Il timestamp identifica una transazione. È assegnato alla transazione al suo inizio dallo scheduler. Può essere:
- il valore di un contatore
- l’ora di inizio di una transazione
Il timestamp è crescente: se il timestamp di T1 è minore di quello di T2, la transazione T1 è iniziata prima di T2 (quindi, se fossero eseguite in modo seriale, T1 verrebbe eseguita prima).
serializzabilità
Uno schedule è serializzabile se è equivalente allo schedule seriale in cui le transazioni compaiono in base al loro timestamp. Quindi, se per ciascun item acceduto da più di una transazione, l’ordine con cui le transazioni accedono all’item è quello imposto dai timestamp.
esempio 1
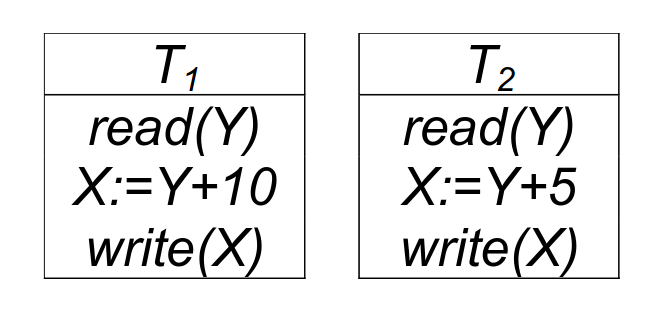
consideriamo le due transazioni T1 e T2 con i loro timestamp e .
quindi, uno schedule è serializzabile se è equivalente allo schedule seriale .
Per esempio, questo schedule non è serializzabile, perché legge prima che l’abbia scritto:



esempio 2
Consideriamo invece queste due transazioni con timestamp e :
Uno schedule serializzabile deve essere equivalente allo schedule seriale
quindi, questo schedule è serializzabile solo se non viene eseguita la scrittura di da parte di :


read e write timestamp
A ciascun item vengono assegnati due timestamp:
- read timestamp
read_TS(X)⇒ il più grande tra tutti i timestamp di transazioni che hanno letto con successo - write timestamp
write_TS(X)⇒ il più grande tra tutti i timestamp di transazioni che hanno scritto con successo
il "più grande"
il “più grande timestamp” NON è il timestamp dell’ultima transazione che l’ha letto/scritto - è il timestamp della transazione più “giovane” tra quelle che l’hanno letto/scritto
tornando all'esempio 2

controllo della serializzabilità
Ogni volta che una transazione cerca di eseguire un read(X) o un write(X), occorre confrontare il timestamp con il read timestamp e il write timestamp di per assicurarsi che sia rispettato l’ordine.
algoritmo
scrittura:
T cerca di eseguire una write(X).
- se (ovvero se una transazione più giovane l’ha già letta) viene rolled back
- se , invece di fare un rollback, semplicemente non si effettua l’operazione di scrittura (ignorando l’atomicità)
- (vuol dire che una transazione più giovane ha già scritto)
- se nessuna delle condizioni precedenti è soddisfatta, allora:
- si esegue
write(X)e si sovrascrive il write timestamp di :
- si esegue
lettura:
T cerca di eseguire una read(X).
- se , viene rolled back
- se , allora
- si esegue
read(X)e, se , si sovrascrive:
- si esegue
esempio 1
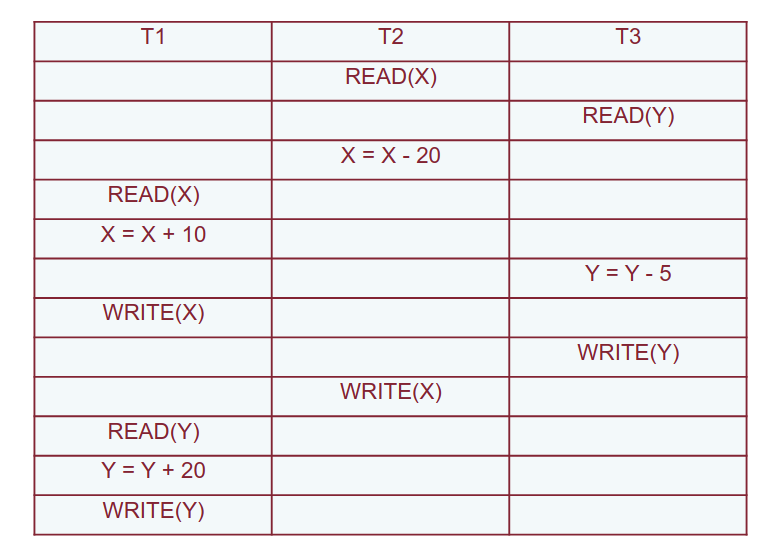
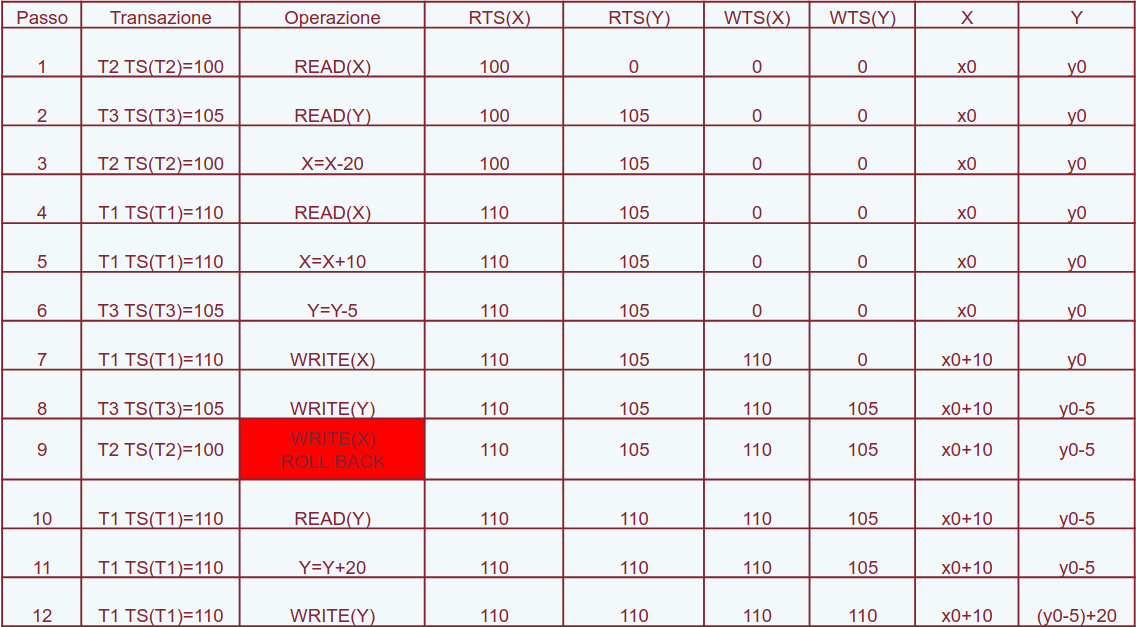
Analizziamo questo schedule:
Le transazioni hanno i seguenti timestamp: . Assumiamo che all’inizio tutti i read e write timestamp siano azzerati.
Al passo 9 la transazione verrà abortita - cercherà di scrivere , ma il suo timestamp sarà minore del read timestamp di (dato da al passo 4): questo significa che ha letto il valore errato di : quello non ancora modificato da . Per questo bisogna eseguire il rollback.
osservazioni
Notiamo che lo schedule delle transazioni superstiti è equivalente allo schedule seriale delle transazioni eseguite in ordine di arrivo.
cosa provoca il rollback di una transazione?
se la transazione voleva leggere ⇒ trovare un’altra transazione più giovane che ha già scritto i dati
se la transazione voleva scrivere ⇒ trovare un’altra transazione più giovane che ha già letto i dati
ricorda
Se invece una transazione vuole scrivere e trova una transazione più giovane che ha già scritto i dati, non è necessario il rollback (basta non eseguire la scrittura).
ignorare l'atomicità
Perché possiamo ignorare l’atomicità saltando l’operazione di scrittura di una transazione ? L’atomicità serve a garantire la coerenza in una base di dati. Le transazioni che potrebbero trovare una situazione incoerente (a causa della non-scrittura) sono quelle che avrebbero dovuto leggere i dati scritti da (e si sarebbero ritrovate invece i dati di una transazione più giovane )
- ma non esiste una transazione arrivata dopo ma prima di (con ) che ha letto il dato: altrimenti, sarebbe stata rolled-back (avrebbe cercato di scrivere quando una transazione più giovane aveva già letto).
- se poi dovesse arrivare che vuole leggere il valore di , questa sarebbe rolled back per il primo passo dell’algoritmo di controllo della lettura (troverebbe maggiore del proprio perché scritto da )
perché non il timestamp dell'ultima transazione?
Prendiamo come esempio questo caso, con i timestamp . Se il write timestamp e il read timestamp fossero quelli dell’ultima transazione anziché della più giovane, scriverebbe il valore di un item () già letto da , quando avrebbe dovuto leggere il valore di .

domande orale
possibili domande orale
- come funziona il timestamp?
- quando una transazione è serializzabile nel caso dei timestamp?
- algoritmo di controllo della serializzabilità
- perché si può ignorare l’atomicità nel caso del
write?