static ⟶ the iterations can be assigned to the threads before the loop is executed
dynamic or guided ⟶ the iterations are assigned to the threads while the loop is executing
auto ⟶ the compiler and/or the runtime system determine the schedule
and the chunksize is a positive integer.
default and cyclic partitioning for loops
sum = 0.0for (i = 0; i <= n; i++)
If we were to parallelise this for, how would iterations be assigned to threads?
Two different ways to assign them are:
default partitioning:
Thread
Iterations
0
0,1,2,…,n/t−1
1
n/t,n/t+1,…,2n/t
⋮
⋮
t−1
n(t−1)/t,…,n−1
implemented in OpenMP like so:
sum = 0.0;#pragma omp parallel for num_threads(thread_count) \ reduction(+:sum)for (i = 0; i <= n; i++) sum += f(i);
cyclic partitioning:
Thread
Iterations
0
0,n/t,2n/t,…
1
1,n/t+1,2n/t+1,…
⋮
⋮
t−1
t−1,n/t+t−1,2n/t+t−1,…
Implemented like so:
sum = 0.0;#pragma omp parallel for num_threads(thread_count) \ reduction(+:sum) schedule(static,1)for (i = 0; i <= n; i++) sum += f(i);
static schedule type
(iterations can be assigned to the threads before the loop is executed)
static schedule type
twelve iterations, three threads
schedule(static, 1)
thread 0: 0,3,6,9
thread 1: 1,4,7,10
thread 2: 2,5,8,11
schedule(static, 2)
thread 0: 0,1,6,7
thread 1: 2,3,8,9
thread 2: 4,5,10,11
schedule(static, 4)
thread 0: 0,1,2,3
thread 1: 4,5,6,7
thread 2: 8,9,10,11
dynamic schedule type
(Iterations are assigned to the threads while the loop is executing)
The iterations are also broken up into chunks of chunksize consecutive iterations.
until all iterations are complete, each thread executes a chunk, and, when done, requests another one from the run-time system
chunksize can be omitted, and it defaults to 1
This type of scheduling has better load balancing, but higher overhead (that can still be tuned through chunksize).
guided schedule type
(iterations are assigned while the loop is executed)
This schedule type also uses chunk - however, as chunks are completed, the size of new chunks decreases.
chunks have size = num_iterations/num_threads, where num_iterations = number of unassigned iterations
the size decreases up to chunksize (“lower bound”) - default is 1
exception: the very last chunk can be smaller than chunksize
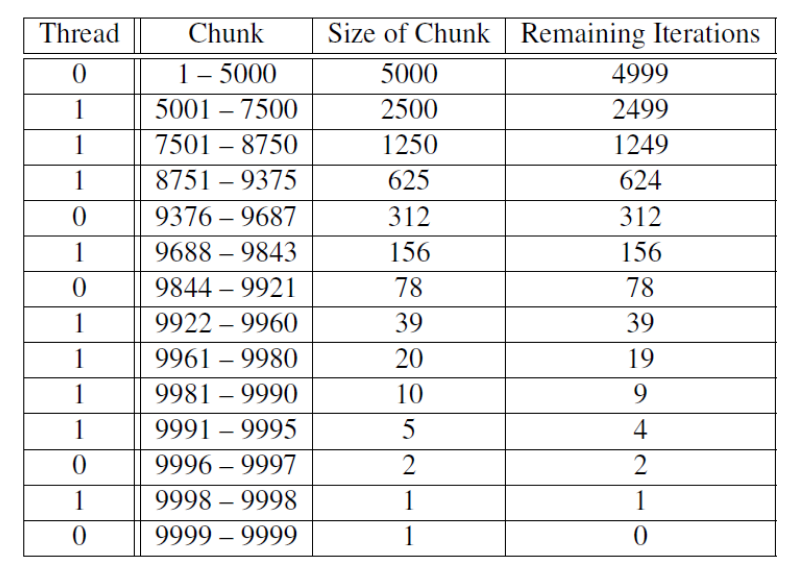
trapezoidal rule iterations 1–9999 using a guided schedule with two threads.
runtime schedule type
(schedule is determined at run-time)
The system uses the OMP_SCHEDULE environment variable to determine how to schedule loops at run-time.
it can take on any of the values that can be sed for a static, dynamic or guided schedule
usage
The value can be specified as an env variable:
$ export OMP_SCHEDULE="static,1"
or through a function
omp_set_schedule(omp_sched_t kind, int chunksize);
selecting a schedule option
static ⟶ if iterations are homogeneous (in execution time)
dynamic/guided ⟶ if execution cost varies (ex due to input data, conditional logic or cache effects)
If in doubt, # pragma omp parallel for schedule(runtime) is often a good choice, as it allows the programmer to set the schedule type after compilation via env var (not hardcoding it), making it more flexible (and good for experimenting and choosing the correct schedule).
(the best practice is to use performance tools to measure the runtime for different schedule options on your target hardware)
Synchronization constructs
master, single
master and single both force the execution of the following block by a single thread.
single implies a barrier on exit from the block
master guarantees that the block is executed by the master thread
master example
int examined = 0;int prevReported = 0;#pragma omp for shared( examined, prevReported )for( int i = 0; i < N; i++ ){ // some processing // update the counter #pragma omp atomic examined++; // use the master to output an update every 1000 newly // finished iterations #pragma omp omp master { int temp = examined; if( temp - prevReported >= 1000) { prevReported = temp; printf("Examined %.2f%%\n", temp * 1.0 / N ); } }}
barrier
barrier blocks threads until all team threads reach that point.
example
int main ( ){ int a[5], i; #pragma omp parallel { // Perform some computation. #pragma omp omp for for (i = 0; i < 5; i++) a[i] = i*i; // Print intermediate results. #pragma omp omp master for (i = 0; i < 5; i++) printf("a[%d] = %d\n", i, a[i]); // Wait. #pragma omp omp barrier // Continue with the computation. #pragma omp omp for for (i = 0; i < 5; i++) a[i] += i; }}
section & sections
The sections construct is a non-iterative worksharing construct that contains a set of structured blocks that are to be distributed among and executed by the threads in a team.
(combines the parallel and sections directives)
Individual work items are contained in blocks decorated by section derivatives:
there is an implicit barrier at the end of a sections construct, unless a nowait clause is specified
ordered
ordered is used inside a parallel for to ensure that a block (the iterations) will be executed in sequential order.
example
double data [ N ];#pragma omp parallel shared( data, N ){ #pragma omp for ordered schedule( static , 1 ) for(int i = 0; i < N; i++) { // process the data // print the results in order #pragma omp ordered cout << data[i]; }}