Il World Wide Web (WWW) è un’applicazione internet nata dalla necessità di scambio e condivisione di ingormazioni tra ricercatori universitari di varie nazioni.
opera su richiesta (on demand)
è facile rendere disponibili le informazioni
hyperlinks e motori di ricerca permettono di navigare su molti siti
Il World Wide Web è formato da:
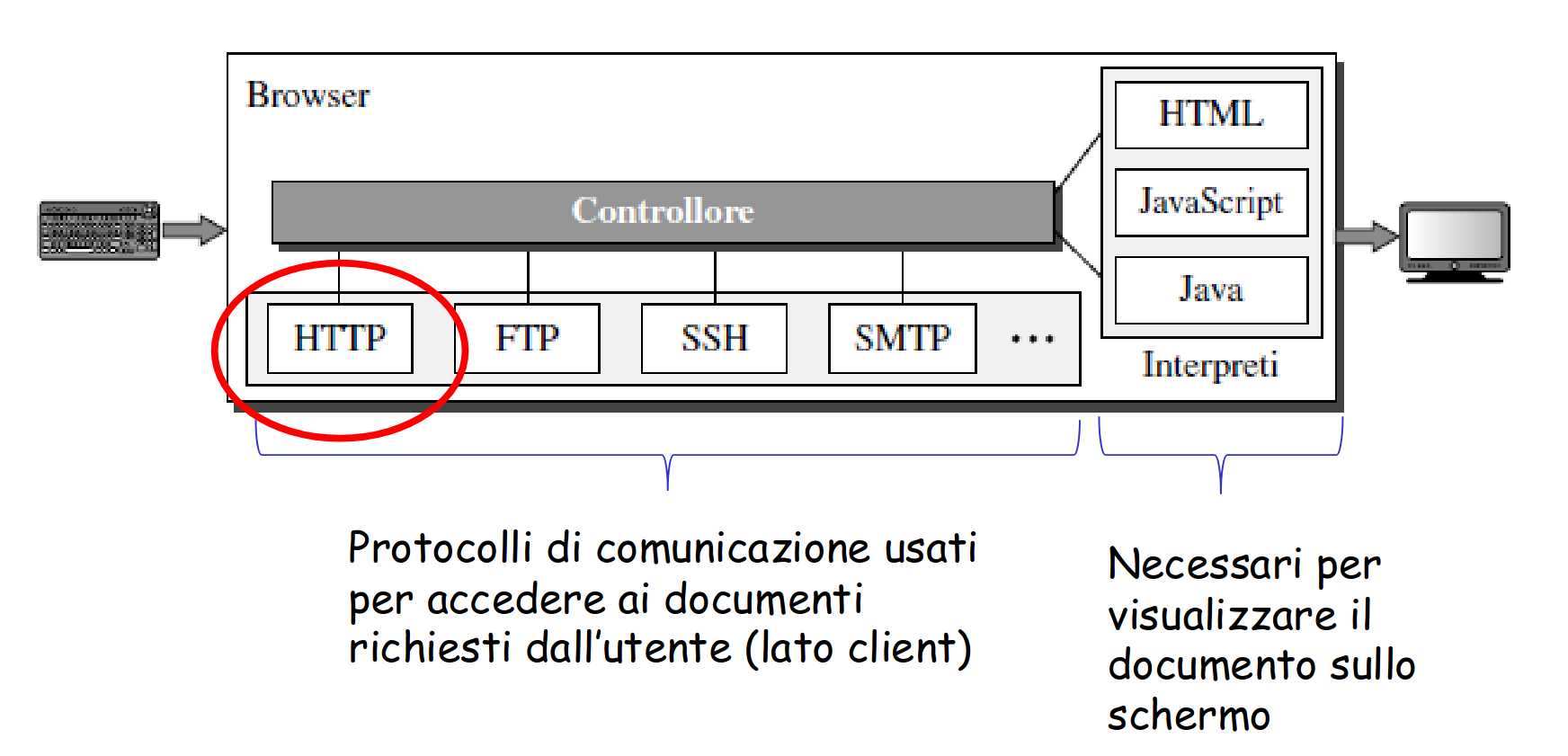
Web client (es. browser) ⟶ interfaccia con l’utente
Web server
HTML ⟶ linguaggio per pagine web
HTTP ⟶ protocollo per la comunicazione tra client e server web
architettura generale di un browser
URL
Per accedere a e visualizzare una pagina, si usa l’URL (Uniform Resource Locator).
Esso è composto da 3 parti:
il protocollo
il nome della macchina in cui è situata la pagina
il percorso del file (localmente alla macchina)
(è possibile specificare una porta all’interno dell’URL)
protocol://host/path
protocol://host:porta/path # con specifica porta
documenti web
Esistono tre tipi di documenti web:
documenti statici ⟶ contenuti predeterminati memorizzati sul server
documenti dinamici ⟶ creati dal web server alla ricezione della richiesta
documenti attivi ⟶ contengono script o programmi che verranno eseguiti nel browser (lato client)
HTTP
HTTP (HyperText Transfer Protocol) è un protocollo a livello applicazione del Web.
modello client/server
HTTP segue il modello client/server:
client ⟶ il browser richiede, riceve e visualizza gli oggetti del web
server ⟶ il server web invia oggetti in risposta ad una richiesta
HTTP definisce in che modo i client web richiedono le pagine ai server web e come questi le traferiscono ai client
Dal lato client:
il browser determina l’URL ed estrae host e filename
esegue connessione TCP alla porta 80 dell’host indicato nell’URL
invia una richiesta per il file
ricve il file dal server
chiude la connessione
visualizza il file
Il server:
accetta una connessione TCP da un client
riceve il nome del file richiesto
recupera il file dal disco
invia il file al client
rilascia la connessione
Tempo di risposta
Round Trip Time
Il Round Trip Time è il tempo impiegato da un piccolo pacchetto per andare dal client al server e ritornare al client.
include ritardi di propagazione, di accodamento e di elaborazione
Il tempo di risposta è formato da:
un RTT per inizializzare la connessione TCP
un RTT per la richiesta HTTP e i primi byte della risposta HTTP
tempo di trasmissione del file
ovvero da 2 RTT + tempo di trasmissione.
connessioni HTTP
Esistono due tipi di connessioni HTTP:
connessioni non persistenti:
un solo oggetto viene trasmesso su una connessione TCP
ciascuna coppia richiesta/risposta viene inviata su una connessione TCP separata
prima di inviare una richiesta al server è necessario stabilire una connessione
connessioni persistenti (modalità di default):
più oggetti possono essere trasmessi su una singola connessione TCP tra client e server
la connessione viene chiusa quando rimane inattiva per un lasso di tempo configurabile (timeout)
connessioni persistenti vs non persistenti
Le connessioni non persistenti non sono vantaggiose perché:
richiedono 2 RTT per oggetto
hanno un overhead per il sistema operativo per ogni connessione TCP
i browser aprono spesso connessioni TCP parallele per caricare gli oggetti
Le connessioni persistenti invece richiedono un solo RTT di connessione che vale per tutti gli oggetti (+ un RTT per ogni oggetto ricevuto dal server)
esempio: connessioni non persistenti
Supponiamo che l’utente immette l’URL www.someSchool.edu/someDepartment/home.index, che contiene testo e riferimenti a 10 immagini jpeg
il processo client HTTP inizializza una connessione TCP con il processo server HTTP a www.someSchool.edu sulla porta 80
il server HTTP all’host www.someSchool.edu in attesa di una connessione TCP alla porta 80 “accetta” la connessione e avvisa il client
il client HTTP trasmette un messaggio di richiesta (con l’URL) nella socket della connessione TCP. Il messaggio indica che il client vuole l’oggetto someDepartment/home.index
il server HTTP riceve il messaggio di richiesta, crea il messaggio di risposta che contiene l’oggetto richiesto e invia il messaggio nella sua socket
il server HTTP chiude la connessione TCP
il client HTTP riceve il messaggio di risposta che contiene il file html e visualizza il documento html. Esamina il file html, trova i riferimenti a 10 oggetti jpeg
i passi 1-5 sono ripetuti per ciascuno dei 10 oggetti jpeg
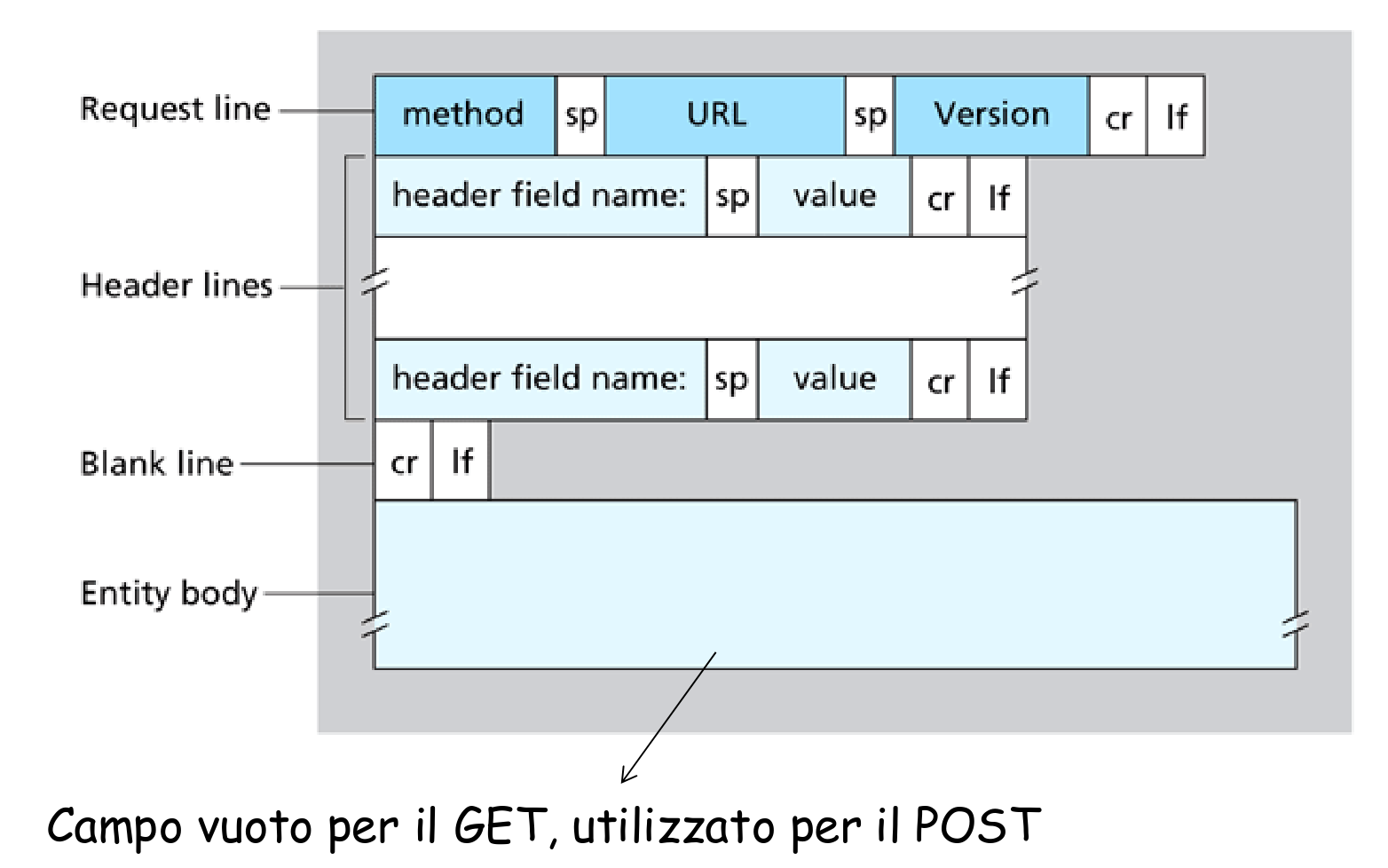
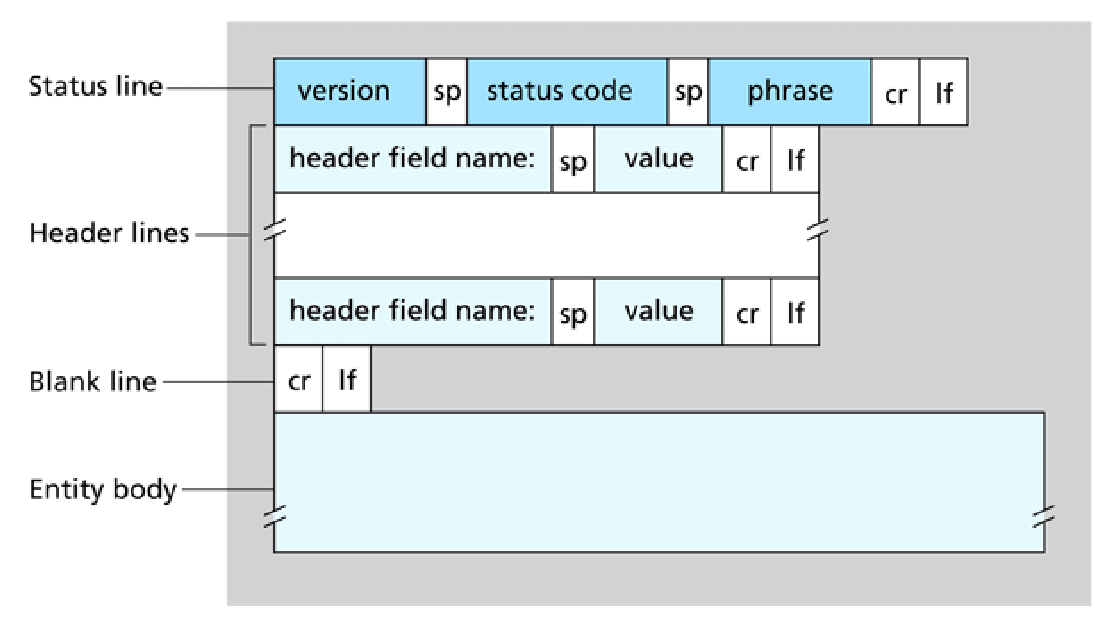
formato dei messaggi
richiesta HTTP
formato
esempio di richiesta HTTP:
GET /somedir/page.html HTTP/1.1 // request lineHost: www.someschool.edu // header lines vConnection: close User-agent: Mozilla/4.0 Accept-Language:fr (carriage return e line feed extra) // blank line
metodi:
metodo di richiesta
descrizione
GET
usato quando il client vuole scaricare il documento specificato dall’URL da un server. Il server risponde con il documento richiesto nel corpo del messaggio di risposta
HEAD
usato quando il client non vuole scaricare il documento, ma solo alcune informazioni sul documento (es: data dell’ultima modifica). Nella risposta, il server inserisce solo degli header informativi
POST
usato per fornire input al server (es: contenuto dei campi di un form). l’input viene inserito nel corpo dell’entità
PUT
utilizzato per memorizzare un documento nel server. il documento viene fornito nel corpo del messaggo, e la posizione di memorizzazione nell’URL
è posibile inviare info al server (oltre che con POST) anche attraverso una richiesta GET
utilizzando & negli URL
www.somesite.com/animalsearch?monkeys&banana
intestazioni:
intestazione
descrizione
User-Agent
indica il programma client utilizzato
Accept
indica il formato dei contenuti che il client è in grado di accettare
Accept-charset
famiglia di caratteri che il client è in grado di gestire
Accept-encoding
schema di codifica supportato dal client
Accept-language
linguaggio preferito dal client
Authorization
indica le credenziali possedute dal client
Connection
close - la connessione verrà chiusa dopo la transazione / keep-alive - la connessione rimarrà aperta
Host
host e numero di porta del client
Date
data e ora del messaggio
Upgrade
specifica il protocollo di comunicazione preferito
Cookie
comunica il cookie al server
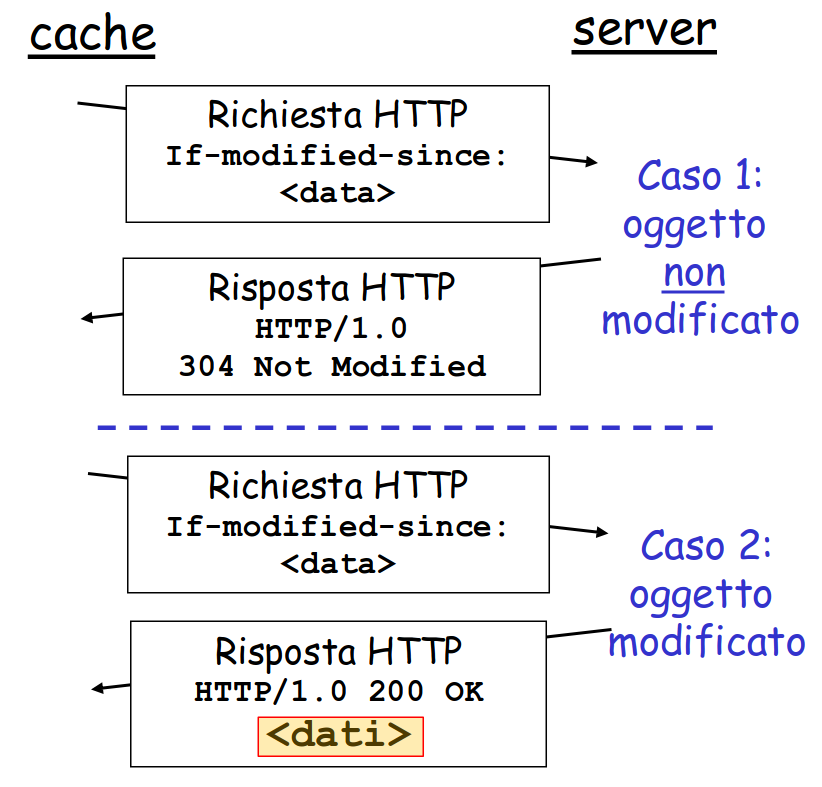
If-Modified-Since
invia il documento solo se è più recente della data specificata
risposta HTTP
formato risposta
esempio di risposta HTTP:
HTTP/1.1 200 OK //riga di statoConnection closeDate: Thu, 06 Aug 1998 12:00:15 GMTServer: Apache/1.3.0 (Unix)Last-Modified: Mon, 22 Jun 1998 ...Content-Length: 6821 //in byteContent-Type: text/html(carriage return e line feed extra)dati dati dati dati dati // ad esempio, file HTML
codici di risposta
Si trovano nella prima riga del messaggio di risposta server-client.
code
meaning
examples
1xx
information
100 = server agrees to handle client’s request
2xx
success
200 = request succeeded; 204 = no content present
3xx
redirection
301 = page moved; 304 = cached page still valid
4xx
client error
403 = forbidden page; 404 = page not found
5xx
server error
500 = internal server error; 503 = try again later
intestazioni nella risposta
intestazione
descrizione
Date
data corrente
Upgrade
specifica il protocollo preferito
Server
indica il programma server utilizzato
Set-Cookie
il server richiede al client di memorizzare un cookie
Content-Encoding
specifica lo schema di codifca
Content-Language
specifica la lingua del documento
Content-Length
indica la lunghezza del documento
Content-Type
specifica la tipologia di contenuto
Location
chiede al client di inviare la richiesta ad un altro sito
Last-Modified
fornisce data e ora di ultima modifca del documento
esempi di richiesta-risposta
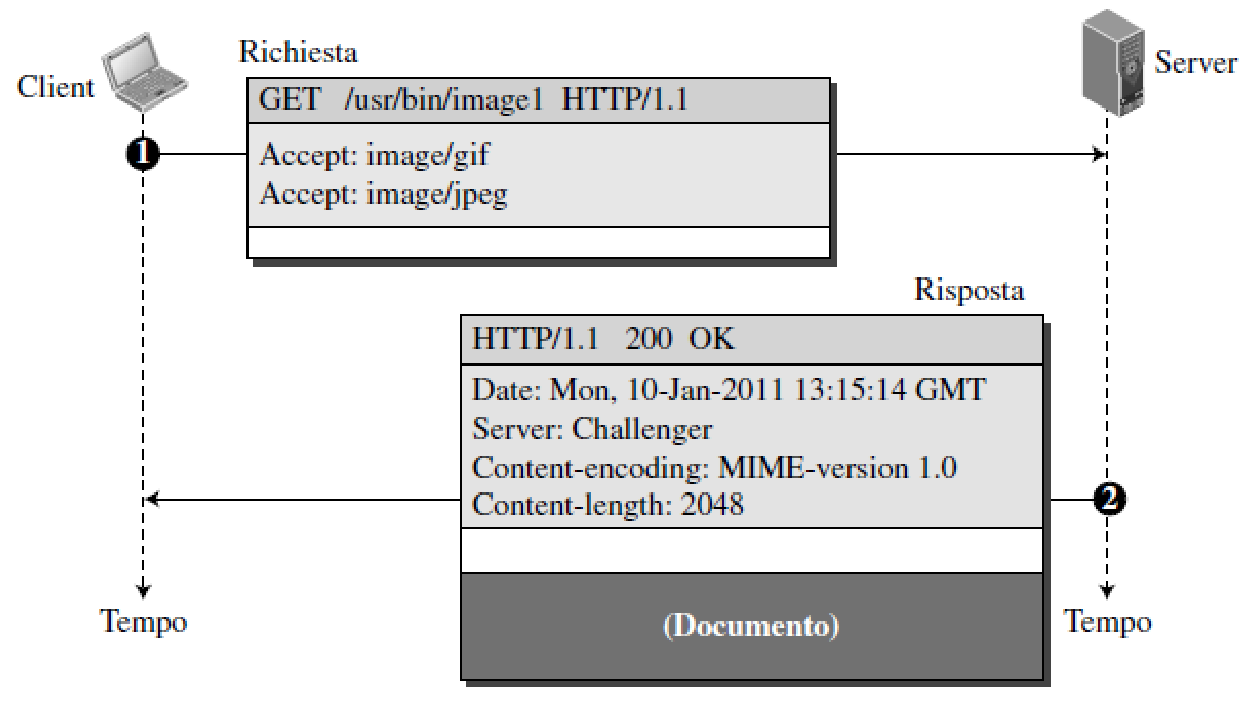
richiesta GET
La riga di richiesta contiene il metodo (GET), l’URL e la versione (1.1) del protocollo HTTP. L’intestazione è costituita da due righe in cui si specifica che il client accetta immagini nei formati GIF e JPEG. Il messaggio di richiesta non ha corpo.
Il messaggio di risposta contiene la riga di stato e quattro righe di intestazione che contengono la data, il server, il metodo di codifica del contenuto (la versione MIME, argomento che verrà descritto nel paragrafo dedicato alla posta elettronica) e la lunghezza del documento.
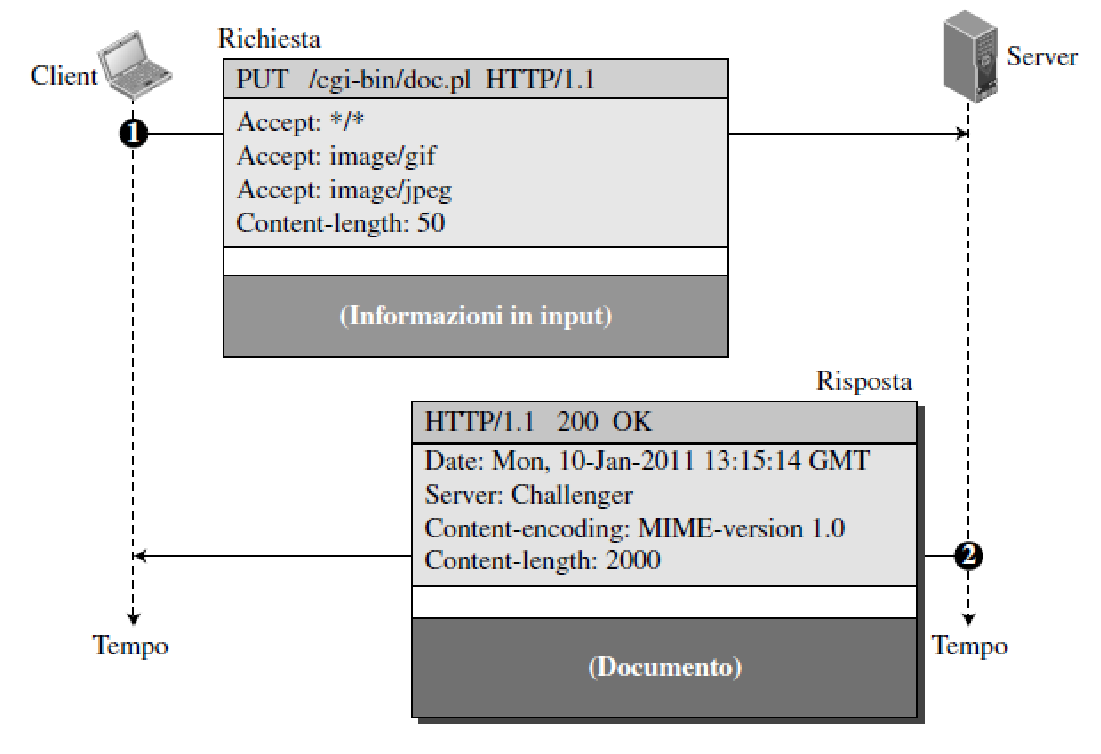
richiesta PUT
(il cliente spedisce al server una pagina web da pubblicare)
La riga di richiesta contiene il metodo (PUT), l’URL e la versione (1.1) del protocollo HTTP. L’intestazione è costituita da quattro righe d’intestazione. Il corpo del messaggio di richiesta contiene la pagina Web inviata.
Il messaggio di risposta contiene la riga di stato e quattro righe di intestazione.
Il documento creato, un documento CGI, è incluso nel corpo del messaggio di risposta.
cookie
HTTP è un protocollo “senza stato” (stateless): una volta servito il client, il server sen ne dimentica e non mantiene informazioni sulle richieste fatte.
I protocolli che mantengono lo stato sono complessi: la storia passata deve essere memorizzata, e, se il server e/o client si bloccano, ci potrebbero essere incongruenze tra gli stati che devono essere riconciliate.
ci sono però molti casi in cui il server ha bisogno di ricordarsi degli utenti (per esempio per la profilazione)
non si possono mantenere gli indirizzi IP in quanto molti utenti possono lavorare su computer condivisi, e molti ISP assegnano lo stesso IP a pacchetti di utenti diversi
La soluzione al problema sono i cookie (RFC 6265), che consentono ai siti di tenere traccia degli utenti.
i cookie permettono di creare una sessione di richieste e risposte HTTP che sia stateful (un contesto più largo rispetto alla singola richiesta/risposta)
sessioni
Ci possono essere diversi tipi di sessione in base al tipo di informazioni scambiate e alla natura del sito.
Le caratteristiche generali di una sessione sono:
ha un inizio e una fine
ha un tempo di vita relativamente corto
sia il client che il server possono chiudere la sessione
la sessione è implicita nello scambio di informazione dello stato
per sessione non si intende una connessione persistente, ma una sessione logica composta da richieste e risposte HTTP (che può essere creata su connessioni persistenti e non persistenti)
interazione utente-server
Le componenti delle interazioni utente-server, per quanto riguarda i cookie, sono:
una riga di intestazione nel messaggio di risposta HTTP
una riga di intestazione nel messaggio di richiesta HTTP
un file cookie mantenuto sul sistema terminale dell’utente e gestito dal browser dell’utente
un database sul server
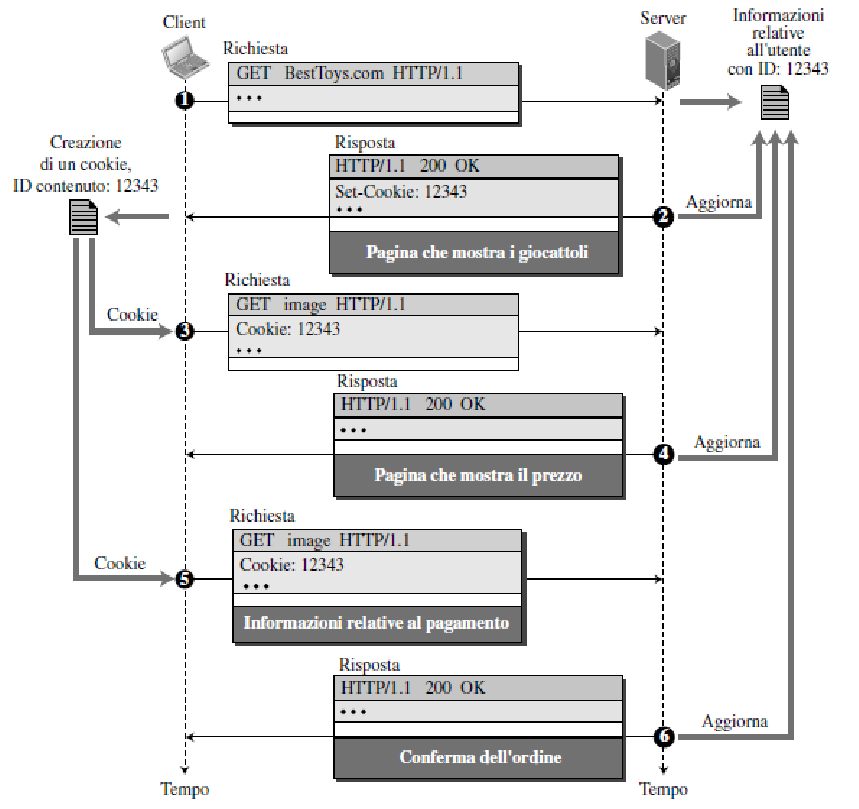
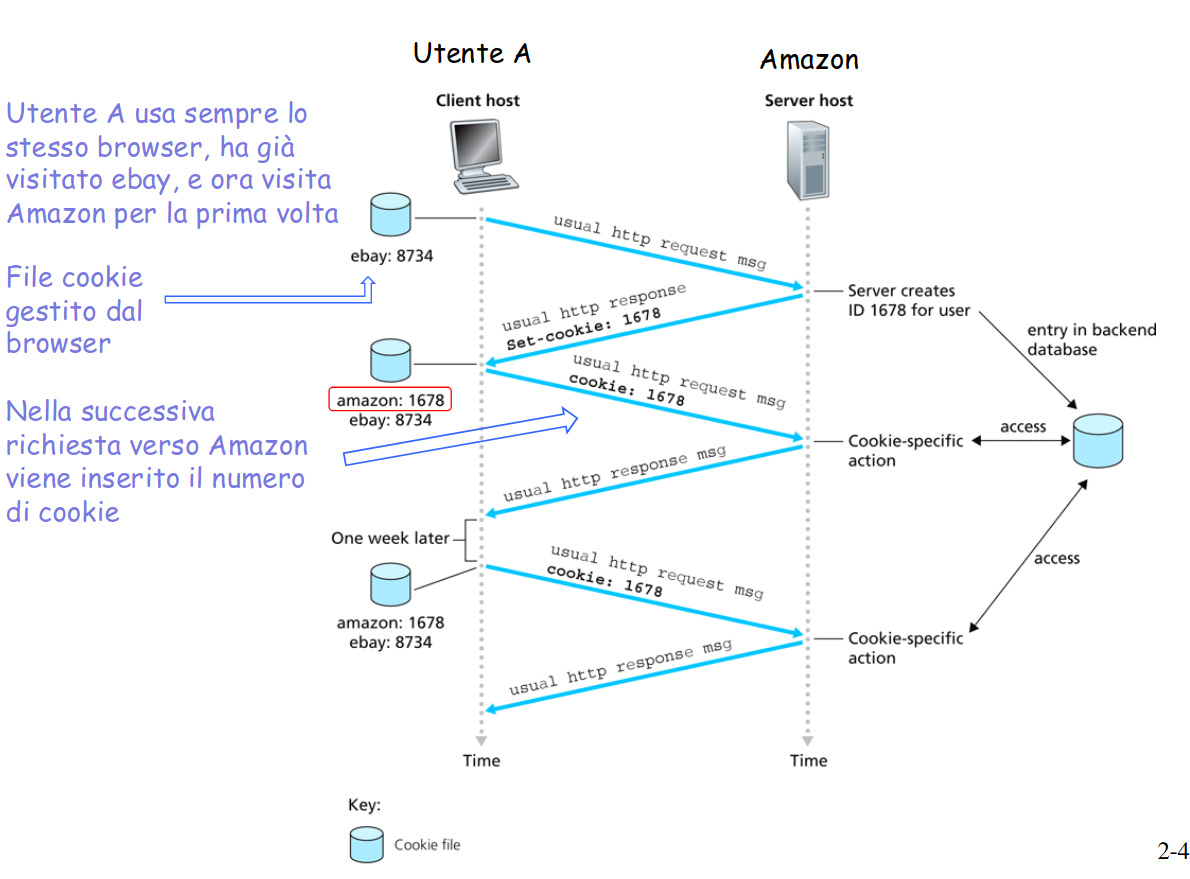
esempio
L’utente A accede sempre a Internet dallo stesso PC (non necessariamente con lo stesso IP)
Visita per la prima volta un particolare sito di commercio elettronico
Quando la richiesta HTTP iniziale giunge al sito, il sito crea un identificativo unico (ID) e una entry nel database per ID
L’utente A invierà ogni futura richiesta inserendo l’ID nella richiesta
esempio di utilizzo cookie
nel dettaglio
Il server mantiene tutte le informazioni sul client in un file e gli assegna un identificatore (cookie), che viene fornito al client. Il cookie inviato al client è un identificatore di sessione (SID), sotto forma di una stringa di numeri (per evitare che sia utilizzato da utenti “maligni”)
esempio
== Server -> User Agent ==
Set-Cookie: SID=31d4d96e407aad42
Ogni volta che il client manda una richiesta al server, fornisce il suo identificatore: il browser consulta il file cookie, estrae il numero di cookie per il sito che si vuole visitare e lo inserisce nella richiesta HTTP.
Il server, mediante il cookie fornito dal client, accede al relativo file e fornisce risposte personalizzate.
esempio
I file cookie possono contenere autorizzazioni, carta per acquisti, preferenze dell’utente, stato della sessione dell’utente.
Essi mantengono anche lo stato del mittente e del ricevente per più transazioni (gli stati saranno poi trasportati dai messaggi HTTP).
durata di un cookie
Il server chiude una sessione inviando al client un’intestazione Set-Cookie nel messaggio con Max-Age=0.
attributo Max-Age
L’attributo Max-Age definisce il tempo di vita in secondi di un cookie. Dopo delta secondi, il client dovrebbe rimuovere il cookie.
altra soluzione per mantenere lo stato
Un altro metodo per mantenere lo stato (e quindi creare una sessione) è:
attraverso il metodo POST, inserendo le informazioni sullo stato della sessione nell’URL
vantaggi e svantaggi
pros:
facile da implementare
non richiede l’introduzione di particolari funzionalità sul server
cons:
può generare lo scambio di grandi quantità di dati
le risorse del server devono essere re-inizializzate ad ogni richiesta
web caching
Il caching è definito come l’accumulo delle pagine per un utilizzo successivo. L’obiettivo è migliorare le prestazioni dell’applicazione web.
Un modo semplice sarebbe quello di salvare le pagine richieste per riutilizzarle in seguito senza doverle richiedere al server.
tecnica efficiente con pagine che vengono visitate molto spesso
Il caching può essere eseguito da:
browser
proxy
browser caching
Il browser può mantenere una cache (personalizzabile dall’utente) delle pagine visitate.
Esistono vari meccanismi per la gestione della cache locale:
l’utente può impostare il numero di giorni dopo i quali i contenuti della cache vengono cancellati
la pagina può essere mantenuta in cache in base alla sua ultima modifica
si possono utilizzare informazioni nei campi di intestazione dei messaggi per gestire la cache
non sempre rispettato dai browser
es: campo expires che specifica la scadenza dopo la quale la pagina è considerata obsoleta
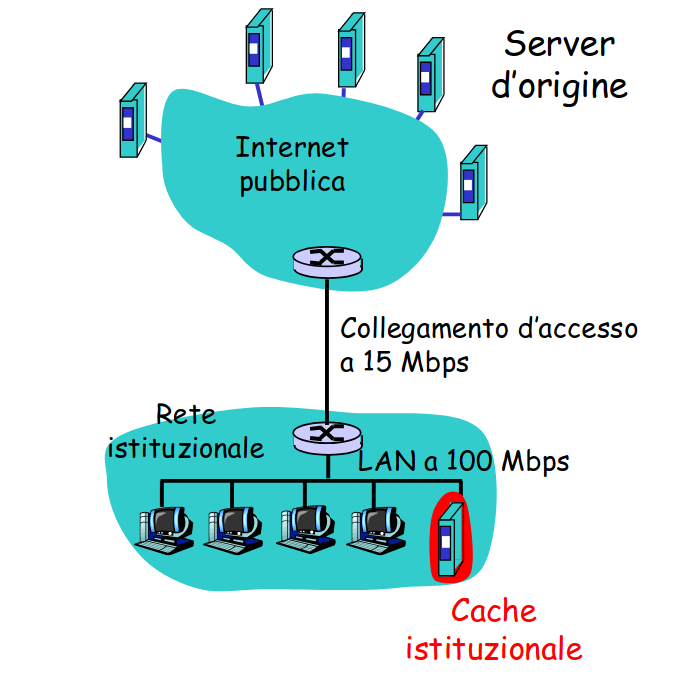
caching con server proxy
L’obiettivo è quello di soddisfare la richiesta del client senza coinvolgere il server d’origine.
Si introduce un server proxy (tipicamente installato da un ISP) che ha una memoria per mantenere copie delle pagine visitate, e il browser può essere configurato per tramettere tutte le richieste HTTP alla cache (se l’oggetto è in cache, viene fornito - altrimenti, la cache lo richiede al server d’origine e lo inoltra al client).
La cache opera quindi sia come client che come server.
perché il caching web?
riduce i tempi di risposta alle richieste dei clent
riduce il traffico sul collegamento di accesso a internet
consente ai provider meno efficienti di fornire dati con efficacia
esempio in assenza di cache
stimiamo il tempo di risposta - valutiamo l’intensità di traffico:
intensitaˋ di traffico su LAN= RL⋅a=100Mbps15req/s⋅1mb/req=15%
“‘ su collegamento d’accesso=RL⋅a=15Mbps15req/s⋅1Mb=100%
ritardo totale = ritardo di Internet + ritardo di accesso + ritardo LAN
ritardo totale = 2sec + minuti + millisecondi
Una soluzione potrebbe essere aumentare l’ampiezza di banda del collegamento d’accesso a 100mbps. In questo caso, l’utilizzo sul collegamento d’accesso sarebbe del 15% , e il ritardo totale sarebbe più che gestibile. Ciò non è però sempre attuabile, e aggiornare il collegamento risulta costoso.
esempio in presenza di cache
supponiamo un hit rate di 0,4:
il 40% delle richieste sarà soddisfatto quasi immediatamente (circa 10ms) (anche se la cache proxy deve comunque inviare richieste al server per verificare che la pagina non sia obsoleta, i messaggi ricevuti saranno più piccoli, quindi avrà un carico minore e prestazioni migliori)
il 60% delle richieste sarà soddisfatto dal server d’origine
l’utilizzo del collegamento d’accesso si è ridotto al 60%, determinando ritardi trascurabili (circa 10ms)
ritardo totale medio = ritardo di Internet + ritardo di accesso + ritardo della LAN ≃1,2sec
inserimento di un oggetto in cache
I passi per l’inserimento sono:
il client invia un messaggio di richiesta HTTP alla cache
stimiamo il tempo di risposta - valutiamo l’intensità di traffico: