From 1986 to 2003, the performance of microprocessors has increased, on average, by 50% per year. But since 2003, the increase has slowed down, getting to about 4% a year. That’s why, instead of trying to have more powerful monolithic processors, we are putting multiple processors on a single integrated circuit. Traditionally, performance increases are caused by increase in the density of transistors, but there are physical limits that make parallel computing necessary (eg. smaller transistors = more power consumption, increased heat).
writing parallel programs
There are two types of parallelism:
- task parallelism ⟶ tasks are partitioned amongst cores (an example would be the “temporal parallelism” seen in the CPU pipeline)
- data parallelism ⟶ data is partitioned, and different cores carry out similar operations to solve different problems on their part of the data
example
If i need to grade 300 exams, each with 15 questions, and i have 15 assistants:
- if i make each assistant grade 100 exams, i’m doing data parallelism
- if i’m giving each assistent a subset of questions to grade, i’m doing task parallelism
If each core were to work independently, it would be similar to writing a serial program - we need cores to coordinate, for different reasons:
- communication (ex. one core sends its partial sum to another one)
- load balancing (the work needs to be shared evenly, so that no core is too heavily loaded)
- synchronisation (since each core works at its own pace, we need to make sure that no core gets too far ahead)
To write parallel programs, we’ll use four different extensions of the C APIs:
- Message-Passing Interface (MPI)
- Posix Threads (Pthreads)
- OpenMP
- CUDA
types of parallel systems
There are different types of parallel systems
memory-wise
- shared memory ⟶ the cores can share access to the computer’s memory; they are coordinated by having them examine and update shared memory locations
- distributed memory ⟶ each core has its own private memory; cores must communicate explicitly by sending messages across a network
instruction-wise
- multiple-instruction multiple-data (MIMD) ⟶ each core has its own control units and can work independently
- single-instruction multiple-data (SIMD) ⟶ cores share the control units (they all have to execute the same instruction)
| shared memory | distributed memory | |
|---|---|---|
| SIMD | CUDA | |
| MIMD | pthreads, openMD, CUDA | MPI |
task-wise
There isn’t a complete agreement on the definition, but
- concurrent task parallelism ⟶ multipple tasks can be in progress at any time
- concurrent programs can be serial
- parallel ⟶ multiple tasks cooperate closely to solve a problem (tightly coupled - cores share memory or are connected via a fast network)
- distributed ⟶ a program might need to cooperate with others to solve a problem (more loosely coupled - eg services connected through the internet)
(parallel and distributed are both subsets of concurrent)
hardware
We need to know which hardware we’re working with, in order to optimise for it specifically.
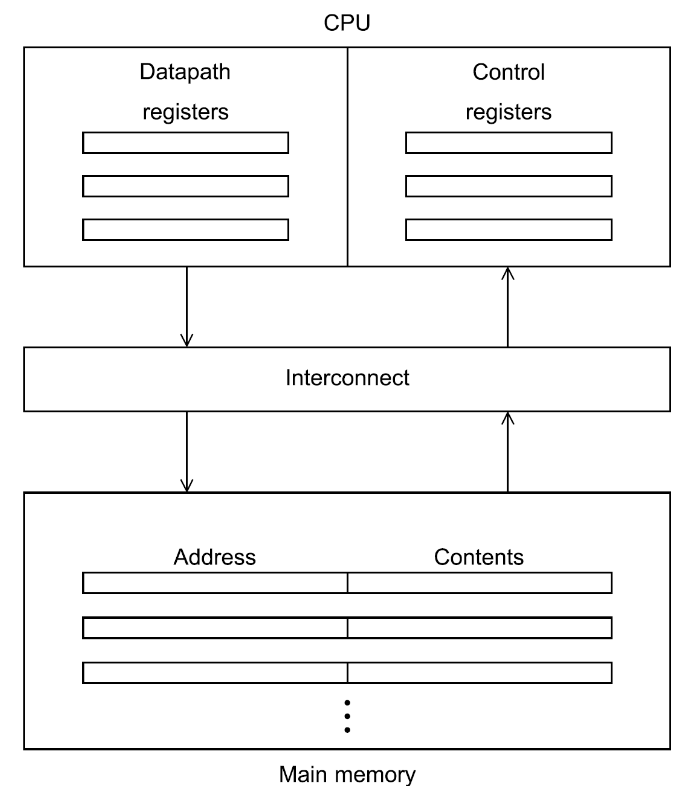
von neumann architecture
- main memory ⟶ collection of locations; each location has an address used to access its content (data/instruction)
- CPU ⟶ comprised of the many units, like the Control Unit, the registers (which store the state of the executing program) e.g. the Program Counter, and the datapath (which executes the instructions)
- interconnect ⟶ used to transfer data between the CPU and the memory; traditionally a bus, but it can be much more complex
- the bottleneck caused by the transfer of data from memory to the registers is known as von neumann bottleneck
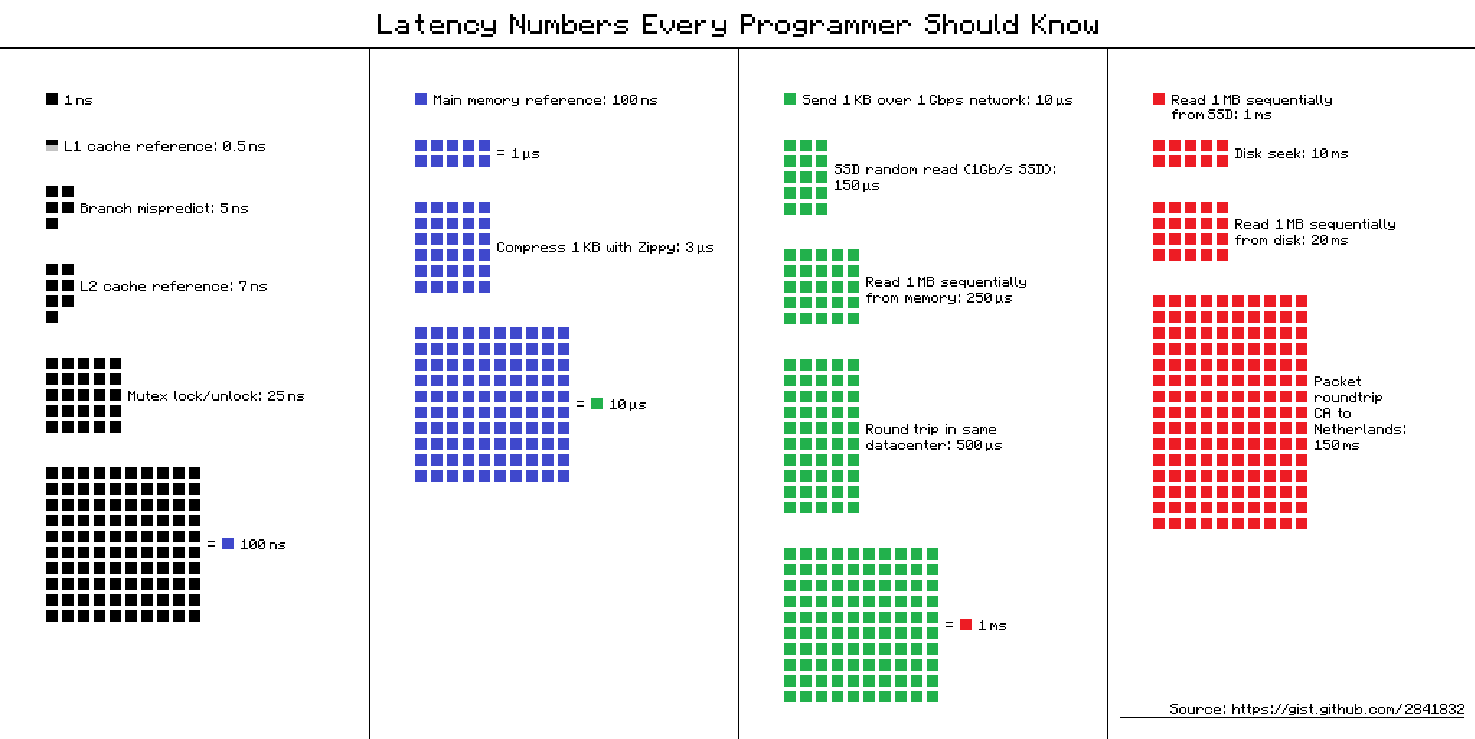
"how much does that cost?"