index
[ rilettura utile: gestione IO generale]
dispositivi di I/O
ci sono tre macrocategorie di IO:
- leggibili dall’utente
- leggibili dalla macchina - comunicazione con materiale elettronico (es. dischi, USB)
- di comunicazione (input: tastiera, mouse, output: scheda di rete)
Queste macrocategorie sono molto diverse tra di loro, il che causa problemi al sistema: bisogna gestirli tutti e pensare a come tener conto delle diversità.
funzionamento
Un dispositivo di input prevede di essere interrogato sul valore di una certa grandezza fisica al suo interno (es. codice Unicode di un tasto premuto) - un processo effettua una syscall read su un dispositivo per leggere un dato.
- al processo non interessa che tipo di macchina sia, ma solo il valore da leggere
Un dispositivo di output prevede di poter cambiare il valore di una certa grandezza fisica al suo interno (es. monitor - valore rgb dei pixel) - un processo effettua una syscall write per cambiare qualcosa.
- spesso l’effetto è direttamente visibile, alcune volte serve usare una funzionalità di lettura
Esistono quindi, al minimo, due syscall: read e write (che prendono in input, tra le varie cose, un identificativo del dispositivo). Al momento di una syscall, il Kernel si interpone tra processo utente e dispositivo fisico: comanda l’inizializzazione del trasferimento di informazioni, mette il processo in blocked e passa ad altro.
A trasferimento completato arriva l’interrupt (si termina l’operazione e il processo ritorna ready)
- ci possono essere dei problemi: es. un disco si è smagnetizzato
- potrebbe essere necessario fare anche altri trasferimenti, per esempio dalla RAM dedicata al DMA a quella del processo (se c’è il DMA di mezzo si complica - è il DMA a prendere i dati dalla zona utente e portarli nella zona I/O)
driver
La parte di Kernel che gestisce un particolare dispositivo I/O si chiama driver (è formata da una serie di moduli di sistema che implementano funzionalità specifiche in base al dispositivo).
differenze tra dispositivi I/O
i dispositivi I/O possono differire sotto molti aspetti:
- data rate (quanto velocemente si legge/scrive)
- applicazione
- ogni dispositivo I/O ha una diversa applicazione ed uso: i dischi sono usati per memorizzare file (e richiedono software per quello), ma anche per la memoria virtuale (per cui servono altri software e hardware)
- difficoltà nel controllo
- una tastiera o un mouse sono più banali, mentre una stampante è più articolata (per esempio a causa dei dischi magnetici), e un disco è tra le cose più complicate
- fortunatamente, molte cose sono controllate da hardware dedicato - la divisione dei compiti è (in ordine) tra:
- processo utente
- syscall del Sistema Operativo
- driver
- hardware (controller dei dispositivi)
- unità di trasferimento dati
- in stream di byte o caratteri (usati da memoria non secondaria, es. stampanti, schede audio…)
- in blocchi di byte di lunghezza fissa (usati per esempio dai dischi)
- rappresentazione dei dati
- i dati sono rappresentati secondo codifiche diverse su dispositivi diversi (es. ASCII vs UNICODE)
- condizioni di errore
- (la natura degli errori varia molto da dispositivo a dispositivo)
- es. diverse conseguenze: fatali (come leggere da un blocco rotto) o ignorabili (come scrivere su un blocco rotto - si scrive direttamente sul successivo)
organizzazione della funzione di I/O
ripasso diverse gestioni I/O
I/O programmato:
- l’azione su I/O viene eseguita dal modulo I/O e non dal processore, quindi il processore deve controllare costantemente lo stato dell’I/O fino a quando l’operazione non è completa (rimanendo bloccato)
I/O da interruzioni:
- il processore viene interrotto quando il modulo I/O è pronto a scambiare dati (il processore, una volta ricevuto un write, manda un comando al modulo dell’I/O e continua a svolgere le operazioni fino a quando l’interrupt handler non lo notifica del fatto che l’operazione è terminata)
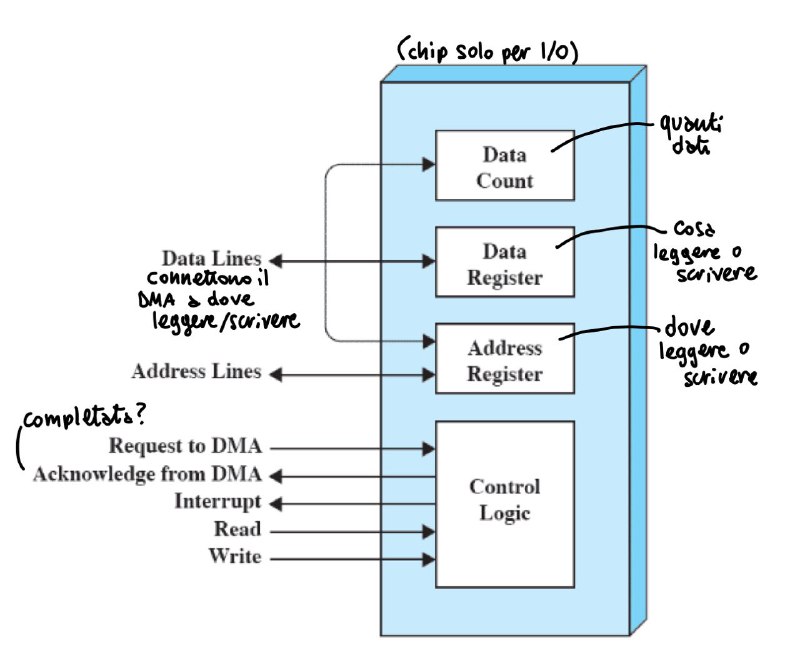
I/O con Direct Access Memory
- (le istruzioni richiedono di trasferire informazioni tra dispositivo e memoria) - la DMA trasferisce un blocco di dati dalla memoria, e un’interruzione viene mandata quando il trasferimento è completo
Ci sono sostanzialmente tre modi di gestire l’I/O:
| senza interruzioni | con interruzioni | |
|---|---|---|
| passando per la CPU | I/O programmato | I/O guidato dalle interruzioni |
| direttamente in memoria | DMA |
approfondimento: DMA
- il processore delega le operazioni di I/O al modulo DMA, che trasferisce i dati direttamente da o verso la memoria principale (evitando perdite di tempo)
- quando l’operazione è completata, il modulo DMA genera un interrrupt per il processore (tramite un dispositivo hardware)
evoluzione della funzione di I/O
in ordine cronologico, l’I/O si è evoluto così:
- il processore controlla il dispositivo periferico
- aggiunta di un modulo (controllore) di I/O direttamente sul dispositivo, che permette I/O programmato senza interrupt (il processore non si deve occupare di alcuni dettagli del dispositivo stesso)
- modulo o controllore di I/O con interrupt - migliora l’efficienza del processore, che non deve aspettare il completamento dell’operazione I/O
- DMA - i blocchi di dati viaggiano tra dispositivo e memoria, senza usare il processore (che fa qualcosa solo a inizio e fine operazione)
- il modulo di I/O diventa un processore separato general purpose (I/O channel) -il processore principale comanda a quello I/O di eseguire un certo programma di I/O in memoria principale
- processore per l’I/O con memoria dedicata (come una cache), usato per comunicazioni con terminali interattivi
Nelle architetture moderne, il chipset (un chip a parte che implementa le varie connessioni dati) implementa le funzioni di interfaccia I/O.
problemi nel progetto del sistema operativo
i Sistemi Operativi si pongono degli obiettivi nella gestione dei sistemi I/O:
efficienza
il problema principale è causato dal fatto che la maggior parte dei dispositivi I/O sono molto lenti rispetto alla memoria principale. come gestirlo?
- un’opzione è la multiprogrammazione - la lentezza non impatta troppo sull’utilizzo del processore, che può eseguire altri processi mentre alcuni sono in attesa
- ma se ci sono molte operazioni I/O, l’I/O potrebbe comunque non stare al passo, e potrebbero non esserci più processi ready.
- si potrebbe pensare di portare altri processi sospesi in memoria principale, ma anche questa è un’operazione I/O.
- bisogna quindi cercare soluzioni software dedicate, a livello del Sistema Operativo, per l’I/O
generalità
i dispositivi I/O sono molto diversi tra di loro, ma sarebbe bene gestirli in modo uniforme.
- bisogna quindi nascondere la maggior parte dei dettagli dei dispositivi I/O nelle procedure di basso livello
- si offrono una serie di funzionalità (quasi) uguali per tutti:
read,write,lock,unlock,open,close, che sanno come gestire i diversi dispositivi
progettazione gerarchica
è una gerarchia simile a quella del progetto di un sistema operativo, che ci permette di nascondere dettagli specifici ai livelli più alti.
- ogni livello si basa sul fatto che il livello sottostante sa effettuare operazioni più primitive, fornendo servizi al livello superiore
- modificare l’implementazione di un livello non dovrebbe avere effetti sugli altri
per l’I/O, ci sono 3 macrotipi di gerarchie maggiormente usate:
1 - dispositivo locale
riguarda i dispositivi attaccati esternamente al computer (es. stampante, monitor, tastiera…)
i livelli sono:
- logical I/O - (che il Sistema Operativo offre ai processi utente) il dispositivo viene visto come una risorsa logica con operazioni standard (es.
open,read, etc) - device I/O - trasforma le richieste logiche (del livello superiore) in sequenze di comandi di I/O
- scheduling and control - esegue e controlla le sequenze di comandi, eventualmente gestendo l’accodamento per massimizzare l’efficienza
2 - dispositivo di comunicazione
riguarda i dispositivi che permettono la comunicazione (es. scheda ethernet, wifi…)
- organizzato come prima, ma al posto del logical I/O c’è un’architettura di comunicazione: il dispositivo viene visto come una risorsa logica composta a sua volta di una serie di livelli (es. TCP/IP)
3 - file system
riguarda i dispositivi di archiviazione (HDD, SSD, CD, DVD, USB, floppy disk…)
i livelli sono:
- directory management - operazioni utente sui file
- file system - sruttura logica ed operazioni (apri, chiudi, leggi, scrivi) (come vengono salvate e come sono mantenute le informazioni)
- organizzazione fisica - si occupa di allocare e deallocare spazio su disco
buffering dell’I/O
Per mitigare molte delle difficoltà associate alla gestione dell’I/O, è stata introdotta la tecnica dell’I/O buffering.
In particolare, i problemi principali sono:
- diversi dispositivi I/O hanno velocità diverse e
- sono ottimizzati per operazioni di certe dimensioni in base al loro tipo (per esempio, se un dispositico scrive 4mb alla volta, aspetterà di avere 4mb prima di scrivere)
la soluzione è creare un buffer - una zona di memoria principale che il Sistema Operativo dedica al mantenimento dei dati che saranno spostati. (quindi, si fanno trasferimenti di input in anticipo e di output in ritardo rispetto all’arrivo della richiesta)
senza buffer
Senza buffer, il Sistema Operativo accede al dispositivo nel momento in cui ne ha necessità:
buffer singolo
Il Sistema Operativo crea un buffer in memoria principale (nel kernel space, spesso statica, a volte dinamica). Quando arriva una richiesta di I/O, viene letta e scritta prima nel sistema operativo e, in un secondo momento, passata al processo utente
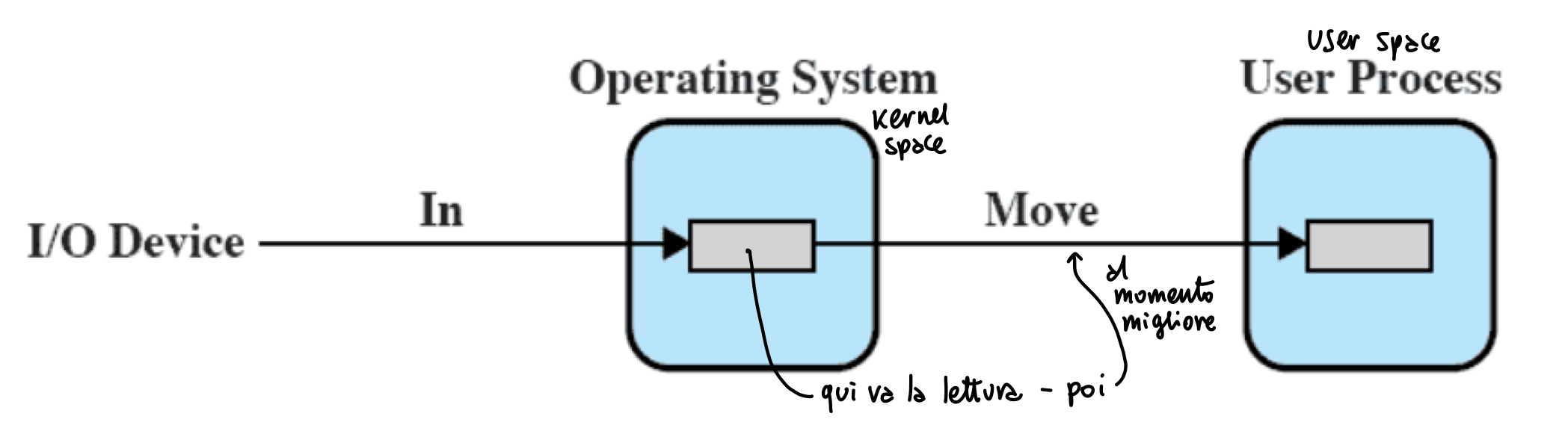
- lettura e scrittura sono separate e sequenziali
buffer singolo orientato ai blocchi
(riguarda i dispositivi orientati a blocchi, come i dischi)
I trasferimenti di input sono fatti al buffer in system memory - il blocco viene poi mandato nello spazio utente quando necessario. A questo punto, nonostante non sia arrivata nessun’altra richiesta di input, il blocco successivo viene comunque letto nel buffer (input anticipato, o read ahead)
- (si legge il blocco richiesto, ma anche intorno ad esso - per principio di località, probabilmente serviranno le informazioni vicine al blocco richiesto).
L’output, invece, viene posticipato (per efficienza - raccolgo quanti dati voglio e poi li do in output)
(per questo quando si fa debugging in C serve la syscall flush - un errore può verificarsi ben dopo un print, ma a causa dell’output posticipato non si ha niente a schermo, quindi si usa per svuotare il buffer).
buffer singolo orientato agli stream
(riguarda i dispostitivi stream-oriented, come i terminali)
Invece di un blocco, si bufferizza una linea di input o output. Invece, per i dispositivi in cui va gestito un singolo carattere premuto, viene bufferizzato un byte alla volta.
- in pratica, è un’istanza di un ben noto problema di concorrenza: producer/consumer
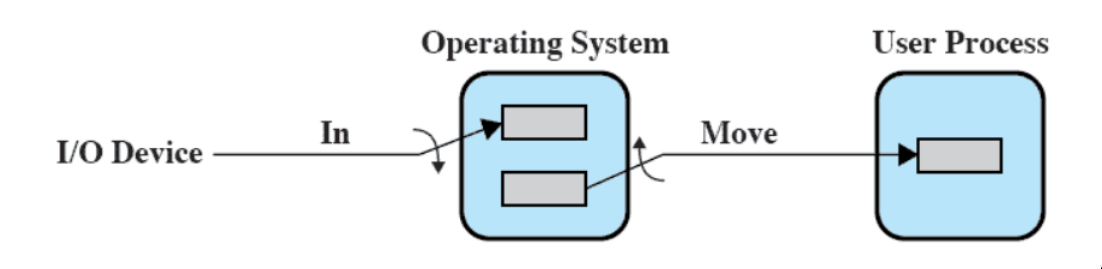
buffer doppio
Vista la piccola dimensione di un buffer, per poter gestire al meglio tutti i dispositivi I/O (senza avere il buffer sempre pieno) è utile usare un buffer multiplo.
Un processo può trasferire dati da o a uno dei buffer, mentre il Sistema Operativo svuota o riempie l’altro.
- lettura e scrittura nel buffer sono parallele: uno letto, l’altro scritto.
buffer circolare
Vengono utilizzati più di due buffer. (metodo utilizzato quando l’operazione di I/O deve tenere il passo del processo)
- questo è proprio il caso producer/consumer
buffer: pro e contro
Il buffering smussa i picchi di richieste di I/O (permettendo di non mantenere il processore idle), ma, se la domanda è molta, i buffer si riempiono e il vantaggio si perde.
- è utile soprattutto quando ci sono molti dispositivi I/O diversi tra di loro
overhead e buffer zero copy
Il buffering introduce overhead a causa della copia intermedia che viene fatta in Kernel Memory:
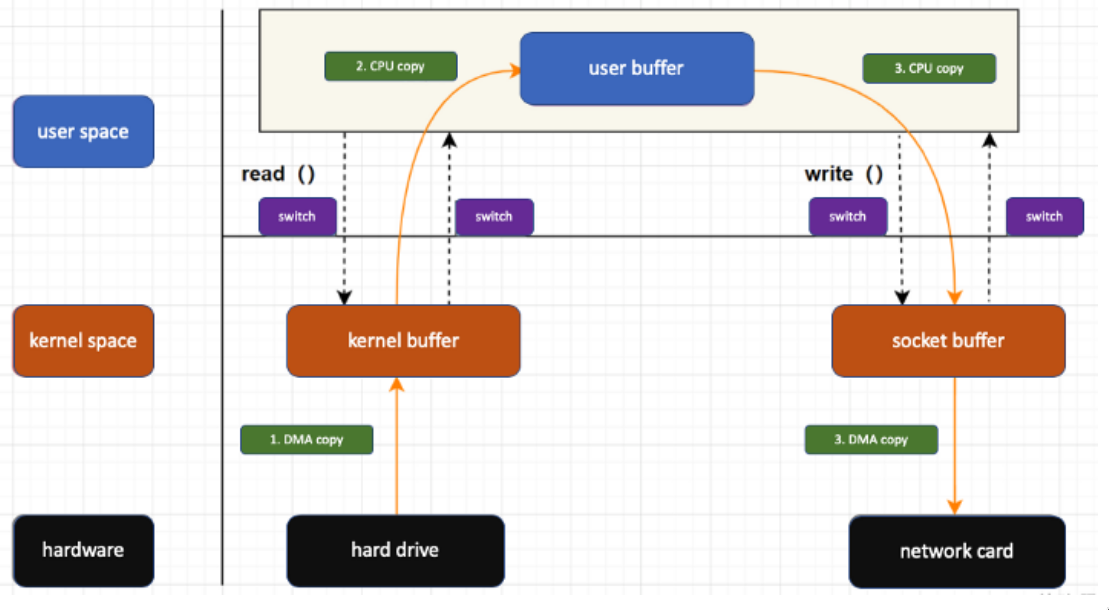
(i dati vengono prima copiati nel kernel buffer, poi nella zona utente, e solo poi nella sezione dell’I/O).
Per ovviare a questo problema, si utilizza l’architettura del buffer zero copy:
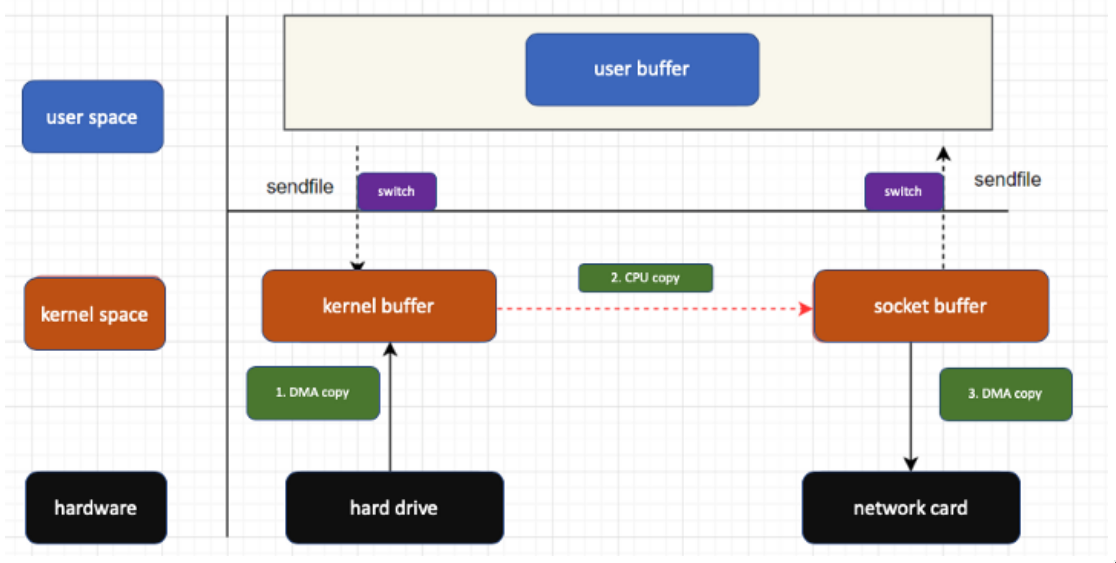
- evita inutili copie intermedie non passando per lo user space - fa direttamente un trasferimento da un Kernel Buffer ad un altro.
scheduling del disco
HDD vs SSD
Per gestire l’I/O, il Sistema Operativo deve essere il più efficiente possibile. Uno degli ambiti in cui i progettisti di sistemi operativi si sono dati più da fare è quello dei dispositivi di archiviazione di massa.
Quello che vedremo riguarda solo gli HDD (Hard Drive Disk) e non gli SSD (Solid State Disk).
il disco
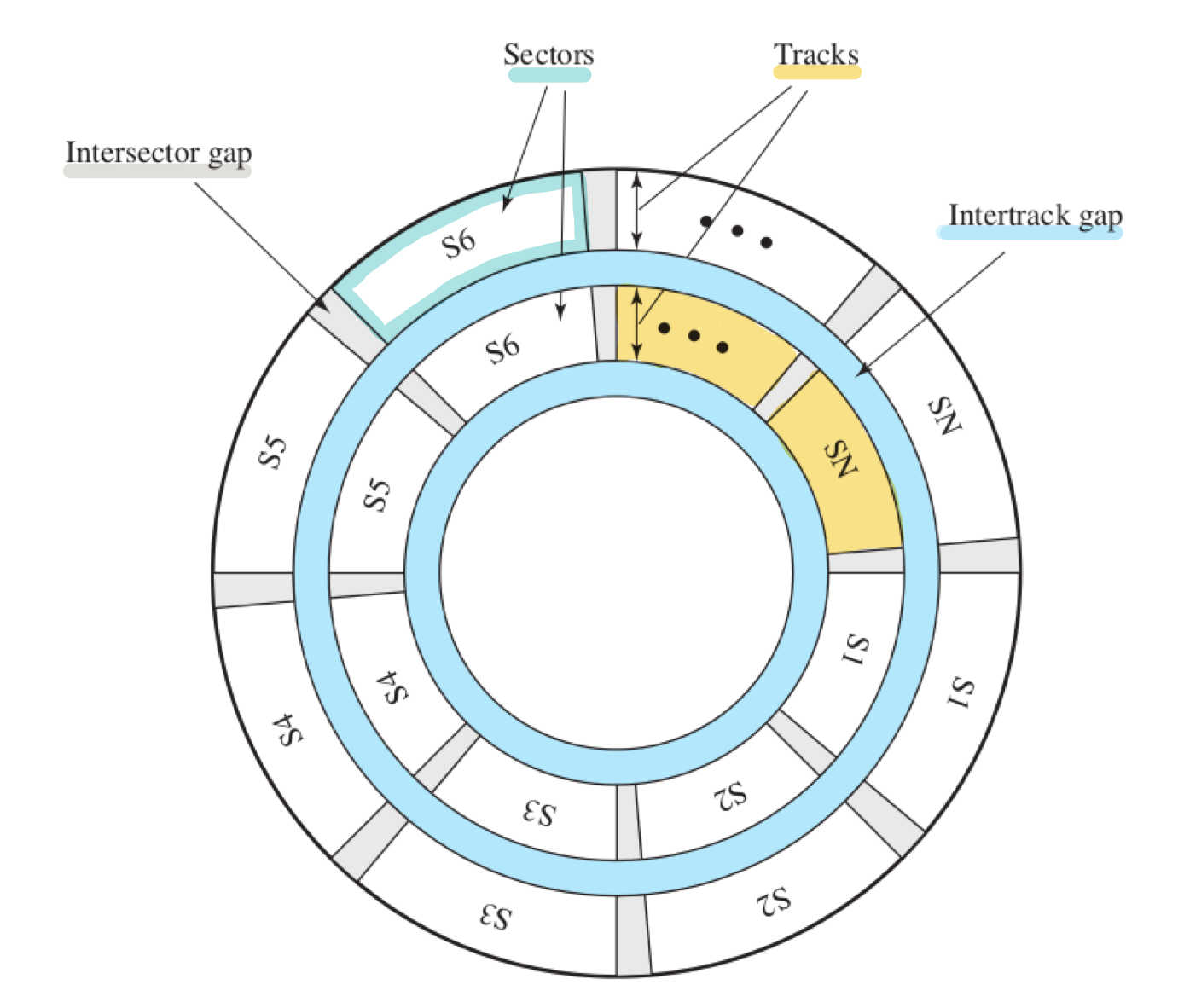
(una traccia è una corona circolare che diventa sempre più piccola avvicinandosi al centro; un settore è una parte di cerchio determinata da due raggi; l’intertrack gap separa due tracce, l’intersector gap separa due settori)
- i dati si trovano sulle tracce, su un certo numero di settori → per leggere e scrivere occorre sapere su che traccia e settore si trovano i dati
Per selezionare una traccia, bisogna
- spostare una testina (se ha testine mobili) (seek)
- selezionare una testina (se ha testine fisse)
Per selezionare un settore, bisogna aspettare che il disco ruoti (ruota a velocità costante). Se i dati sono tanti, potrebbero trovarsi su più settori o addirittura più tracce. (un settore misura in media 512 bytes).
prestazioni del disco
La linea temporale di un’operazione su disco può essere riassunta come segue:
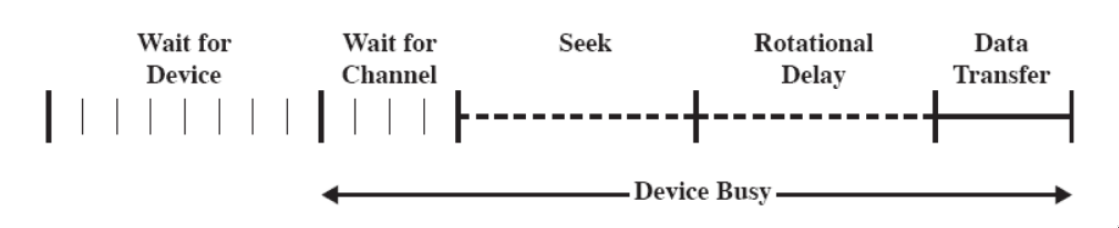
access time, che è la somma di:
- tempo di posizionamento (seek time): la testina si posiziona sulla traccia desiderata
- ritardo di rotazione (rotational delay): l’inizio del settore raggiunge la testina
tempo di trasferimento: tempo necessario a trasferire i dati che scorrono sotto la tesitna.
A parte rispetto a questi:
- wait for device: attesa che il dispositivo sia assegnato alla richiesta
- wait for channel: attesa che il sottodispositivo sia assegnato alla richiesta (se ci sono più dischi che condividono un solo canale di comunicazione)
politiche di scheduling per il disco
Come per la RAM, anche nel caso di un disco con testine mobili ci sono diverse vie per poter rendere più efficienti possibile le operazioni di read/write.
termine di confronto
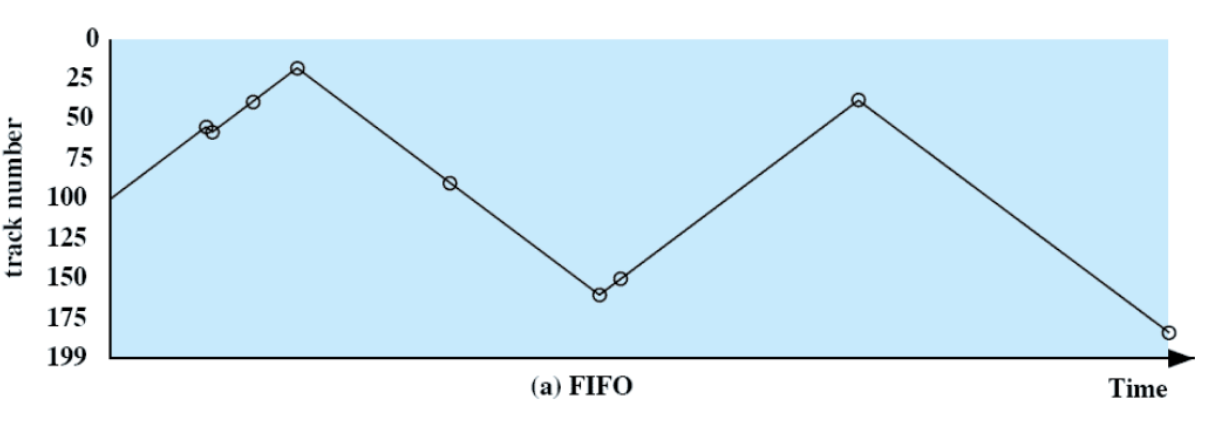
le politiche saranno confrontate su un esempio comune:
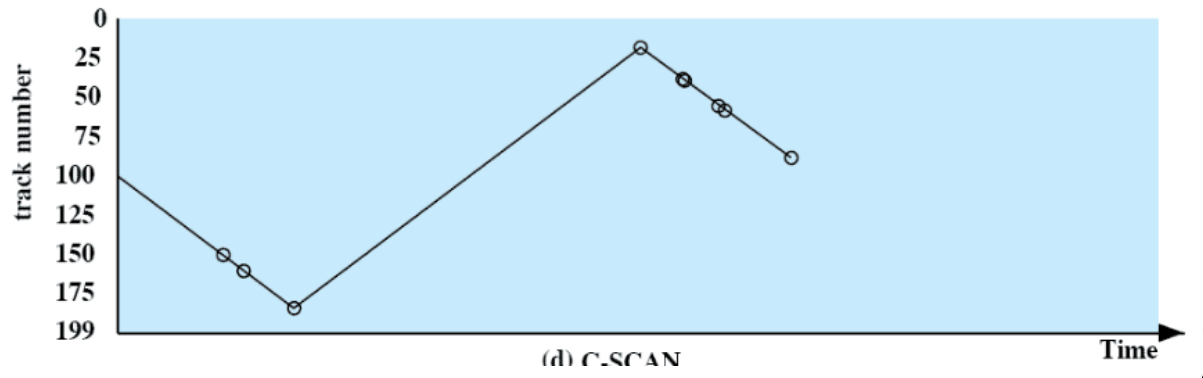
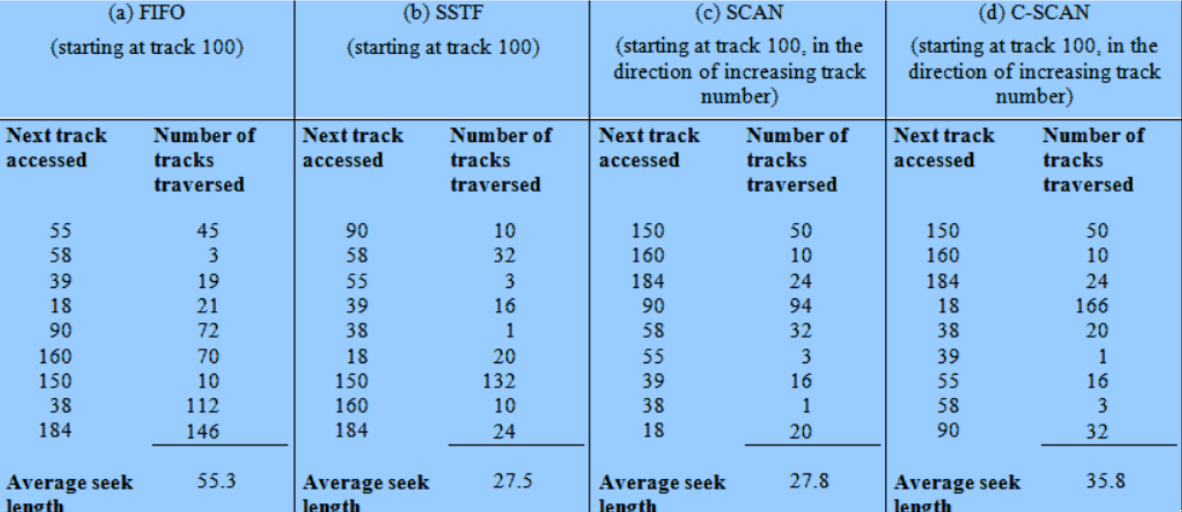
- all’inizio la testina si trova sulla traccia numero 100.
- ci sono 200 tracce
vengono richieste (in ordine): 55, 58, 39, 18, 90, 160, 150, 38, 184
viene considerato solo il seek time, confrontato con il random (scheduling peggiore)
FIFO
Le richieste sono servite in modo sequenziale
- è equo nei confronti dei processi
- se ci sono molti process in esecuzione, si comporta in modo simile al random
tempi
priorità
Per questa politica, l’obiettivo non è ottimizzare il disco.
- i processi batch corti potrebbero avere priorità più alta
- è desiderabile fornire un buon tempo di risposta ai processi interattivi, ma i processi più lunghi potrebbeo dover aspettare troppo
- non va bene per i DBMS
tempi
impossibile fare il grafico: bisognerebbe conoscere la priorità dei processi che hanno fatto le richieste
LIFO
- ottimo per i DBMS con transazioni (quindi per sequenze di istruzioni che non possono essere interrotte).
Il dispositivo è dato all’utente più recente - se un utente continua a fare richieste su disco, si potrebbe arrivare alla starvation.
È usata perché, se si tratta dello stesso utente, probabilmente sta accedendo sequenzialmente ad un file (ed è più efficiente mandarlo avanti).
tempi
impossibile fare il grafico: bisognerebbe sapere a che utente appartiene ogni richiesta
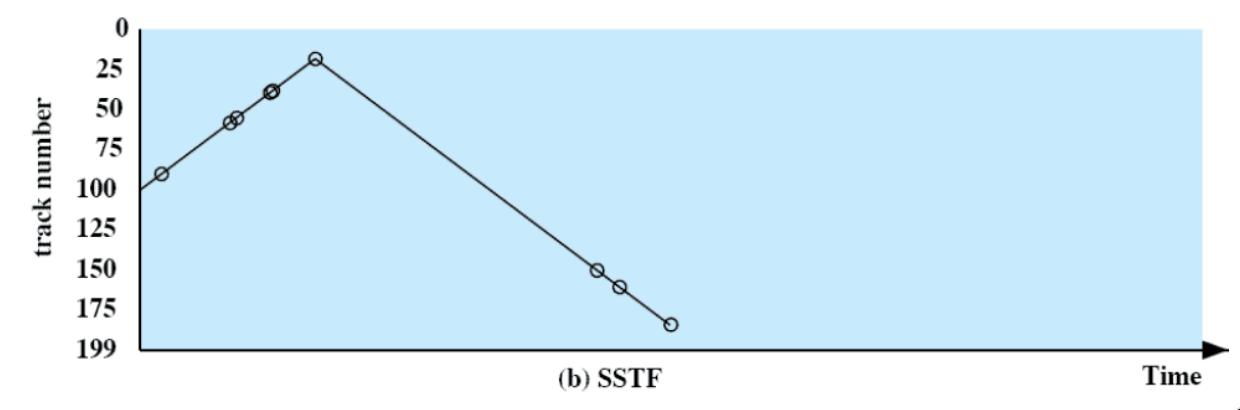
minimo tempo di servizio
[Da questa politica in poi, l’obiettivo è di minimizzare il seek time - e serve conoscere la posizione della testina]
Sceglie la richiesta che minimizza il movimento del braccio dalla posizione attuale (quindi il tempo di posizionamento minore).
- è possibile la starvation se arrivano continuamente richieste più vicine
tempi
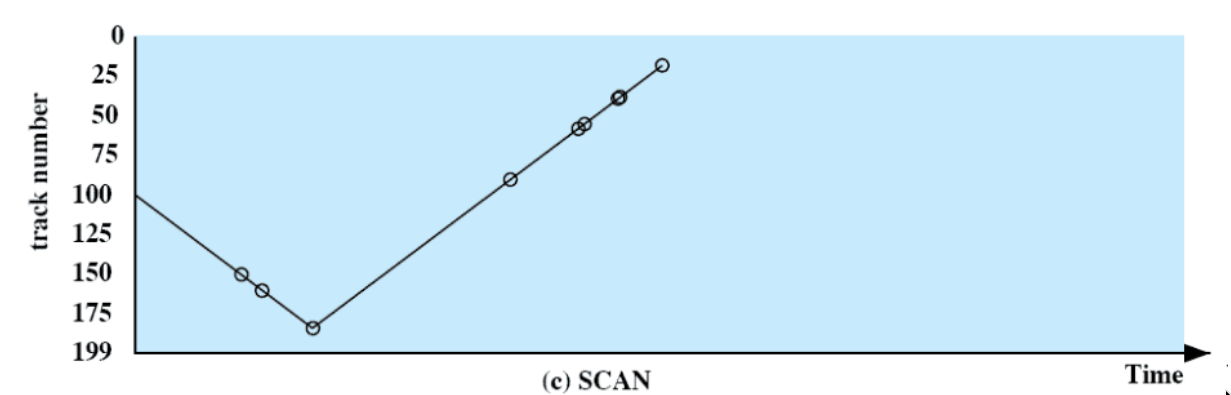
SCAN
Si scelgono le richieste in modo che il braccio si muova sempre in un verso per poi tornare indietro.
- niente starvation, ma è poco fair:
- favorisce le richieste ai bordi (attraversati due volte in poco tempo: in discesa e in salita)
- favorisce le richieste appena arrivate (se ben piazzate rispetto alla testina
tempi
C-SCAN
Come SCAN, ma risolve il problema del favoritismo verso le richieste ai bordi:
- nella “marcia indietro”, non si scelgono richieste
- quindi i bordi non sono più visitati due volte in poco tempo
tempi
FSCAN
Vengono utilizzate due code anziché una: e .
- Quando SCAN inizia, tutte le richieste sono nella coda , e è vuota.
- mentre SCAN serve tutta , ogni nuova richiesta è aggunta ad .
- quando SCAN finisce di servire , si scambiano ed .
Le richieste vecchie non vengono superate perché ogni richiesta nuova deve aspettare le precedenti.
N-step-SCAN
È una generalizzazione di FSCAN a code.
- si accodano le richieste nella coda i-esima fino a che non si riempie; poi si passa alla
- non si aggiungono mai richieste alla coda attualmente richiesta
Se è alto, le prestazioni sono come SCAN, ma più fair. Se , si usa il FIFO per fairness.
summa
confronto prestazionale
prospetto
SSD: cenni
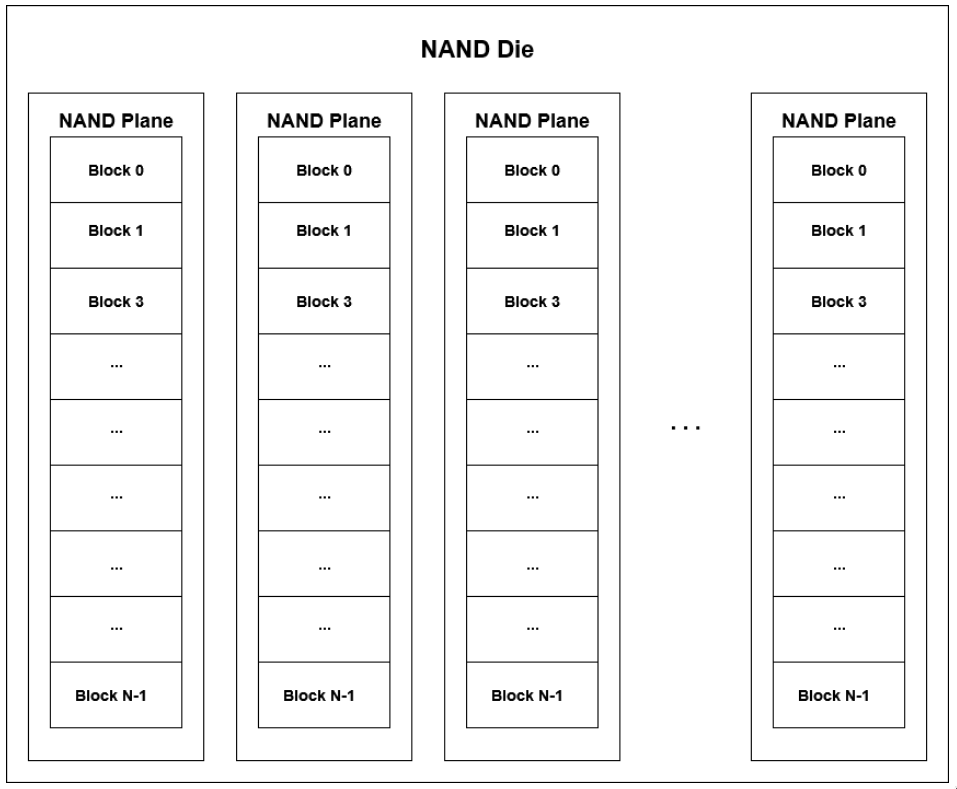
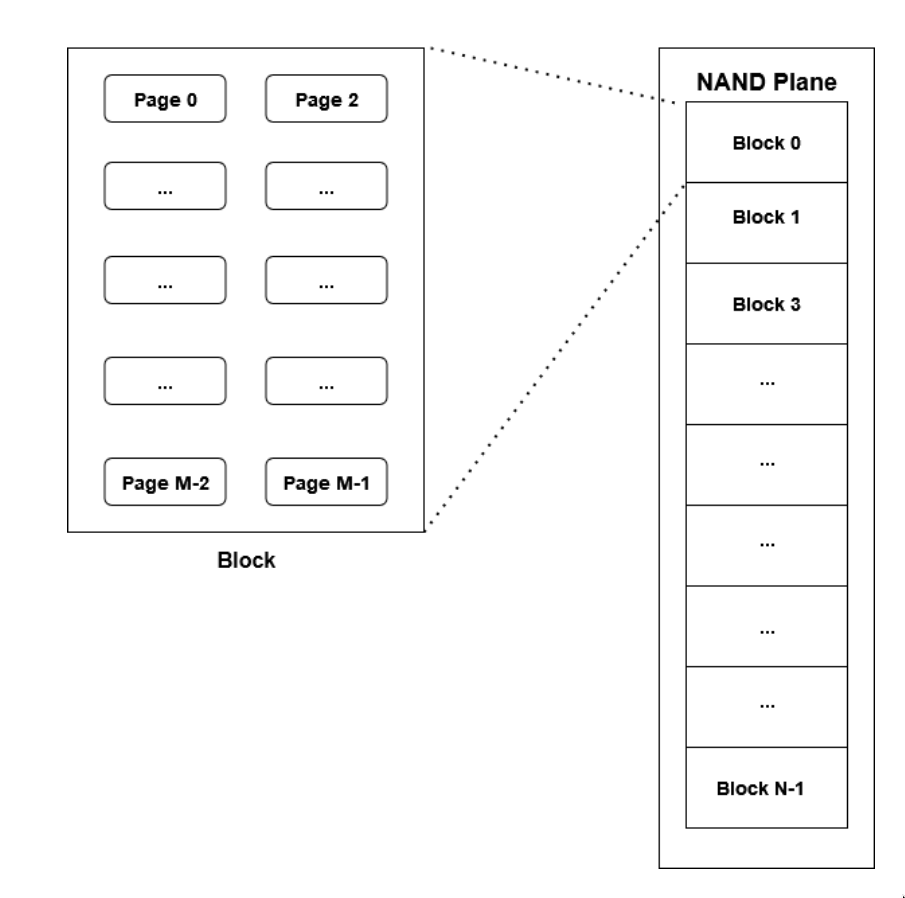
Ad alto livello, gli SSD (Solid State Drive) sono costituiti da stack (flash chips) di die (matrici), gestite da un controller.
- ciascun die ha un certo numero di planes, divise a loro volta in blocks.
- ciascun blocco è composto da un numero variabile di pages (~4KB)
- le pagine sono a loro volta composte da cells, che possono immagazzinare un solo bit
operazioni
le operazioni sugli SSD hanno granularità diversa in base al loro tipo:
- in lettura, l’unità di accesso minimo sono le pagine
- lo sono anche in scrittura, ma:
- una pagina può essere scritta solo se è vuota
- non è possibile la sovrascrittura
Sovrascrivere una pagina implica dover azzerare l’intero blocco che la contiene:
- si fa una copia dell’intero blocco
- si azzera il blocco
- si scrive la nuova pagina
- si copiano le pagine rimanenti dalla copia effettuata in precedenza
Gli SSD sono preferiti rispetto agli HDD, in quanto sono estremamente veloci
- nessun tempo richiesto per effettuare seek come negli HDD (quindi non ci si preoccupa di dove sono i dati)
- consentono l’accesso parallelo a diversi flash chip
Esistono anche algoritmi di accesso e file system progettati per massimizzare le performance degli SSD.
cache del disco
La cache del disco è un buffer in memoria principale usato esclusivamente per i settori del disco, che contiene una loro copia.
- quando si fa una richiesta di I/O, si vede prima se il settore che si cerca si trova nella cache.
- se non c’è, viene copiato al suo interno
Spesso viene chiamata page cache, ma non va confusa con quella spesso presente direttamente sui dischi, che è hardware.
Ci sono svariati modi per gestire la cache:
LRU
- se occorre rimpiazzare qualche settore nella cache si prende quello least recently used
- la cache viene puntata da uno “stack” di puntatori
- quello most recently used è in cima allo stack - ogni volta che un settore viene referenziato o copiato, il suo puntatore viene spostato in cima allo stack
- (non è proprio un vero stack, perché è acceduto solo usando push, pop e top)
LFU
- si rimpiazza il settore con meno referenze
- serve un contatore per ogni settore (incrementato ad ogni riferimento)
- sembra più sensato, ma la località potrebbe avere un effetto dannoso: se, per esempio, un settore venisse acceduto varie volte di fila per il principio di località e poi non più, avrebbe un valore alto senza essere effettivamente utile
sostituzione basata su frequenza
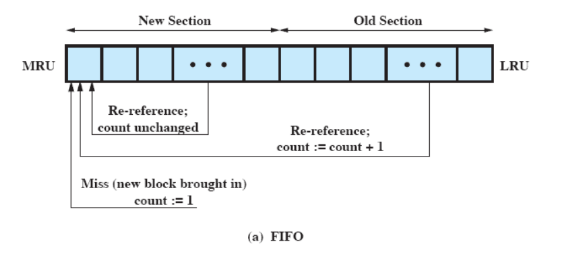
Utilizza uno stack di puntatori come l’LRU:
- quando un blocco viene referenziato, lo si sposta all’inizio dello stack
Ma lo stack è diviso in due: una parte nuova e una vecchia:
- un nuovo settore viene portato nella parte nuova
- ogni volta che si fa riferimento ad un settore nella cache, l’incremento avviene solo se si trova nella parte vecchia
- si passa dalla parte nuova a quella vecchia per scorrimento: quando un blocco vecchio viene riferito e “diventa nuovo”, spinge l’ultimo dei nuovi a diventare il primo dei vecchi
- per la sostituzione, si sceglie il blocco con contatore minimo nella parte vecchia (in caso di parità, quello più recente)
Non è ancora efficiente al massimo:
- se un blocco è appena arrivato nella parte vecchia, se non viene riferito presto, potrebbe essere sostituito anche se magari utile a breve
sostituzione basata su frequenza: 3 segmenti
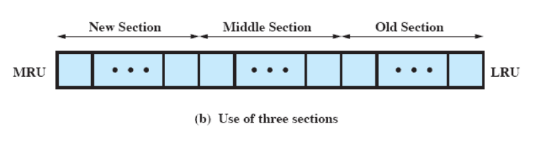
Invece di organizzare lo stack in due segmenti, lo si organizza in tre:
- nuovo
- unica parte in cui i contatori non vengono incrementati
- non c’è rimpiazzamento
- medio
- i contatori vengono incrementati
- non c’è rimpiazzamento
- vecchio
- i contatori vengono incrementati
- i blocchi sono eleggibili per rimpiazzamento
RAID
sta per Redundant Array of Indipendent Disks.
- in alcuni casi, si hanno a disposizione più dischi fisici, ed è possibile sia trattarli separatamente che come un unico disco
dischi multipli e RAID
In Linux, il trattamento separato di dischi viene chiamato Linux LVM (Logical Volume Manager). Permette di avere alcuni files memorizzati su un disco, e altri su un altro, con una gestione da parte del Kernel (dell’LVM nello specifico).
- l’utente può quindi non occuparsi di decidere dove salvare i file
- l’LVM serve ad evitare che, per esempio, una directory cresca fino a riempire il relativo disco mentre un’altra resta vuota.
Ma l’LVM va bene per pochi dischi, e se non si è interessati alla ridondanza (memorizzazione di un dato su diversi dispositivi). Con la ridondanza, se si rompesse un disco, si potrebbero recuperare alcuni dei dati persi da un altro disco.
Per risolvere questo problema esiste il RAID, che permette anche di velocizzare alcune operazioni.
(fun?) fact
esistono device composti da più dischi fisici gestiti da un RAID direttamente a livello di dispositivo - il Sistema Operativo fa solo read e write, il dispositivo stesso gestisce internamente il RAID
gerarchia dei dischi RAID
RAID 0 (nonredundant)
I dischi sono divisi in strip e ogni strip contiene un certo numero di settori.
- un insieme di strip su vari dischi (una riga) si chiama stripe
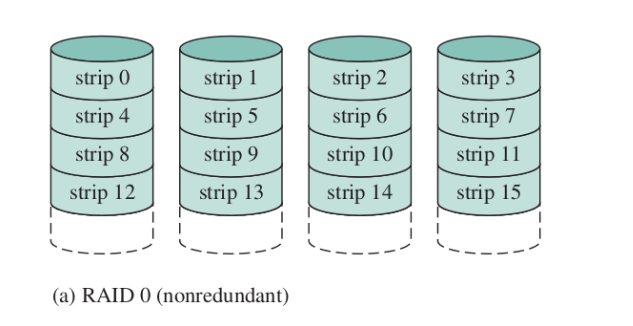
Lo scopo del RAID 0 è la parallelizzazione - uno stesso file viene diviso su un’intera stripe (su vari dischi). Non c’è ridondanza, il file system è dato dall’unione di tutti i dischi.
RAID 1 (mirrored)
Come RAID0, ma ogni dato viene duplicato. Fisicamente ci sono dischi, ma con capacità di memorizzazione .
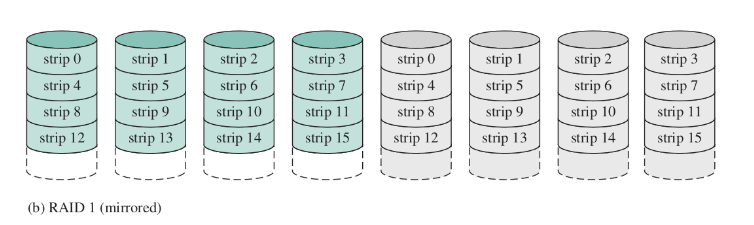
Se si rompe un disco, si recuperano tutti i dati.
- se se ne rompono due, dipende da quali si sono rotti
RAID 2 (redundancy through Hamming code)
hamming code
Il codice di Hamming aggiunge tre bit di controllo addizionali ad ogni quattro bit di messaggio. L’algoritmo di Hamming (7,4) può correggere ogni errore di singolo bit, oppure rivelare tutti gli errori di singolo bit e gli errori su due bit, ma senza poterli correggere.
(non usato)
La ridondanza non viene fatta attraverso una semplice copia, ma tramite opportuni codici. Serve per proteggersi nei casi (rari) in cui gli errori non sono il fallimento di un intero disco, ma magari il flip di qualche singolo bit.
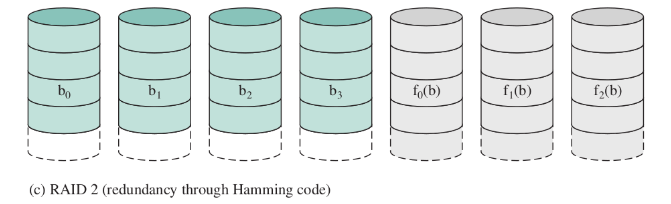
Non ci sono più dischi di overhead, ma tanti quanti servono per memorizzare il codice di Hamming (proporzionale al logaritmo della capacità dei dischi).
RAID 3 (bit-interleaved parity)
(non usato)
Memorizza, per ogni bit, la parità dei bit con la stessa posizione (pari: 1, dispari: 0).
- nonostante la sua semplicità, resta possibile recuperare i dati se fallisce un unico disco
- irrecuperabile se fallisce il disco di parità
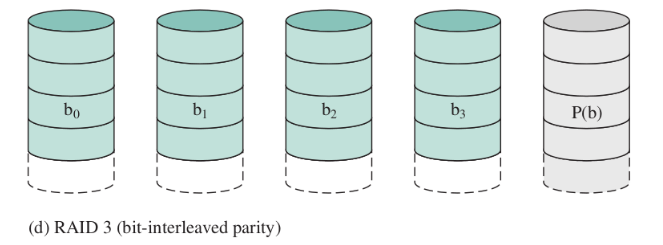
RAID 4 (block-level parity)
(non usato)
Come RAID3, ma ogni strip è un “blocco” (quindi si fa la parità di ogni strip).
- recuperabile nel caso di fallimento di un unico disco
- migliore parallelismo di RAID3, ma più complicato gestire piccole scritture
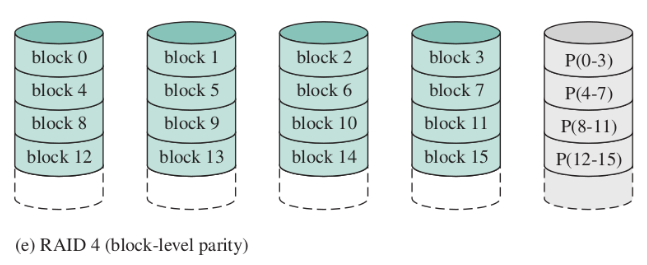
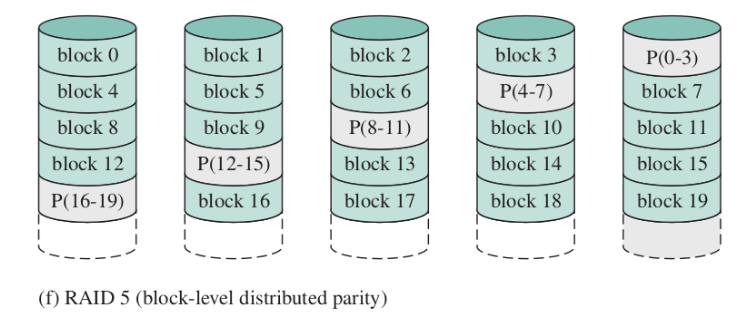
RAID 5 (block-level distributed parity)
Come RAID4, ma le informazioni di parità non si trovano su un unico disco. Evita il bottleneck del disco di parità (prima, ogni scrittura aveva effetto sul disco di parità - qui non c’è un disco privilegiato)
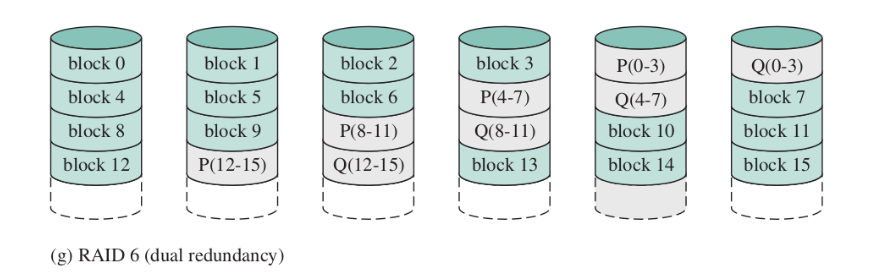
RAID 6 (dual redundancy)
Come RAID5, ma con due dischi di parità indipendenti.
- permette d recuperare anche due fallimenti di disco, ma con una penalità del 30% in più rispetto a RAID5 sulla scrittura (si equivalgono invece per la lettura)
riassunto
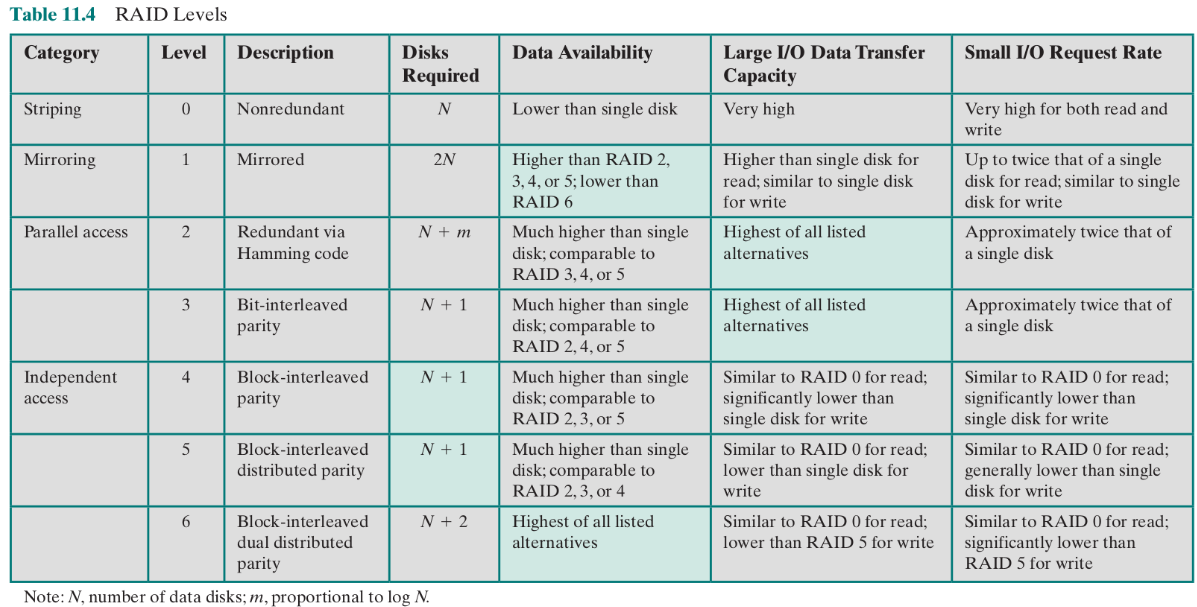
Parallel access - se faccio un’operazione sul RAID, tutti i dischi effettuano in sincrono quell’operazione
Indipendent - un’operazione sul RAID è un’operazione su un sottoinsieme dei suoi dischi (permette il completamento in parallelo di richieste I/O distinte)
Data availability - capacità di recupero in caso di fallimento
Small I/O request rate - velocità nel rispondere a piccole richieste di I/O
I/O in Linux
Linux utilizza un’unica page cache per tutti i trasferimenti tra disco e memoria, compresi quelli dovuti alla gestione della memoria virtuale (sorta di page buffering).
Ci sono due vantaggi:
- scritture condensate
- sfruttando la località dei riferimenti, si risparmiano accessi a disco
Quando scrive su disco?
- è rimasta poca memoria: una parte della page cache è ridestinata all’uso diretto dei processi
- quando l’età delle pagine “sporche” supera una certa soglia
Non c’è una replacement policy separata: è la stessa per il rimpiazzo delle pagine
- la page cache è paginata, le pagine sono rimpiazzate con l’algoritmo visto per la gestione della memoria