiene informazioni sui metadati del filesystem, e ce ne sono copie ridondanti (in gruppi di blocchi sparsi del fs, tranne la prima copia, che è sempre in una parte prefissata) in caso di corruzione
- i-list ⟶ lista numerata di i-node (un i-node per ogni file salvato nel sistema). Ciascun i-node nella lista punta ai blocchi dei file nella sezione data del volume
kernel e i-node
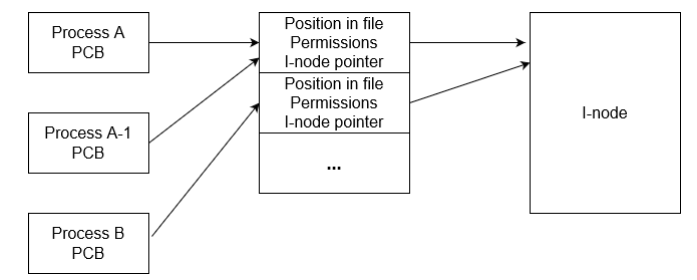
Il Kernel UNIX usa due strutture di controllo separate per gestire file aperti e descrittori i-node:
- puntatore a descrittori dei file attualmente in uso, salvato nel PCB
- una tabella globale di descrittori di file aperti, mantenuta in un’apposita struttura dati
linux
Linux, nativamente, supporta:
- ext2 ⟶ dai file system Unix originari
- ext3 ⟶ ext2 + journaling
- ext4 ⟶ ext3 in grado di memorizzare singoli file >2TB e file system >16TB
Ha inoltre pieno supporto per gli i-node, memorizzati nella parte iniziale del file system. Permette anche di leggere altri file system, come quelli di Windows.
gestione dei file su windows
Su Windows esistono due tipi di file system:
- FAT - file system vecchio (da MS-DOS) ⟶ allocazione concatenata con blocchi (cluster) di dimensione fissa
- NTFS - file system nuovo ⟶ allocazione con bitmap, con blocchi (cluster) di dimensione fissa
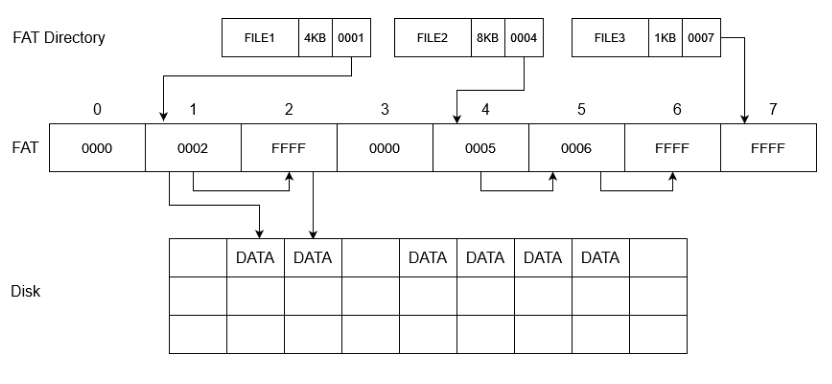
FAT
- sta per File Allocation Table
È una tabella ordinata di puntatori, ed è ancora usata per le chiavette USB. Essa stessa può occupare molto spazio. Usa un puntatore (riga nella tabella) per ogni cluster del disco.
- ogni cluster ha dimensione variabile (può cambiare da partizone a partizione, ma resta fissa all’interno di una partizione) ed è costituito da settori di disco contigui - la tabella cresce quindi con la grandezza della partizione.
- i puntatori sono valori di 12, 16 o 32 bit.
La parte della FAT relativa ai file aperti deve essere sempre mantenuta interamente in memoria principale. Infatti, consente di identificare i blocchi di un file e accedervi seguendo i collegamenti nella FAT (un file è una catena di indici - è una via di mezzo tra allocazione concatenata e indicizzata).
regioni del volume

boot sector
contiene informazioni necessarie per l’accesso al volume:
- tipo e puntatore alle altre sezioni del volume
- bootloader del sistema operativo in BIOS/MBR
regione FAT
contiene due copie della file allocation table, sincronizzate ad ogni scrittura su disco ⟶ ridondanza utile in caso di corruzione
- mappa il contenuto della regione dati, indicando a quali directory/file i diversi cluster appartengono
regione root directory
E’ una directory table che contiene tutti i file entry per la directory root di sistema (che ha dimensione fissa e limitata in FAT12 e FAT16). Contiene quindi tutti i metadati dei file (nome, timestamp, dimensione, ecc.) In FAT32 è inclusa nella regione dati, insieme a file e directory normali, e non ha limitazioni sulla dimensione
regione dati
E’ la regione del volume in cui sono effettivamente contenuti i dati dei file e directory. Le directory, chiaramente, seguono la struttura FAT vista prima, i files sono semplicemente i dati contenuti nei vari cluster.
funzionamento
Data la tabella FAT di puntatori, il puntatore i-esimo:
- se è
0, indica che l’i-esimo cluster del disco è libero - se è tutti
1, vuol dire che è l’ultimo blocco del file - else, indica il cluster dove trovare il prossimo pezzo del file (oltre che la prossima entry della FAT per questo file)
limitazioni
- supporta file di massimo 4GB (32bit nel campo dimensione file delle directory)
- non implementa journaling
- non consente alcun meccanismo di controllo di accesso ai file/directory
- ha un limite alla dimensione delle partizioni: 2TB
NTFS
- sta per New Technology File System
- usa UNICODE per l’encoding dei nomi dei file (max 255 caratteri).
- i file sono definiti da un insieme di attributi (rappresentati come byte stream)
- supporta hard e soft link
- implementa journaling
regioni del volume

boot sector
Basata sull’equivalente FAT, ma con alcuni campi in posizioni diverse.
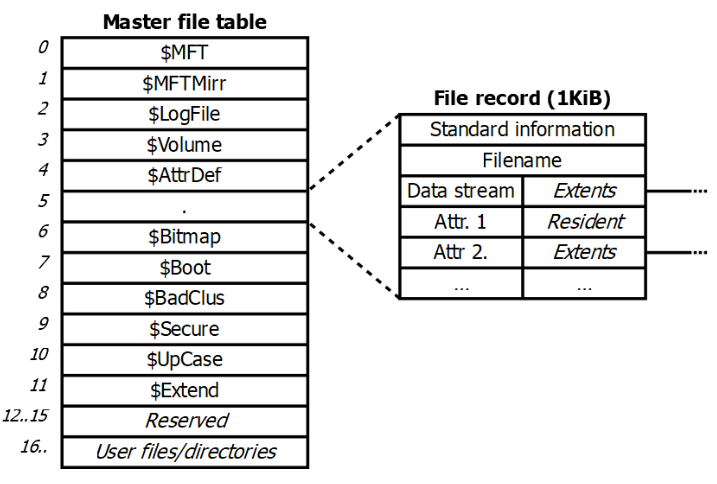
MFT: Master File Table
È la principale struttura dati del file system (ed è unica per ciascun volume, differentemente dal FAT). È implementata come un file: è composta da una sequenza lineare di record da 1 a 4KB.
- ogni record descrive un file, identificato da un puntatore da 48bit (i rimanenti 16 bit sono usati come numero di sequenza)
record
Ogni record contiene una lista attributo-valore (l’attributo è un intero, e il valore è una sequenza di byte).
- anche il contenuto di un file è un attributo (
$DATA)
Il valore dell’attributo può essere incluso direttamente nel record (attributo residente) o essere un puntatore ad un record remoto (attributo non residente).
record
I primi 27 record sono riservati per i metadati del file system:
- record 0 ⟶ descrive l’MFT stesso (tutti i file nel volume)
- record 1 ⟶ contiene una copia non residente dei primi record dell’MFT
- record 2 ⟶ contiene le informazioni di journaling (metadata-only)
- record 3 ⟶ contiene le informazioni sul volume (id, label, versione FS, ecc.)
- record 4 ⟶ tabella degli attributi usati nell’MFT
- record 5 ⟶ directory principale del volume - contiene i puntatori ai record della MFT che rappresentano file e directory nella root del volume
- record 6 ⟶ definisce la lista dei blocchi liberi usando una bitmap
Dal record 28 in poi ci sono i descrittori dei file normali.
files
la struttura NTFS cerca sempre di assegnare ad un file sequenze contigue di blocchi
- per i file piccoli, i dati sono salvati direttamente nell’MFT, mentre per i file grandi il valore dell’attributo indica la sequenza ordinata dei blocchi sul disco dove risiede il file
record base
Per ogni file, esiste un record base nell’MFT.
- le zone non usate da un file sono settate a
0 - il sistema mantiene una lista dei blocchi a zero
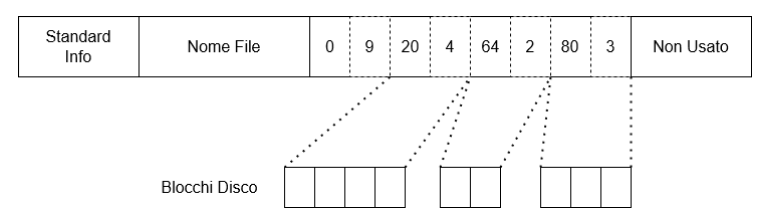
In questo esempio, il file è memorizzato in 9 cluster su 3 diverse porzioni di memoria contigue. Si nota come un descrittore (record) singolo sia sufficiente per l’intera run (file).
Questa rappresentazione consente di descrivere file di dimensione potenzialmente illimitata: dipende tutto dalla contiguità dei blocchi.
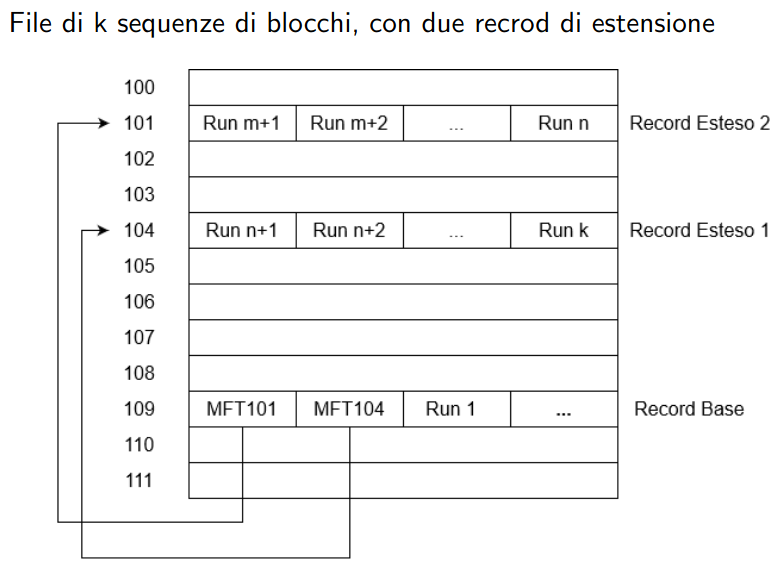
record con estensioni
File di larghe dimensioni possono necessitare di più record. NTFS usa una tecnica simile agli i-node:
- il record base è un puntatore a N record secondari
- eventuale spazio rimanente nel record base contiene le prime sequenze del file
Se i record estesi non rientrano in MFT per mancanza di spazio, vengono trattati come attributo non residente e quindi salvati in un file dedicato, con un apposito record nell’MFT.